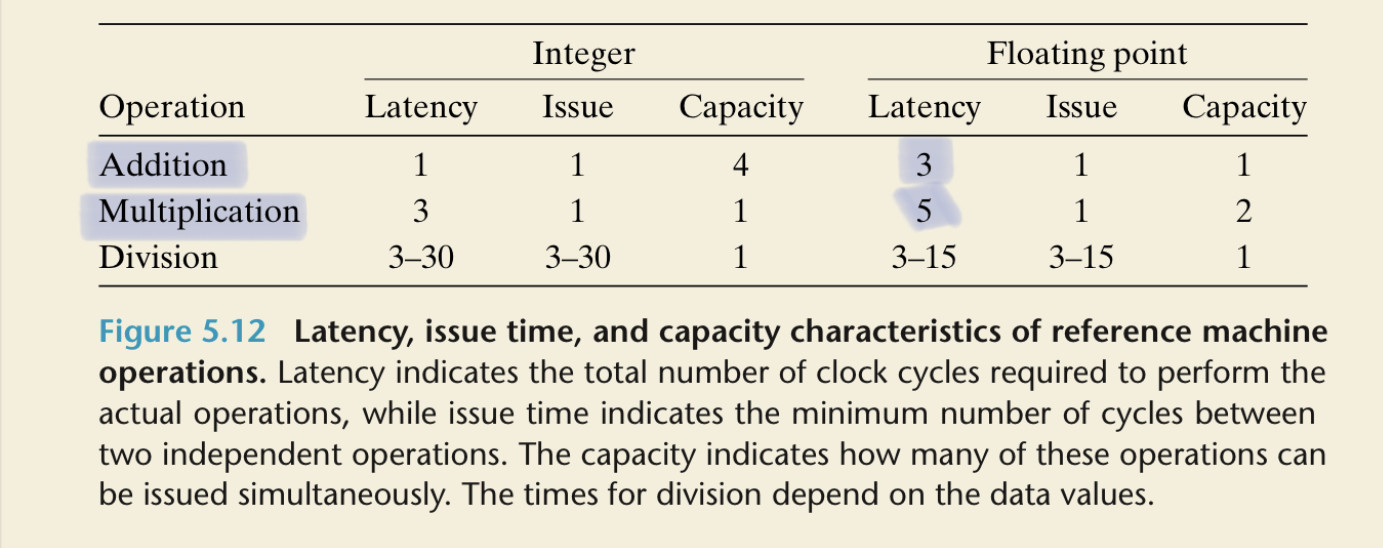
In problem 5.5, each calculation of xpwr depends on the previous calculation of xpwr (in the absence of aggressive optimization by the compiler, such as loop unrolling), so it must wait the full latency of a multiplication.
The calculation of result depends on a previous addition to result and a multiplication that can be done in parallel. The addition has a lower latency than the multiplication, so it does not limit the computation.
In more detail, what will typically happen for the floating-point operations in the CPU (ignoring loads, integer operations, and so on) is something like:
- Cycle 0:
a[i] * xpwr will be started (for i = 0).
- Cycle 0:
result += a[i] * xpwr cannot be started because it has to wait for a[i] * xpwr.
- Cycle 0:
x * xpwr is started. (I assume we can start both of these in cycle 0 because the text says the capacity for issuing multiplications is 2 per cycle. It also says there has to be 1 cycle between issuing independent operations, but I do not see the sense of that given the capacity is 2 per cycle.)
- Cycle 5:
a[i] * xpwr and x * xpwr finish.
- Cycle 5:
result += a[i] * xpwr is started (for i = 0).
- Cycle 5:
a[i] * xpwr is started (for i = 1).
- Cycle 5:
x * xpwr is started.
- Cycle 8:
result += a[i] * xpwr finishes.
- Cycle 8:
result += a[i] * xpwr (for i = 1) cannot start because its xpwr is not available.
- Cycle 10:
a[i] * xpwr and x * xpwr finish.
- Cycle 10:
result += a[i] * xpwr is started (for i = 1).
- Cycle 10:
a[i] * xpwr is started (for i = 2).
- Cycle 10:
x * xpwr is started.
- Cycle 13:
result += a[i] * xpwr finishes.
Then everything repeats on a five-cycle period.
In problem 5.6, result = a[i] + x*result means that, after we get the previous value of result, it takes five cycles to compute x*result, and we cannot start the addition until we have the result of that multiplication. Then it takes three cycles to compute a[i] + x*result, so it takes eight cycles from getting one result to getting the next one.




a[i](inresult += a[i] * xpwr;) into something like*(double *) ( ( void *)a + sizeof(double) * i);with an addition and a multiplication; or does the compiler lift it out of the loop likeresult += *(double *)tempAddress * xpwr;andtempAddress += sizeof(double);so there's an addition but no multiplication, or does the compiler use a CPU's complex addressing modes (e.g. like "mov rax,[rsi+rcx*8]` on 80x86) and pretend that the addition is not an addition (and pretend the shift isn't a shift or multiplication)? – Newfoundlanda[i]is, then... ;-) – Newfoundlandi++loop-carried dep chain, but that's only integer so it can easily get unrolled. Pretty clearly the book authors meant to ask for counts of FP math operations, the expensive ones in this case. Unfortunately they didn't explicitly say that. :/ – Wandie