Memory consistency requires that a load uop obtains the value that was most recently stored into the target memory location. Therefore, the memory order buffer (MOB) must determine whether the load overlaps any earlier store uop in program order. Both the load buffer and store buffer are circular and each load is tagged with the ID of the youngest store that precedes the load in program order (the allocator knows the ID of the last store it has allocated at the time it has to allocate the load). This enables the MOB to correctly determine which stores precede which loads.
Starting with Intel Core microarchitecture and the Goldmont microarchitecture, the scheduler includes a speculative memory disambiguation (SMD) logic that uses the IP of the load to decide whether to allow the load to be dispatched out-of-order with respect to the STA uops of all earlier stores. This is similar to how branch prediction uses the IP of the current 16 byte chunk being fetched to predict control flow, except in this case the IP is used for memory disambiguation. If there are no STAs waiting in the RS or if all STAs can be dispatched in the same cycle as the load uop, the SMD result is ignored and the load is dispatched. Otherwise, if SMD decides to block the load, the scheduler dispatches the load only when all earlier STAs have been dispatched or will be dispatched in the same cycle as the load. For some load uops, the SMD always blocks the load in the RS.
When a load uop is dispatched to one of the load AGU ports, the effective address, i.e., linear address, of the load is calculated using the specified segment base, base register operand, index register operand, scale, and displacement. At the same time, there can be stores in the store buffer. The linear address of the load is compared against the linear addresses of all earlier stores whose STA uops were executed (i.e., the linear address of the store is available). It might be necessary to compare also the physical addresses, but the physical address of the load is still not available at this point (this situation is referred to as an invalid physical address in the patent). To minimize the observable latency of the load, the MOB performs a quick comparison using only the least significant 12 bits of the linear addresses of the load and each earlier store. For more information on this comparison, refer to L1 memory bandwidth: 50% drop in efficiency using addresses which differ by 4096+64 bytes (but masked uops are not discussed there). This logic is called the loose net, and it constitutes the other part of the speculative memory disambiguation mechanism. The loose net is supported on all Intel microarchitectures since the Pentium Pro (including the in-order Bonnell), but the exact implementation has changed because the size of data a single load or store uop can operate on has increased and because of the introduction of masked memory uops starting with the Pentium II. In parallel to the loose net operation, the linear address of the load is sent to the TLB to obtain the corresponding physical address and perform the necessary page attribute checks and also the segment checks are performed.
If the load does not overlap with any earlier store whose address was known at the time the load was dispatched according to the loose net result, a load request is sent to the L1D. We already know from the RIDL vulnerabilities that some data might be forwarded to the MOB even without having a valid physical address from the TLB, but only if the load causes a fault or assist. On a first-level TLB miss, the load is blocked in the load buffer so that it doesn't continue with its L1D access just yet. Later when the requested page entry reaches the first-level TLB, the MOB is informed about the address of that virtual page, which in turn checks all of the loads and stores that are blocked on that page and unblocks them by replaying the uops as per the availability of TLB ports.
I think the loose net takes only one cycle to compare the address of a given load with any number of stores in the store buffer and determine the youngest overlapping store that is older than the load, if any found. The process of looking up the first-level TLB and providing the physical address to the L1D on a hit should take only one cycle. This is how a best-case load-to-use latency of 4 cycles can be attained (which also requires (1) correct speculation of the physical page address, (2) the base+disp addressing mode without an index or with a zero index, and (3) a segment base address of zero, otherwise there is a penalty of at least one cycle). See the discussion in the comments for more on this.
Note that if the load uop missed in the loose net, it can be concluded that the load does not overlap any previous store, but only if the STAs of all earlier uops were already executed at the time the load uop is dispatched. It's impossible for two linear addresses whose least significant 12 bits are different to overlap.
If the loose net result indicates that the load overlaps with an earlier store, the MOB does two things in parallel. One of them is that the memory disambiguation process continues using the fine net (i.e., full linear address comparison). If the load missed in the fine net, the physical addresses are compared when available. Otherwise, if the load hit in the fine net, the load and the store overlap. Note the x86 ISA requires using a fully serializing instruction after making changes to a paging structure. So there is no need to compare the physical addresses in the fine net hit case. In addition to all of that, whenever a new STA uop is dispatched, this whole process is repeated, but this time with all loads in the load buffer. The results of all of these comparisons are combined and when the load has been checked against all earlier stores, the end result determines how to correctly execute the load uop.
In parallel, the MOB speculates that the store that hit in the loose net with the load has the value that should be forwarded to the load. If the load and store are to the same virtual page, then the speculation is correct. If the load and store are to different virtual pages but the virtual pages are mapped to the same physical page,the speculation is also correct. Otherwise, if the load and store are to different physical pages, the MOB has messed up, resulting in a situation called 4K aliasing. But wait, let's roll back a little.
It may not be possible to forward the store data to the load. For example, if the load is not fully contained in the store, then it has to wait until the store is committed and then the load is allowed to proceed and get the data from the cache. Also what if the STD uop of the store has not executed yet (e.g., it depends on a long latency uop)? Normally, the data is only forwarded from the store buffer when the requirements for store forwarding are met. However, the MSBDS vulnerability shows that this is not the case always. In particular, when the load causes a fault or assist, the store buffer may forward the data to the load without doing any of the store forwarding checks. From the Intel article on MDS:
It is possible that a store does not overwrite the entire data field
within the store buffer due to either the store being a smaller size
than the store buffer width, or not yet having executed the data
portion of the store. These cases can lead to data being forwarded
that contains data from older stores.
Clearly, the data may be forwarded even if the STD uop has not executed yet. But where will data come from then? Well, the data field of a store buffer entry is not cleared when deallocated. The size of the data field is equal to the width of a store uop, which can be determined by measuring the number of store uops it takes to execute the widest available store instruction (e.g., from a XMM, YMM, or ZMM register). This seems to be 32 bytes on Haswell and 64 bytes on Skyake-SP. Each data field of a store buffer entry is that big. Since it is never cleared, it may hold some random combination of data from stores that happened to be allocated in that store buffer entry. When the load hits in the loose net and will cause a fault/assist, the data of width specified by the load will be forwarded to the load from the store buffer without even checking for the execution of the STD or the width of the store. That's how the load can get data from one or more stores that may even have been committed a billion instructions ago. Similar to MLBDS, some parts of the data or the whole data that gets forwarded may be stale (i.e, doesn't belong to the store that occupies the entry).
These details were actually only provided by Intel, not the Fallout paper. In the paper, the authors perform an experiment (Section 4) on systems with KPTI disabled (I'll explain why), but they don't exploit the Meltdown vulnerability. Here is how the experiment works:
- The attacker performs a sequence of stores, all of which miss in the cache hierarchy. The number of stores is at least as large the number of store buffer entries.
- A kernel module is invoked, which performs a sequence of stores, each is to a different offset in a different kernel page. The values stored are known. The number of stores is varied between 1-50 as shown in Figure 5. After that, the kernel module returns to the attacker.
- The attacker performs a sequence of loads to user pages (different from the kernel pages) to the same offsets. Each user page is allocated only in the virtual address space and has access permission revoked (by calling
mprotect(...,PROT_NONE), marking it as User and Not Present). Table 1 shows that a Supervisor page that is not Present doesn't work. The number of loads is the same as the number of stores performed by the kernel module. The loaded values are then leaked using a traditional FLUSH+RELOAD attack.
The first step attempts to keep the store buffer as much occupied as possible to delay committing the stores from the kernel module. Remember that false store forwarding only works on occupied store buffer entries. The first step works because the stores have to commit in order. In the third step, all that matters is to get loose net hits. Note how in this experiment, the authors were not thinking of leaking any stale data, they just wanted to get the data from the kernel stores that are hopefully is still in the store buffer. When changing the current privilege level, all instructions are retired before executing any instructions in the new privilege level. The stores can retire quickly, even before the RFO request completes, but they still have to wait in the store buffer to commit in order. It was thought that having stores from different privilege levels in the store buffer in this way is not a problem. However, when the attackers begins executing the loads, if the store that is to the same offset as the load currently being dispatched is still in the store buffer, a loose net hit occurs when the (not stale) data is speculatively forwarded. You know the rest.
When KPTI is enabled, most kernel pages live in a different virtual address space than the user pages. Thus, when returning from the kernel module, the kernel has to switch address spaces by writing a value into the CR3 register. But this is a serializing operation, which means that it will stall the pipeline until all (kernel) stores are committed. That's why the authors needed KPTI to be disabled for their experiment to work (i.e., the store buffer would be empty). Unfortunately, since Coffee Lake R has a hardware mitigation for Meltdown, the Linux kernel, by default, disables KPTI on this processor. That's why the authors say that the hardware mitigation has made the processor more vulnerable.
What's described in the Intel article (but not the paper) shows that MSBDS is much more dangerous than that: A faulting/assisting load can leak also stale data from the store buffer. The Intel article also shows that MSBDS works across sibling logical cores: when a logical core goes into a sleep state, its store buffer entries that have been statically allocated for it may become usable by the other logical core. Later if the logical core becomes active again, the store buffer is statically partitioned, which may enable that core to leak stale data from its entries that was written by the other core.
All of this shows that enabling KPTI is not enough to mitigate MSBDS. Also the mitigation recommended in the paper in Section 6 (flushing the store buffer using MFENCE when crossing a security boundary) is also not sufficient. Proper MDS mitigations are discussed here.
I don't know how can the authors in Section 3.2 conclude from the following quote from the Intel patent:
if there is a hit at operation 302 [partial match using page offsets]
and the physical address of the load or the store operations is not
valid, the physical address check at operation 310 [full physical
address match] may be considered as a hit
the following:
That is, if address translation of a load μOP fails and the 12 least
significant bits of the load address match those of a prior store, the
processor assumes that the physical addresses of the load and the
store match and forwards the previously stored value to the load μOP.
The whole patent doesn't mention comparing 12 bits and doesn't say that the load has to fault in order for the false store forwarding to occur. In addition, the conclusion itself is not correct because the 12 least significant bits don't have to match exactly and the load doesn't have to fault (but the attack only works if it faults).
MSBDS is different from Meltdown in that the attacker leaks data from kernel pages that live in a separate virtual address space. MSBDS is different from SSB in that the attacker mistrains the SMD so that it dispatches the load before all STAs that precede the load are dispatched. In this way, there is a less chance that the load will not hit in the loose net, which makes the MOB to issue the load to the L1D cache and get a potentially a value that is not the most recent value according to program order. SMD can be disabled by setting IA32_SPEC_CTRL[2] to 1. When the SMD is disabled, the scheduler handles load uops as in the Pentium Pro.
It's worth noting briefly that there are load and store uops that work differently from what I have described above. Examples include memory uops from MFENCE, SFENCE, and CLFLUSH. But they are not relevant here.
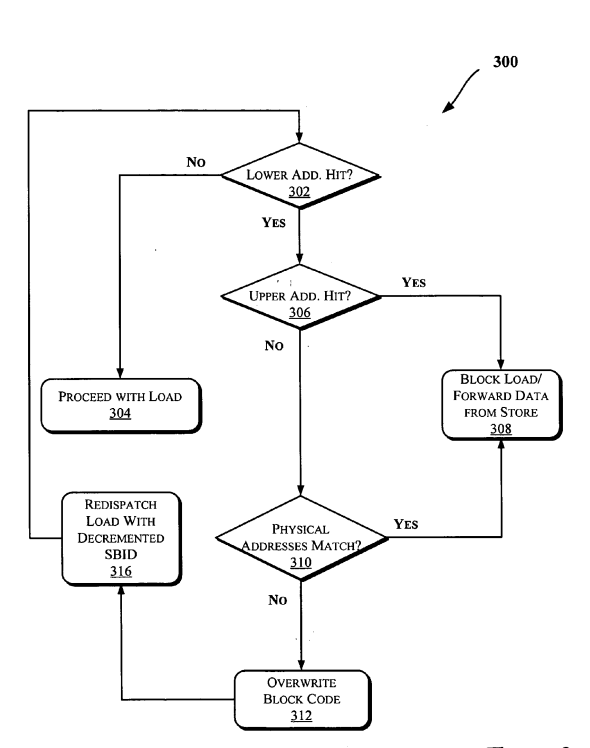
invlpgis a fully serializing instruction, so incorrect forwarding cannot occur because the mapping cannot be changed for the same virtual address without committing all previous stores. Regarding para 0026, the last sentence looks important because it describes 4K aliasing, which is what the authors seem to call WTF. I've not read the paper, but it looks like WTF is an exploitation of 4K aliasing, which makes perfect sense. I'm planning to read the paper and maybe post an answer after that just to be sure. – Kinesics