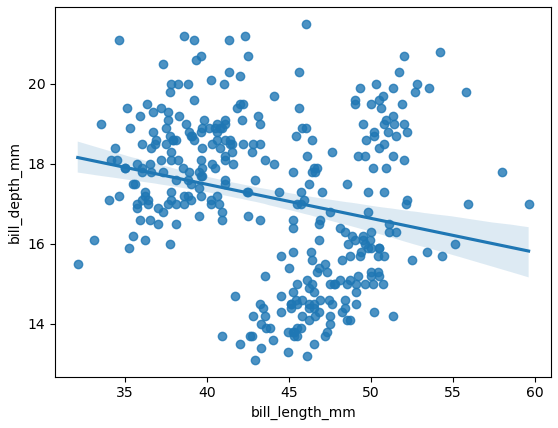
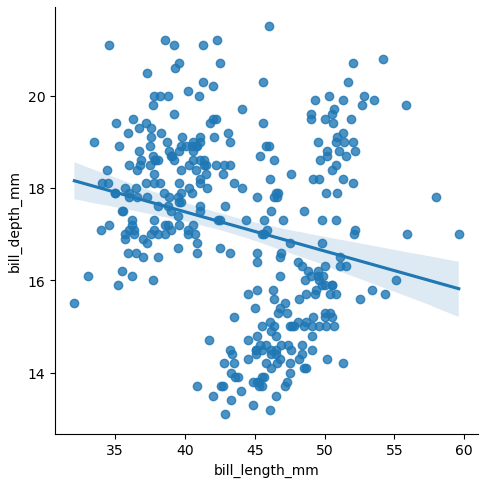
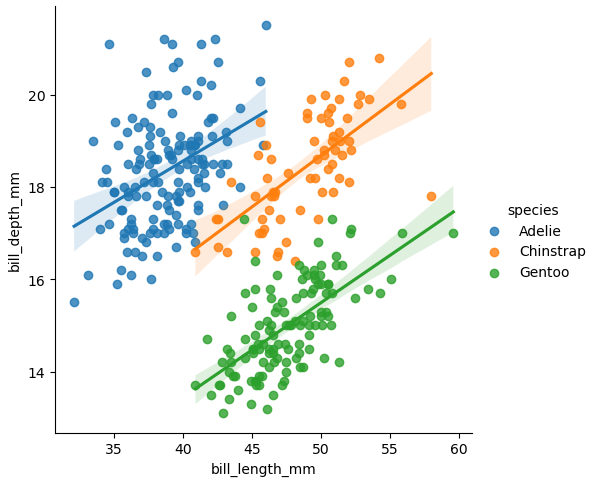
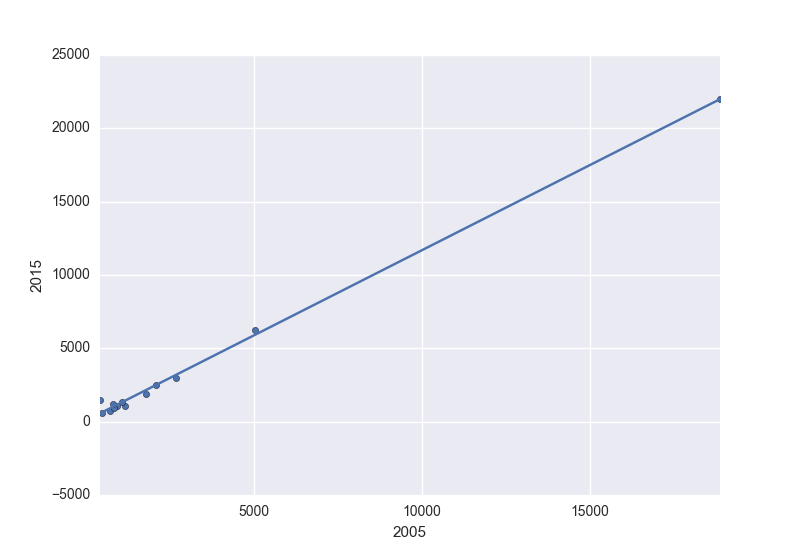
This is covering the plotly approach
#load the libraries
import pandas as pd
import numpy as np
import plotly.express as px
import plotly.graph_objects as go
# create the data
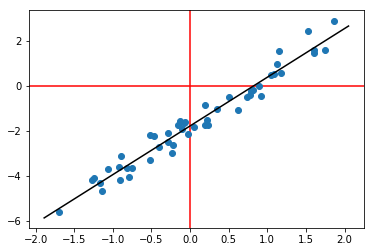
N = 50
x = pd.Series(np.random.randn(N))
y = x*2.2 - 1.8
# plot the data as a scatter plot
fig = px.scatter(x=x, y=y)
# fit a linear model
m, c = fit_line(x = x,
y = y)
# add the linear fit on top
fig.add_trace(
go.Scatter(
x=x,
y=m*x + c,
mode="lines",
line=go.scatter.Line(color="red"),
showlegend=False)
)
# optionally you can show the slop and the intercept
mid_point = x.mean()
fig.update_layout(
showlegend=False,
annotations=[
go.layout.Annotation(
x=mid_point,
y=m*mid_point + c,
xref="x",
yref="y",
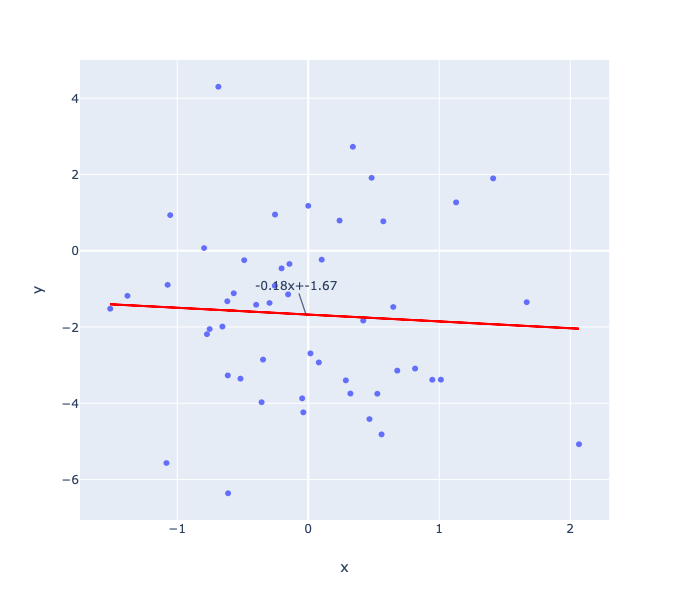
text=str(round(m, 2))+'x+'+str(round(c, 2)) ,
)
]
)
fig.show()
where fit_line is
def fit_line(x, y):
# given one dimensional x and y vectors - return x and y for fitting a line on top of the regression
# inspired by the numpy manual - https://docs.scipy.org/doc/numpy/reference/generated/numpy.linalg.lstsq.html
x = x.to_numpy() # convert into numpy arrays
y = y.to_numpy() # convert into numpy arrays
A = np.vstack([x, np.ones(len(x))]).T # sent the design matrix using the intercepts
m, c = np.linalg.lstsq(A, y, rcond=None)[0]
return m, c
![enter image description here]()
{kind=link}