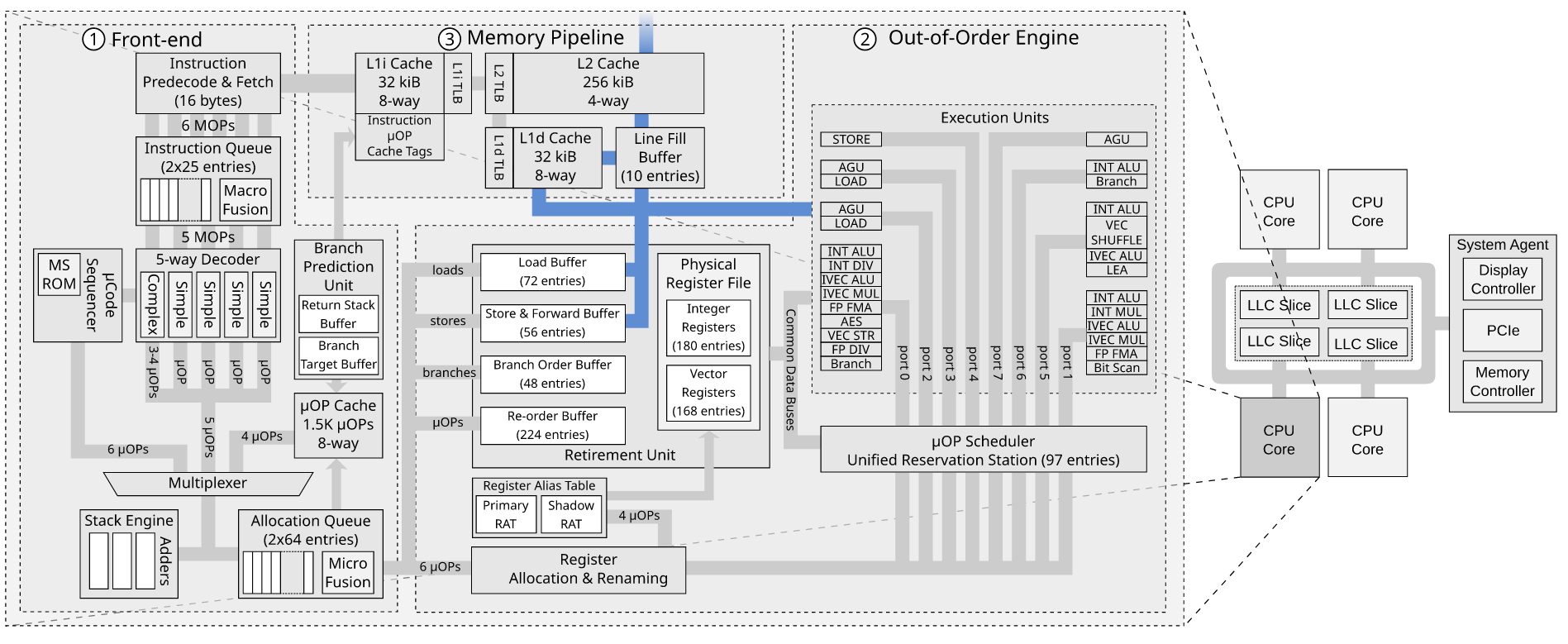
When the uops reach the allocator, in the PRF + Retirement RAT scheme (SnB onwards), the allocator consults the front end RAT (F-RAT) when necessary for a rename for the ROB entries (i.e. when a write to an architectural register (e.g. rax) is performed) it assigns to each uop at the tail pointer of the ROB. The RAT keeps a list of free and in use physical destination registers (pdsts) in the PRF. The RAT returns the physical register numbers to be used that are free and then the ROB places those in the respective entries (in the RRF scheme, the allocator provided to the RAT the pdsts to be used; the RAT was unable to select because the pdsts to be used were inherently at the tail pointer of the ROB). The RAT also updates each architectural register pointer with the register it assigned to it i.e. it now points to the register that contains the most recent write data in the program order. At the same time, the ROB allocates an entry in the Reservation Station (RS). In the event of a store it will place a store-address uop and a store-data uop in the RS. The allocator also allocates SDB (store data buffer) / SAB (store address buffer) entries and only allocates when all the required entries in the ROB / RS / RAT / SDB / SAB are available
As soon as these uops are allocated in the RS, the RS reads the physical registers for its source operands and stores them in the data field and at the same time checks EU writeback busses for those source PRs (Physical Registers) associated ROB entries and the writeback data as they are being written back to the ROB. The RS then schedules these uops for dispatch to the store-address and store-data ports when they have all their completed source data.
The uops are then dispatched -- the store address uop goes to the AGU and the AGU generates the address, transforms it to a linear address and then writes the result into the SAB. I don't think a store requires a PR at all in the PRF+R-RAT scheme (meaning that a writeback doesn't need to occur to the ROB at this stage) but in the RRF scheme ROB entries were forced to use their embedded PR and everything (ROB / RS / MOB entries) were identified by their PR nos. One of the benefits of the PRF+R-RAT scheme is that the ROB and hence the maximum number of uops in-flight can be expanded without having to increase the number of PRs (as there will be instructions that do not require any), and everything is addressed by ROB entry nos in case the entries do not have identifying PRs.
The store data goes directly through the store converter (STC) to the SDB. As soon as they are dispatched, they can be deallocated for reuse by other uops. This prevents the much larger ROB from being limited by the size of the RS.
The address then gets sent to the dTLB and it then stores the physical tag output from the dTLB in the L1d cache's PAB.
The allocator already allocated the SBID and the corresponding entries in the SAB / SDB for that ROB entry (STA+STD uops are microfused into one entry), which buffer the results of the dispatched execution in the AGU / TLB from the RS. The stores sit in the SAB / SDB with a corresponding entry with the same entry no. (SBID), which links them together, until the MOB is informed by the retirement unit of which stores are retirement ready i.e. they are no longer speculative, and it is informed upon a CAM match of a ROB entry retriement pointer pointing to a ROB index/ID that is contained in the SAB / SDB entry (in a uarch that can retire 3 uops per cycle, there are 3 retirement pointers that point to the 3 oldest unretired instructions in the ROB, and only the ROB ready bit patterns 0,0,1 0,1,1 and 1,1,1 permit retirement pointer CAM matches to go ahead). At this stage, they can retire in the ROB (known as 'retire / complete locally') and become senior stores and are marked with a senior bit (Ae bit for STA, De bit for STD), and are slowly dispatched to the L1d cache, so long as the data in the SAB / SDB / PAB is valid.
The L1d cache uses the linear index in the SAB to decode a set in the tags array that would contain the data using the linear index, and in the next cycle uses the corresponding PAB entry with the same index value as the SBID to compare the physical tag with the tags in the set. The whole purpose of the PAB is to allow for early TLB lookups for stores to hide the overhead of a dTLB miss while they are doing nothing else waiting to become senior, and to allow for speculative page walks while the stores are still actually speculative. If the store is immediately senior then this early TLB lookup probably doesn't occur and it is just dispatched, and that is when the L1d cache will decode the tag array set and look up the dTLB in parallel and the PAB is bypassed. Remember though that it can't retire from the ROB until the TLB translation has been performed because there might be a PMH exception code (page fault, or access / dirty bits read need to be set while performing the page walk), or an exception code when the TLB needs to write through access / dirty bits it sets in a TLB entry. It is entirely possible that the TLB lookup for the store always occurs at this stage and does not perform it in parallel with the set decode (unlike loads). The store becomes senior when the PA in the PAB becomes valid (valid bit is set in the SAB) and it is retirement ready in the ROB.
It then checks the state of the line. If it is a shared line, the physical address is sent to the coherence domain in an RFO (always RFO for writes), and when it has ownership of the line, it writes the data into the cache. If the line isn't present then a LFB is allocated for that cache line and the store data is stored in it and a request is sent to L2, which will then check the state of the line in L2 and initiate a read or RFO on the ring IDI interface.
The store becomes globally visible when the RFO completes and a bit in the LFB indicates it has permission to write the line meaning that the LFB will be written back coherently upon the next snoop invalidation or eviction (or in the event of a hit, when the data is written to the line). It is not considered globally visible when it is just written to the LFB before the fetching of the line in the event of a miss goes ahead (unlike senior loads that do retire on a hit or when a LFB is allocated by the L1d cache), because there may be other RFOs initiated by other cores which might reach the LLC slice controller before the request from the current core, which would be a problem if a SFENCE on the current core had retired based on this version of 'globally visible' retirement -- at least this provides a synchronisation guarantee for inter-processor interrupts. Globally visible is the very moment where that stored data will be read by another core if a load happens on another core, not the moment where it will be after a small duration where before that the old value will still be read by other cores. Stores are completed by the L1d cache upon allocation of a LFB (or when they are written to the line in the event of a hit) and retire from the SAB / SDB. When all previous stores have retired from the SAB / SDB, this is when store_address_fence (not store_address_mfence) and its associated store_data_fence can be dispatched to the L1d. It is more practical for LFENCE to serialise the ROB instruction stream as well, whereas SFENCE/MFENCE do not because it would potentially cause a very long delay in the ROB for global visibility and is not necessary, unlike senior loads which retire instantly, so it makes sense why LFENCE was the fence chosen the serialise the instruction stream at the same time. SFENCE/MFENCE do not retire until all LFBs that were allocated become globally visible.
A line fill buffer can be in 1 of 3 modes: read, write or write combining. The purpose of the write line fill buffer I think is to combine multiple stores to the same line's data into the LFB and then when the line arrives, fill in the non-valid bits with the data fetched from L2. It may be at this stage that it is considered completed and therefore the writes are satisfied in bulk and a cycle earlier, rather than waiting for them to be written into the line. As long as it is now guaranteed to be written back to the cache in response to the RFO of another core. The LFB will probably remain allocated until it needs to be deallocated, allowing for slightly faster satisfying of subsequent reads and writes to the same line. A read line buffer can service read misses a few cycles quicker, because it is instantly available in the line fill buffer but takes longer to write it to the cache line and then read from it. A write combining buffer is allocated when the memory is a USWC type and allows writes to be satisfied immediately and flushed to a MMIO device all at once rather than having multiple core->PCIe transactions and having multiple PCIe transactions. The WC buffer also allows speculative reads from the buffer. Typically speculative reads are not allowed on UC memory because the read could change the state of the MMIO device but also the read/write takes so long that by the time it completes, it will no longer be speculative and is therefore perhaps not worth the extra traffic? A LFB is likely VIPT (VIPT/PIPT are the same on intel, and the V is a linear address on intel); I suppose it could have the physical and the virtual tag to eliminate further TLB lookups, but would have to negotiate something for when the physical page migrates to a new physical address.