I don't think load replays from the RS are involved in the RIDL attacks. So instead of explaining what load replays are (@Peter's answer is a good starting point for that), I'll discuss what I think is happening based on my understanding of the information provided in the RIDL paper, Intel's analysis of these vulnerabilities, and relevant patents.
Line fill buffers are hardware structures in the L1D cache used to hold memory requests that miss in the cache and I/O requests until they get serviced. A cacheable request is serviced when the required cache line is filled into the L1D data array. A write-combining write is serviced when the any of the conditions for evicting a write-combining buffer occur (as described in the manual). A UC or I/O request is serviced when it is sent to the L2 cache (which occurs as soon as possible).
Refer to Figure 4 of the RIDL paper. The experiment used to produce these results works as follows:
- The victim thread writes a known value to a single memory location. The memory type of the memory location is WB, WT, WC, or UC.
- The victim thread reads the same memory location in a loop. Each load operation is followed by
MFENCE and there is an optional CLFLUSH. It's not clear to me from the paper the order of CLFLUSH with respect to the other two instructions, but it probably doesn't matter. MFENCE serializes the cache line flushing operation to see what happens when every load misses in the cache. In addition, MFENCE reduces contention between the two logical cores on the L1D ports, which improves the throughput of the attacker.
- An attacker thread running on a sibling logical core executes the code shown in Listing 1 in a loop. The address used at Line 6 can be anything. The only thing that matters is that load at Line 6 either faults or causes a page walk that requires an microcode assist (to set the accessed bit in the page table entry). A page walk requires using the LFBs as well and most of the LFBs are shared between the logical cores.
It's not clear to me what the Y-axis in Figure 4 represents. My understanding is that it represents the number of lines from the covert channel that got fetched into the cache hierarchy (Line 10) per second, where the index of the line in the array is equal to the value written by the victim.
If the memory location is of the WB type, when the victim thread writes the known value to the memory location, the line will be filled into the L1D cache. If the memory location is of the WT type, when the victim thread writes the known value to the memory location, the line will not be filled into the L1D cache. However, on the first read from the line, it will be filled. So in both cases and without CLFLUSH, most loads from the victim thread will hit in the cache.
When the cache line for a load request reaches the L1D cache, it gets written first in the LFB allocated for the request. The requested portion of the cache line can be directly supplied to the load buffer from the LFB without having to wait for the line to be filled in the cache. According to the description of the MFBDS vulnerability, under certain situations, stale data from previous requests may be forwarded to the load buffer to satisfy a load uop. In the WB and WT cases (without flushing), the victim's data is written into at most 2 different LFBs. The page walks from the attacker thread can easily overwrite the victim's data in the LFBs, after which the data will never be found in there by the attacker thread. All load requests that hit in the L1D cache don't go through the LFBs; there is a separate path for them, which is multiplexed with the path from the LFBs. Nonetheless, there are some cases where stale data (noise) from the LFBs is being speculatively forwarded to the attacker's logical core, which is probably from the page walks (and maybe interrupt handlers and hardware prefetchers).
It's interesting to note that the frequency of stale data forwarding in the WB and WT cases is much lower than in all of the other cases. This is could be explained by the fact that the victim's throughput is much higher in these cases and the experiment may terminate earlier.
In all other cases (WC, UC, and all types with flushing), every load misses in the cache and the data has to be fetched from main memory to the load buffer through the LFBs. The following sequence of events occur:
- The accesses from the victim hit in the TLB because they are to the same valid virtual page. The physical address is obtained from the TLB and provided to the L1D, which allocates an LFB for the request (due to a miss) and the physical address is written into the LFB together with other information that describes the load request. At this point, the request from the victim is pending in the LFB. Since the victim executes an
MFENCE after every load, there can be at most one outstanding load in the LFB at any given cycle from the victim.
- The attacker, running on the sibling logical core, issues a load request to the L1D and the TLB. Each load is to an unmapped user page, so it will cause a fault. When the it misses in the TLB, the MMU tells the load buffer that the load should be blocked until the address translation is complete. According to paragraph 26 of the patent and other Intel patents, that's how TLB misses are handled. The address translation is still in progress the load is blocked.
- The load request from the victim receives its cache line, which gets written into the LFB allcoated for the load. The part of the line requested by the load is forwarded to the MOB and, at the same time, the line is written into the L1D cache. After that, the LFB can be deallcoated, but none of the fields are cleared (except for the field that indicates that its free). In particular, the data is still in the LFB. The victim then sends another load request, which also misses in the cache either because it is uncacheable or because the cache line has been flushed.
- The address translation process of the attacker's load completes. The MMU determines that a fault needs to be raised because the physical page is not present. However, the fault is not raised until the load is about retire (when it reaches the top of the ROB). Invalid translations are not cached in the MMU on Intel processors. The MMU still has to tell the MOB that the translation has completed and, in this case, sets a faulting code in the corresponding entry in the ROB. It seems that when the ROB sees that one of the uops has valid fault/assist code, it disables all checks related to sizes and addresses of that uops (and possibly all later uops in the ROB). These checks don't matter anymore. Presumably, disabling these checks saves dynamic energy consumption. The retirement logic knows that when the load is about to retire, a fault will be raised anyway. At the same time, when the MOB is informed that the translation is completed, it replays the attacker's load, as usual. This time, however, some invalid physical address is provided to the L1D cache. Normally, the physical address needs to compared against all requests pending in the LFBs from the same logical core to ensure that the logical core sees the most recent values. This is done before or in parallel with looking up the L1D cache. The physical address doesn't really matter because the comparison logic is disabled. However, the results of all comparisons behave as if the result indicates success. If there is at least one allocated LFB, the physical address will match some allocated LFB. Since there is an outstanding request from the victim and since the victim's secret may have already been written in the same LFB from previous requests, the same part of the cache line, which technically contains stale data and in this case (the stale data is the secret), will be forwarded to the attacker. Note that the attacker has control over the offset within a cache line and the number of bytes to get, but it cannot control which LFB. The size of a cache line is 64 bytes, so only the 6 least significant bits of the virtual address of the attacker's load matter, together with the size of the load. The attacker then uses the data to index into its array to reveal the secret using a cache side channel attack. This behavior would also explain MSBDS, where apparently the data size and STD uop checks are disabled (i.e, the checks trivially pass).
- Later, the faulting/assisting load reaches the top of the ROB. The load is not retired and the pipeline is flushed. In case of faulting load, a fault is raised. In case of an assisting load, execution is restarted from the same load instruction, but with an assist to set the required flags in the paging structures.
- These steps are repeated. But the attacker may not always be able to leak the secret from the victim. As you can see, it has to happen that the load request from the attacker hits an allocated LFB entry that contains the secret. LFBs allocated for page walks and hardware prefetchers may make it harder to perform a successful attack.
If the attacker's load didn't fault/assist, the LFBs will receive a valid physical address from the MMU and all checks required for correctness are performed. That's why the load has to fault/assist.
The following quote from the paper discusses how to perform a RIDL attack in the same thread:
we perform the RIDL attack without SMT by writing values in our own
thread and observing the values that we leak from the same thread.
Figure3 shows that if we do not write the values (“no victim”), we leak
only zeros, but with victim and attacker running in the same hardware
thread (e.g., in a sandbox), we leak the secret value in almost all
cases.
I think there are no privilege level changes in this experiment. The victim and the attacker run in the same OS thread on the same hardware thread. When returning from the victim to the attacker, there may still be some outstanding requests in the LFBs from (especially from stores). Note that in the RIDL paper, KPTI is enabled in all experiments (in contrast to the Fallout paper).
In addition to leaking data from LFBs, MLPDS shows that data can also be leaked from the load port buffers. These include the line-split buffers and the buffers used for loads larger than 8 bytes in size (which I think are needed when the size of the load uop is larger than the size of the load port, e.g., AVX 256b on SnB/IvB that occupy the port for 2 cycles).
The WB case (no flushing) from Figure 5 is also interesting. In this experiment, the victim thread writes 4 different values to 4 different cache lines instead of reading from the same cache line. The figure shows that, in the WB case, only the data written to the last cache line is leaked to the attacker. The explanation may depend on whether the cache lines are different in different iterations of the loop, which is unfortunately not clear in the paper. The paper says:
For WB without flushing, there is a signal only for the last cache
line, which suggests that the CPU performs write combining in a single
entry of the LFB before storing the data in the cache.
How can writes to different cache lines be combining in the same LFB before storing the data in the cache? That makes zero sense. An LFB can hold a single cache line and and a single physical address. It's just not possible to combine writes like that. What may be happening is that WB writes are being written in the LFBs allocated for their RFO requests. When the invalid physical address is transmitted to the LFBs for comparison, the data may always be provided from the LFB that was last allocated. This would explain why only the value written by the fourth store is leaked.
For information on MDS mitigations, see: What are the new MDS attacks, and how can they be mitigated?. My answer there only discusses mitigations based on the Intel microcode update (not the very interesting "software sequences").
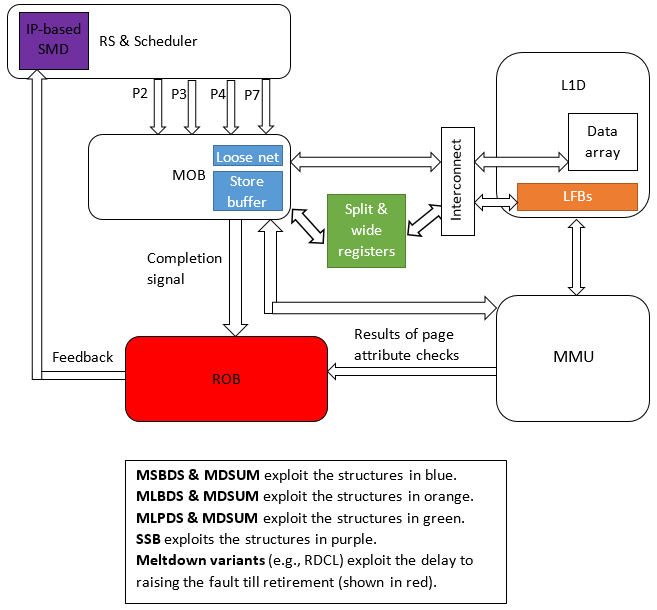
The following figure shows the vulnerable structures that use data speculation.
![enter image description here]()