Summary
Consider the following loop:
loop:
movl $0x1,(%rax)
add $0x40,%rax
cmp %rdx,%rax
jne loop
where rax is initialized to the address of a buffer that is larger than the L3 cache size. Every iteration performs a store operation to the next cache line. I expect that the number of RFO requests sent from the L1D to the L2 to be more or less equal to the number of cache lines accessed. The problem is that this seems to be only the case when I count kernel-mode events even though the program runs in user-mode, except in one case as I discuss below. The way the buffer is allocated does not seem to matter (.bss, .data, or from the heap).
Details
The results of my experiments are shown in the tables below. All of the experiments are performed on processors with hyperthreading disabled and all hardware prefetchers enabled.
I've tested the following three cases:
- There is no initialization loop. That is, the buffer is not accessed before the "main" loop shown above. I'll refer to this case as
NoInit. There is only one loop in this case. - The buffer is first accessed using one load instruction per cache line. Once all the lines are touched, the main loop is then executed. I'll refer to this case as
LoadInit. There are two loops in this case. - The buffer is first accessed using one store instruction per cache line. Once all the lines are touched, the main loop is then executed. I'll refer to this case as
StoreInit. There are two loops in this case.
The following table shows the results on an Intel CFL processor. These experiments have been performed on Linux kernel version 4.4.0.
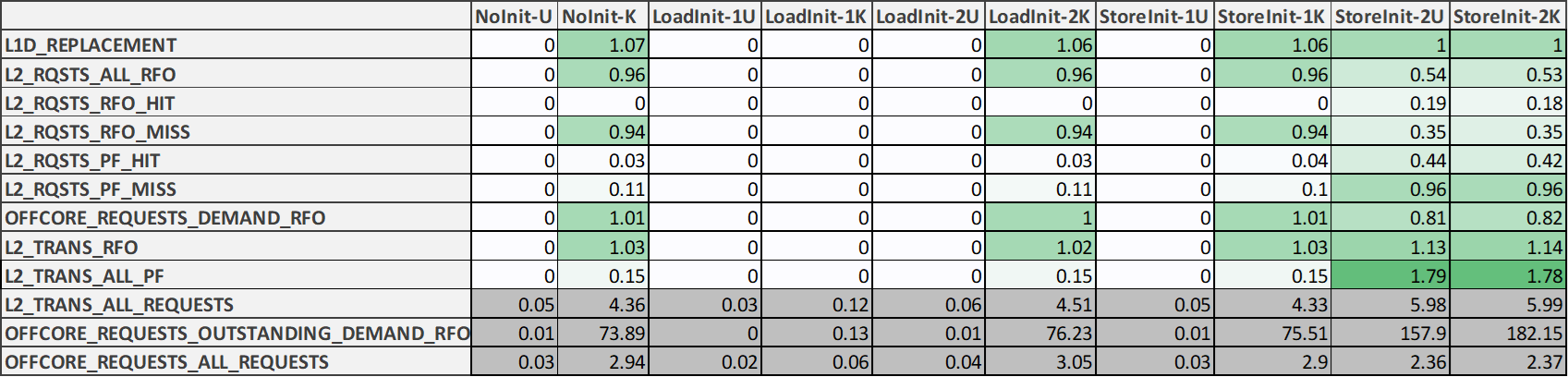
The following table shows the results on an Intel HSW processor. Note that the events L2_RQSTS.PF_HIT, L2_RQSTS.PF_MISS, and OFFCORE_REQUESTS.ALL_REQUESTS are not documented for HSW. These experiments have been performed on Linux kernel version 4.15.

The first column of each table contains the names of the performance monitoring events whose counts are the shown in the other columns. In the column labels, the letters U and K represent user-mode and kernel-mode events, respectively. For the cases that have two loops, the numbers 1 and 2 are used to refer to the initialization loop and the main loop, respectively. For example, LoadInit-1K represents the kernel-mode counts for the initialization loop of the LoadInit case.
The values shown in the tables are normalized by the number of cache lines. They are also color-coded as follows. The darker the green color is the larger the value is with respect to all other cells in the same table. However, the last three rows of the CFL table and the last two rows of the HSW table are not color-coded because some of the values in these rows are too large. These rows are painted in dark gray to indicate that they are not color-coded like the other rows.
I expect that the number of user-mode L2_RQSTS.ALL_RFO events to be equal to the number of cache lines accessed (i.e., a normalized value of 1). This event is described in the manual as follows:
Counts the total number of RFO (read for ownership) requests to L2 cache. L2 RFO requests include both L1D demand RFO misses as well as L1D RFO prefetches.
It says that L2_RQSTS.ALL_RFO may not only count demand RFO requests from the L1D but also L1D RFO prefetches. However, I've observed that the event count is not affected by whether the L1D prefetchers are enabled or disabled on both processors. But even if the L1D prefetchers may generated RFO prefetches, the event count then should be at least as large as the number of cache lines accessed. As can be seen from both tables, this is only the case in StoreInit-2U. The same observation applies to all of the events show in the tables.
However, the kernel-mode counts of the events are about equal to what the user-mode counts are expected to be. This is in contrast to, for example, MEM_INST_RETIRED.ALL_STORES (or MEM_UOPS_RETIRED.ALL_STORES on HSW), which works as expected.
Due to the limited number of PMU counter registers, I had to divide all the experiments into four parts. In particular, the kernel-mode counts are produced from different runs than the user-mode counts. It doesn't really matter what is being counted in the same. I think it's important to tell you this because this explains why some user-mode counts are a little larger than the kernel-mode counts of the same events.
The events shown in dark gray seem to overcount. The 4th gen and 8th gen Intel processor specification manuals do mention (problem HSD61 and 111, respectively) that OFFCORE_REQUESTS_OUTSTANDING.DEMAND_RFO may overcount. But these results indicate that it may be overcounted by many times, not by just a couple of events.
There are other interesting observations, but they are not pertinent to the question, which is: why are the RFO counts not as expected?