tl;dr: I have two functionally equivalent C codes that I compile with Clang (the fact that it's C code doesn't matter much; only the assembly is interesting I think), and IACA tells me that one should be faster, but I don't understand why, and my benchmarks show the same performance for the two codes.
I have the following C code (ignore #include "iacaMarks.h", IACA_START, IACA_END for now):
ref.c:
#include "iacaMarks.h"
#include <x86intrin.h>
#define AND(a,b) _mm_and_si128(a,b)
#define OR(a,b) _mm_or_si128(a,b)
#define XOR(a,b) _mm_xor_si128(a,b)
#define NOT(a) _mm_andnot_si128(a,_mm_set1_epi32(-1))
void sbox_ref (__m128i r0,__m128i r1,__m128i r2,__m128i r3,
__m128i* r5,__m128i* r6,__m128i* r7,__m128i* r8) {
__m128i r4;
IACA_START
r3 = XOR(r3,r0);
r4 = r1;
r1 = AND(r1,r3);
r4 = XOR(r4,r2);
r1 = XOR(r1,r0);
r0 = OR(r0,r3);
r0 = XOR(r0,r4);
r4 = XOR(r4,r3);
r3 = XOR(r3,r2);
r2 = OR(r2,r1);
r2 = XOR(r2,r4);
r4 = NOT(r4);
r4 = OR(r4,r1);
r1 = XOR(r1,r3);
r1 = XOR(r1,r4);
r3 = OR(r3,r0);
r1 = XOR(r1,r3);
r4 = XOR(r4,r3);
*r5 = r1;
*r6 = r4;
*r7 = r2;
*r8 = r0;
IACA_END
}
I was wondering if I could optimize it by manually rescheduling a few instructions (I am well aware that the C compiler should produce an efficient scheduling, but my experiments have shown that it's not always the case). At some point, I tried the following code (it's the same as above, except that no temporary variables are used to store the results of the XORs that are later assigned to *r5 and *r6):
resched.c:
#include "iacaMarks.h"
#include <x86intrin.h>
#define AND(a,b) _mm_and_si128(a,b)
#define OR(a,b) _mm_or_si128(a,b)
#define XOR(a,b) _mm_xor_si128(a,b)
#define NOT(a) _mm_andnot_si128(a,_mm_set1_epi32(-1))
void sbox_resched (__m128i r0,__m128i r1,__m128i r2,__m128i r3,
__m128i* r5,__m128i* r6,__m128i* r7,__m128i* r8) {
__m128i r4;
IACA_START
r3 = XOR(r3,r0);
r4 = r1;
r1 = AND(r1,r3);
r4 = XOR(r4,r2);
r1 = XOR(r1,r0);
r0 = OR(r0,r3);
r0 = XOR(r0,r4);
r4 = XOR(r4,r3);
r3 = XOR(r3,r2);
r2 = OR(r2,r1);
r2 = XOR(r2,r4);
r4 = NOT(r4);
r4 = OR(r4,r1);
r1 = XOR(r1,r3);
r1 = XOR(r1,r4);
r3 = OR(r3,r0);
*r7 = r2;
*r8 = r0;
*r5 = XOR(r1,r3); // This two lines are different
*r6 = XOR(r4,r3); // (no more temporary variables)
IACA_END
}
I'm compiling these codes using Clang 5.0.0 targeting my i5-6500 (Skylake), with the flags -O3 -march=native (I'm omitting the assembly code produced, as they can be found in the IACA outputs bellow, but if you'd prefer to have them directly here, ask me and I'll add them). I benchmarked those two codes and didn't find any performance difference between them. Out of curiosity, I ran IACA on them, and I was surprised to see that it said that the first version should take 6 cycles to run, and the second version 7 cycles.
Here are the output produce by IACA:
For the first version:
dada@dada-ubuntu ~/perf % clang -O3 -march=native -c ref.c && ./iaca -arch SKL ref.o
Intel(R) Architecture Code Analyzer Version - v3.0-28-g1ba2cbb build date: 2017-10-23;16:42:45
Analyzed File - ref_iaca.o
Binary Format - 64Bit
Architecture - SKL
Analysis Type - Throughput
Throughput Analysis Report
--------------------------
Block Throughput: 6.00 Cycles Throughput Bottleneck: FrontEnd
Loop Count: 23
Port Binding In Cycles Per Iteration:
--------------------------------------------------------------------------------------------------
| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 |
--------------------------------------------------------------------------------------------------
| Cycles | 6.0 0.0 | 6.0 | 1.3 0.0 | 1.4 0.0 | 4.0 | 6.0 | 0.0 | 1.4 |
--------------------------------------------------------------------------------------------------
DV - Divider pipe (on port 0)
D - Data fetch pipe (on ports 2 and 3)
F - Macro Fusion with the previous instruction occurred
* - instruction micro-ops not bound to a port
^ - Micro Fusion occurred
# - ESP Tracking sync uop was issued
@ - SSE instruction followed an AVX256/AVX512 instruction, dozens of cycles penalty is expected
X - instruction not supported, was not accounted in Analysis
| Num Of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 |
-----------------------------------------------------------------------------------------
| 1 | 1.0 | | | | | | | | vpxor xmm4, xmm3, xmm0
| 1 | | 1.0 | | | | | | | vpand xmm5, xmm4, xmm1
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm2, xmm1
| 1 | 1.0 | | | | | | | | vpxor xmm5, xmm5, xmm0
| 1 | | 1.0 | | | | | | | vpor xmm0, xmm3, xmm0
| 1 | | | | | | 1.0 | | | vpxor xmm0, xmm0, xmm1
| 1 | 1.0 | | | | | | | | vpxor xmm1, xmm4, xmm1
| 1 | | 1.0 | | | | | | | vpxor xmm3, xmm4, xmm2
| 1 | | | | | | 1.0 | | | vpor xmm2, xmm5, xmm2
| 1 | 1.0 | | | | | | | | vpxor xmm2, xmm2, xmm1
| 1 | | 1.0 | | | | | | | vpcmpeqd xmm4, xmm4, xmm4
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm1, xmm4
| 1 | 1.0 | | | | | | | | vpor xmm1, xmm5, xmm1
| 1 | | 1.0 | | | | | | | vpxor xmm4, xmm5, xmm3
| 1 | | | | | | 1.0 | | | vpor xmm3, xmm0, xmm3
| 1 | 1.0 | | | | | | | | vpxor xmm4, xmm4, xmm3
| 1 | | 1.0 | | | | | | | vpxor xmm4, xmm4, xmm1
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm1, xmm3
| 2^ | | | 0.3 | 0.3 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rdi], xmm4
| 2^ | | | 0.3 | 0.3 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rsi], xmm1
| 2^ | | | 0.3 | 0.3 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rdx], xmm2
| 2^ | | | 0.3 | 0.3 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rcx], xmm0
Total Num Of Uops: 26
For the second version:
dada@dada-ubuntu ~/perf % clang -O3 -march=native -c resched.c && ./iaca -arch SKL resched.o
Intel(R) Architecture Code Analyzer Version - v3.0-28-g1ba2cbb build date: 2017-10-23;16:42:45
Analyzed File - resched_iaca.o
Binary Format - 64Bit
Architecture - SKL
Analysis Type - Throughput
Throughput Analysis Report
--------------------------
Block Throughput: 7.00 Cycles Throughput Bottleneck: Backend
Loop Count: 22
Port Binding In Cycles Per Iteration:
--------------------------------------------------------------------------------------------------
| Port | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 |
--------------------------------------------------------------------------------------------------
| Cycles | 6.0 0.0 | 6.0 | 1.3 0.0 | 1.4 0.0 | 4.0 | 6.0 | 0.0 | 1.3 |
--------------------------------------------------------------------------------------------------
DV - Divider pipe (on port 0)
D - Data fetch pipe (on ports 2 and 3)
F - Macro Fusion with the previous instruction occurred
* - instruction micro-ops not bound to a port
^ - Micro Fusion occurred
# - ESP Tracking sync uop was issued
@ - SSE instruction followed an AVX256/AVX512 instruction, dozens of cycles penalty is expected
X - instruction not supported, was not accounted in Analysis
| Num Of | Ports pressure in cycles | |
| Uops | 0 - DV | 1 | 2 - D | 3 - D | 4 | 5 | 6 | 7 |
-----------------------------------------------------------------------------------------
| 1 | 1.0 | | | | | | | | vpxor xmm4, xmm3, xmm0
| 1 | | 1.0 | | | | | | | vpand xmm5, xmm4, xmm1
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm2, xmm1
| 1 | 1.0 | | | | | | | | vpxor xmm5, xmm5, xmm0
| 1 | | 1.0 | | | | | | | vpor xmm0, xmm3, xmm0
| 1 | | | | | | 1.0 | | | vpxor xmm0, xmm0, xmm1
| 1 | 1.0 | | | | | | | | vpxor xmm1, xmm4, xmm1
| 1 | | 1.0 | | | | | | | vpxor xmm3, xmm4, xmm2
| 1 | | | | | | 1.0 | | | vpor xmm2, xmm5, xmm2
| 1 | 1.0 | | | | | | | | vpxor xmm2, xmm2, xmm1
| 1 | | 1.0 | | | | | | | vpcmpeqd xmm4, xmm4, xmm4
| 1 | | | | | | 1.0 | | | vpxor xmm1, xmm1, xmm4
| 1 | 1.0 | | | | | | | | vpor xmm1, xmm5, xmm1
| 1 | | 1.0 | | | | | | | vpxor xmm4, xmm5, xmm3
| 1 | | | | | | 1.0 | | | vpor xmm3, xmm0, xmm3
| 2^ | | | 0.3 | 0.4 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rdx], xmm2
| 2^ | | | 0.3 | 0.3 | 1.0 | | | 0.4 | vmovdqa xmmword ptr [rcx], xmm0
| 1 | 1.0 | | | | | | | | vpxor xmm0, xmm4, xmm3
| 1 | | 1.0 | | | | | | | vpxor xmm0, xmm0, xmm1
| 2^ | | | 0.4 | 0.3 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rdi], xmm0
| 1 | | | | | | 1.0 | | | vpxor xmm0, xmm1, xmm3
| 2^ | | | 0.3 | 0.4 | 1.0 | | | 0.3 | vmovdqa xmmword ptr [rsi], xmm0
Total Num Of Uops: 26
Analysis Notes:
Backend allocation was stalled due to unavailable allocation resources.
As you can see, on the second version, IACA says that the bottleneck is the backend and that "Backend allocation was stalled due to unavailable allocation resources".
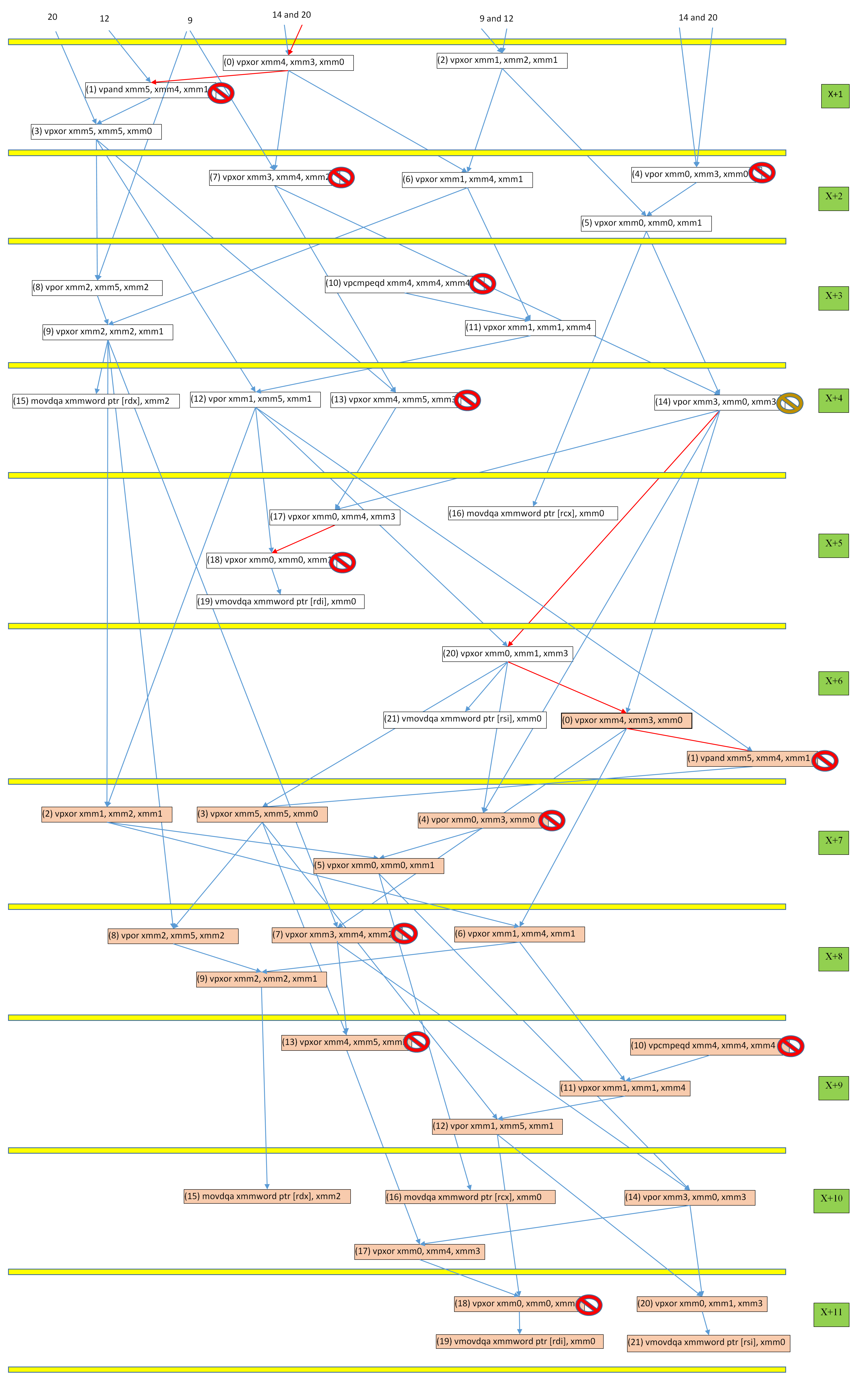
Both assembly codes contain the same instructions, and the only differences are the scheduling of the last 7 instructions, as well as the registers they use.
The only thing I can think of that would explain why the second code is slower is the fact that it writes twice xmm0 in the last 4 instructions, thus introducing a dependency. But since those writes are independent, I would expect the CPU to use different physical registers for them. However, I can't really prove that theory. Also, if using twice xmm0 like that were an issue, I would expect Clang to use a different register for one of the instructions (in particular since the register pressure here is low).
My question: is the second code supposed to be slower (based on the assembly code), and why?
Edit: IACA traces:
First version: https://pastebin.com/qGXHVW6a
Second version: https://pastebin.com/dbBNWsc2
Note: the C codes are implementations of Serpent cipher's first S-box, computed by Osvik here.
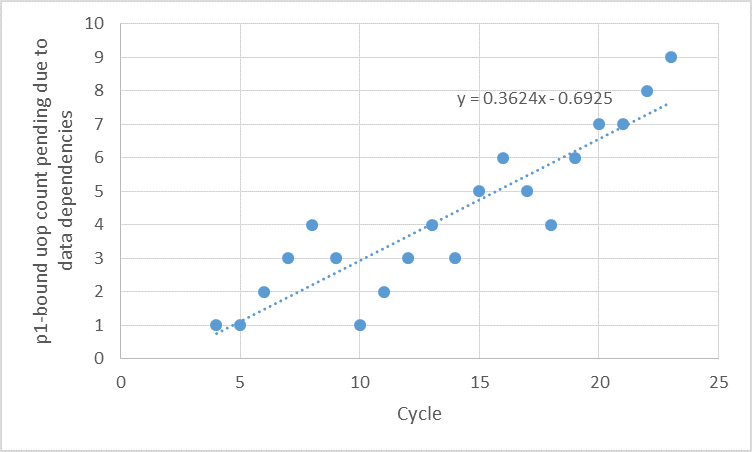
vpxor xmm0, xmm0, xmm1also reads XMM0, as well as writing it, so that instruction does have a dep on XMM0). – Pentstemonadd/jnz(for the increment/jump) are not bound to any port,.. which is a bit surprising, right?). – Fillinxmm0isn't the issue. (I was talking about the instructionvpxor xmm0, xmm1, xmm3which has a WAR dependency with the previous instruction, but "not really"; but according to your link, only the RAW dependencies remain, so that one isn't an issue). – Fillin-tracefor both codes? I would have generated them myself, but I cannot install Clang 5.0 because I don't want to remove an older version (Clang 3.8). When I use 3.8, the generated codes are different and both codes are backend-bound, which makes sense to me. – Internment