I want to achieve the maximum bandwidth of the following operations with Intel processors.
for(int i=0; i<n; i++) z[i] = x[i] + y[i]; //n=2048
where x, y, and z are float arrays. I am doing this on Haswell, Ivy Bridge , and Westmere systems.
I originally allocated the memory like this
char *a = (char*)_mm_malloc(sizeof(float)*n, 64);
char *b = (char*)_mm_malloc(sizeof(float)*n, 64);
char *c = (char*)_mm_malloc(sizeof(float)*n, 64);
float *x = (float*)a; float *y = (float*)b; float *z = (float*)c;
When I did this I got about 50% of the peak bandwidth I expected for each system.
The peak values is calculated as frequency * average bytes/clock_cycle. The average bytes/clock cycle for each system is:
Core2: two 16 byte reads one 16 byte write per 2 clock cycles -> 24 bytes/clock cycle
SB/IB: two 32 byte reads and one 32 byte write per 2 clock cycles -> 48 bytes/clock cycle
Haswell: two 32 byte reads and one 32 byte write per clock cycle -> 96 bytes/clock cycle
This means that e.g. on Haswell I I only observe 48 bytes/clock cycle (could be two reads in one clock cycle and one write the next clock cycle).
I printed out the difference in the address of b-a and c-b and each are 8256 bytes. The value 8256 is 8192+64. So they are each larger than the array size (8192 bytes) by one cache-line.
On a whim I tried allocating the memory like this.
const int k = 0;
char *mem = (char*)_mm_malloc(1<<18,4096);
char *a = mem;
char *b = a+n*sizeof(float)+k*64;
char *c = b+n*sizeof(float)+k*64;
float *x = (float*)a; float *y = (float*)b; float *z = (float*)c;
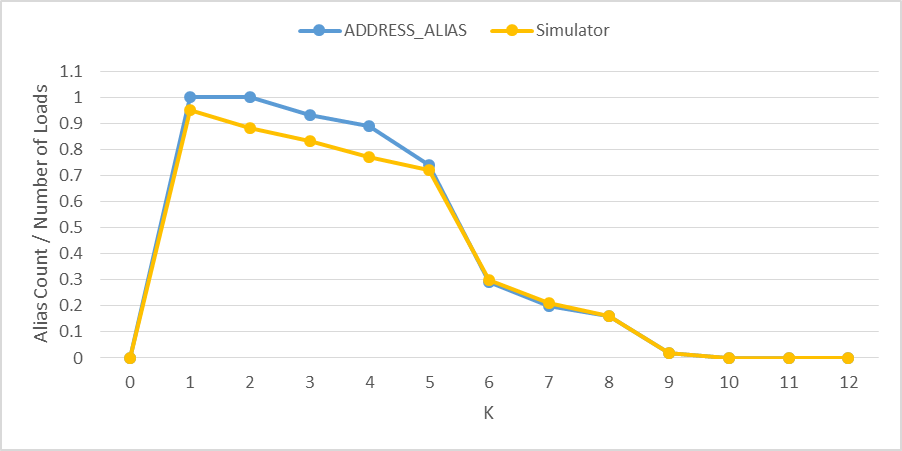
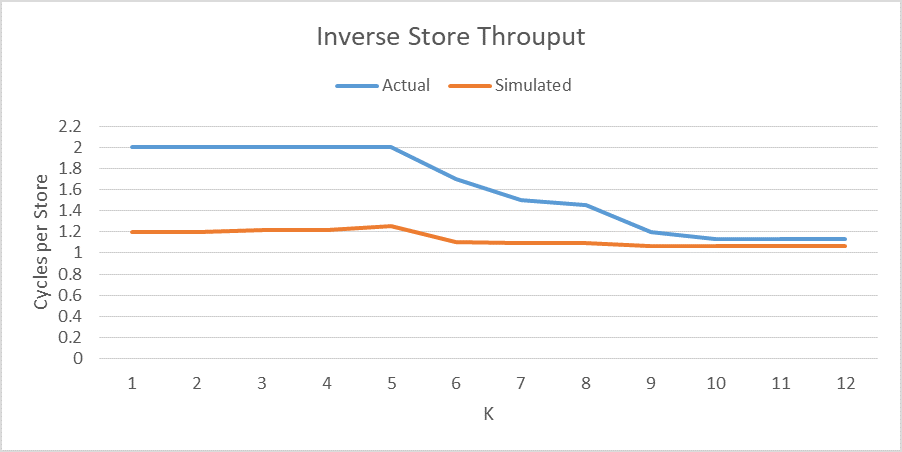
This nearly doubled my peak bandwidth so that I now get around 90% of the peak bandwidth. However, when I tried k=1 it dropped back to 50%. I have tried other values of k and found that e.g. k=2, k=33, k=65 only gets 50% of the peak but e.g. k=10, k=32, k=63 gave the full speed. I don't understand this.
In Agner Fog's micrarchitecture manual he says that there is a false dependency with memory address with the same set and offset
It is not possible to read and write simultaneously from addresses that are spaced by a multiple of 4 Kbytes.
But that's exactly where I see the biggest benefit! When k=0 the memory address differ by exactly 2*4096 bytes. Agner also talks about Cache bank conflicts. But Haswell and Westmere are not suppose to have these bank conflicts so that should not explain what I am observing. What's going on!?
I understand that the OoO execution decides which address to read and write so even if the arrays' memory addresses differ by exactly 4096 bytes that does not necessarily mean the processor reads e.g. &x[0] and writes &z[0] at the same time but then why would being off by a single cache line cause it to choke?
Edit: Based on Evgeny Kluev's answer I now believe this is what Agner Fog calls a "bogus store forwarding stall". In his manual under the Pentium Pro, II and II he writes:
Interestingly, you can get a get a bogus store forwarding stall when writing and reading completely different addresses if they happen to have the same set-value in different cache banks:
; Example 5.28. Bogus store-to-load forwarding stall
mov byte ptr [esi], al
mov ebx, dword ptr [esi+4092]
; No stall
mov ecx, dword ptr [esi+4096]
; Bogus stall
Edit: Here is table of the efficiencies on each system for k=0 and k=1.
k=0 k=1
Westmere: 99% 66%
Ivy Bridge: 98% 44%
Haswell: 90% 49%
I think I can explain these numbers if I assume that for k=1 that writes and reads cannot happen in the same clock cycle.
cycle Westmere Ivy Bridge Haswell
1 read 16 read 16 read 16 read 32 read 32
2 write 16 read 16 read 16 write 32
3 write 16
4 write 16
k=1/k=0 peak 16/24=66% 24/48=50% 48/96=50%
This theory works out pretty well. Ivy bridge is a bit lower than I would expect but Ivy Bridge suffers from bank cache conflicts where the others don't so that may be another effect to consider.
Below is working code to test this yourself. On a system without AVX compile with g++ -O3 sum.cpp otherwise compile with g++ -O3 -mavx sum.cpp. Try varying the value k.
//sum.cpp
#include <x86intrin.h>
#include <stdio.h>
#include <string.h>
#include <time.h>
#define TIMER_TYPE CLOCK_REALTIME
double time_diff(timespec start, timespec end)
{
timespec temp;
if ((end.tv_nsec-start.tv_nsec)<0) {
temp.tv_sec = end.tv_sec-start.tv_sec-1;
temp.tv_nsec = 1000000000+end.tv_nsec-start.tv_nsec;
} else {
temp.tv_sec = end.tv_sec-start.tv_sec;
temp.tv_nsec = end.tv_nsec-start.tv_nsec;
}
return (double)temp.tv_sec + (double)temp.tv_nsec*1E-9;
}
void sum(float * __restrict x, float * __restrict y, float * __restrict z, const int n) {
#if defined(__GNUC__)
x = (float*)__builtin_assume_aligned (x, 64);
y = (float*)__builtin_assume_aligned (y, 64);
z = (float*)__builtin_assume_aligned (z, 64);
#endif
for(int i=0; i<n; i++) {
z[i] = x[i] + y[i];
}
}
#if (defined(__AVX__))
void sum_avx(float *x, float *y, float *z, const int n) {
float *x1 = x;
float *y1 = y;
float *z1 = z;
for(int i=0; i<n/64; i++) { //unroll eight times
_mm256_store_ps(z1+64*i+ 0,_mm256_add_ps(_mm256_load_ps(x1+64*i+ 0), _mm256_load_ps(y1+64*i+ 0)));
_mm256_store_ps(z1+64*i+ 8,_mm256_add_ps(_mm256_load_ps(x1+64*i+ 8), _mm256_load_ps(y1+64*i+ 8)));
_mm256_store_ps(z1+64*i+ 16,_mm256_add_ps(_mm256_load_ps(x1+64*i+16), _mm256_load_ps(y1+64*i+ 16)));
_mm256_store_ps(z1+64*i+ 24,_mm256_add_ps(_mm256_load_ps(x1+64*i+24), _mm256_load_ps(y1+64*i+ 24)));
_mm256_store_ps(z1+64*i+ 32,_mm256_add_ps(_mm256_load_ps(x1+64*i+32), _mm256_load_ps(y1+64*i+ 32)));
_mm256_store_ps(z1+64*i+ 40,_mm256_add_ps(_mm256_load_ps(x1+64*i+40), _mm256_load_ps(y1+64*i+ 40)));
_mm256_store_ps(z1+64*i+ 48,_mm256_add_ps(_mm256_load_ps(x1+64*i+48), _mm256_load_ps(y1+64*i+ 48)));
_mm256_store_ps(z1+64*i+ 56,_mm256_add_ps(_mm256_load_ps(x1+64*i+56), _mm256_load_ps(y1+64*i+ 56)));
}
}
#else
void sum_sse(float *x, float *y, float *z, const int n) {
float *x1 = x;
float *y1 = y;
float *z1 = z;
for(int i=0; i<n/32; i++) { //unroll eight times
_mm_store_ps(z1+32*i+ 0,_mm_add_ps(_mm_load_ps(x1+32*i+ 0), _mm_load_ps(y1+32*i+ 0)));
_mm_store_ps(z1+32*i+ 4,_mm_add_ps(_mm_load_ps(x1+32*i+ 4), _mm_load_ps(y1+32*i+ 4)));
_mm_store_ps(z1+32*i+ 8,_mm_add_ps(_mm_load_ps(x1+32*i+ 8), _mm_load_ps(y1+32*i+ 8)));
_mm_store_ps(z1+32*i+ 12,_mm_add_ps(_mm_load_ps(x1+32*i+12), _mm_load_ps(y1+32*i+ 12)));
_mm_store_ps(z1+32*i+ 16,_mm_add_ps(_mm_load_ps(x1+32*i+16), _mm_load_ps(y1+32*i+ 16)));
_mm_store_ps(z1+32*i+ 20,_mm_add_ps(_mm_load_ps(x1+32*i+20), _mm_load_ps(y1+32*i+ 20)));
_mm_store_ps(z1+32*i+ 24,_mm_add_ps(_mm_load_ps(x1+32*i+24), _mm_load_ps(y1+32*i+ 24)));
_mm_store_ps(z1+32*i+ 28,_mm_add_ps(_mm_load_ps(x1+32*i+28), _mm_load_ps(y1+32*i+ 28)));
}
}
#endif
int main () {
const int n = 2048;
const int k = 0;
float *z2 = (float*)_mm_malloc(sizeof(float)*n, 64);
char *mem = (char*)_mm_malloc(1<<18,4096);
char *a = mem;
char *b = a+n*sizeof(float)+k*64;
char *c = b+n*sizeof(float)+k*64;
float *x = (float*)a;
float *y = (float*)b;
float *z = (float*)c;
printf("x %p, y %p, z %p, y-x %d, z-y %d\n", a, b, c, b-a, c-b);
for(int i=0; i<n; i++) {
x[i] = (1.0f*i+1.0f);
y[i] = (1.0f*i+1.0f);
z[i] = 0;
}
int repeat = 1000000;
timespec time1, time2;
sum(x,y,z,n);
#if (defined(__AVX__))
sum_avx(x,y,z2,n);
#else
sum_sse(x,y,z2,n);
#endif
printf("error: %d\n", memcmp(z,z2,sizeof(float)*n));
while(1) {
clock_gettime(TIMER_TYPE, &time1);
#if (defined(__AVX__))
for(int r=0; r<repeat; r++) sum_avx(x,y,z,n);
#else
for(int r=0; r<repeat; r++) sum_sse(x,y,z,n);
#endif
clock_gettime(TIMER_TYPE, &time2);
double dtime = time_diff(time1,time2);
double peak = 1.3*96; //haswell @1.3GHz
//double peak = 3.6*48; //Ivy Bridge @ 3.6Ghz
//double peak = 2.4*24; // Westmere @ 2.4GHz
double rate = 3.0*1E-9*sizeof(float)*n*repeat/dtime;
printf("dtime %f, %f GB/s, peak, %f, efficiency %f%%\n", dtime, rate, peak, 100*rate/peak);
}
}
k=lthat a read and write cannot happen in the same clock cycle. I'm not sure exactly why but I think it's related to the 4KB false dependency. – Karen