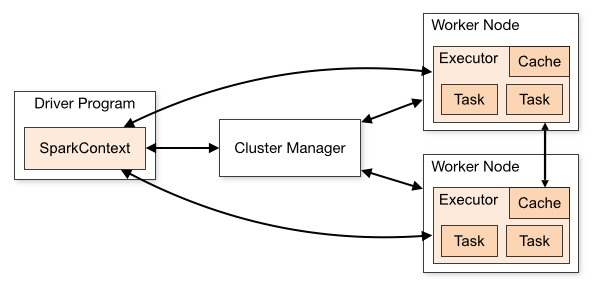
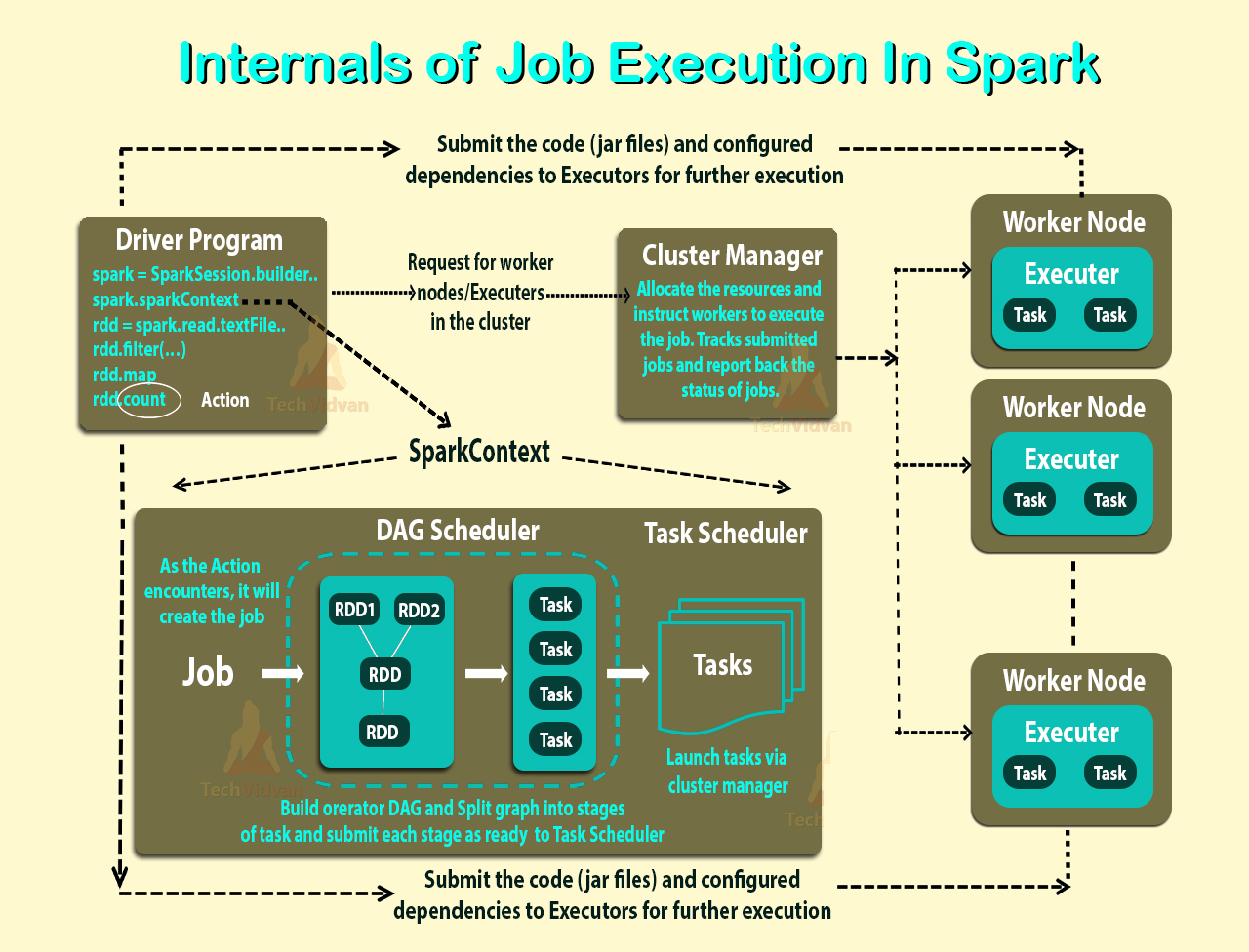
I read Cluster Mode Overview and I still can't understand the different processes in the Spark Standalone cluster and the parallelism.
Is the worker a JVM process or not? I ran the bin\start-slave.sh and found that it spawned the worker, which is actually a JVM.
As per the above link, an executor is a process launched for an application on a worker node that runs tasks. An executor is also a JVM.
These are my questions:
Executors are per application. Then what is the role of a worker? Does it co-ordinate with the executor and communicate the result back to the driver? Or does the driver directly talks to the executor? If so, what is the worker's purpose then?
How to control the number of executors for an application?
Can the tasks be made to run in parallel inside the executor? If so, how to configure the number of threads for an executor?
What is the relation between a worker, executors and executor cores ( --total-executor-cores)?
What does it mean to have more workers per node?
Updated
Let's take examples to understand better.
Example 1: A standalone cluster with 5 worker nodes (each node having 8 cores) When I start an application with default settings.
Example 2 Same cluster config as example 1, but I run an application with the following settings --executor-cores 10 --total-executor-cores 10.
Example 3 Same cluster config as example 1, but I run an application with the following settings --executor-cores 10 --total-executor-cores 50.
Example 4 Same cluster config as example 1, but I run an application with the following settings --executor-cores 50 --total-executor-cores 50.
Example 5 Same cluster config as example 1, but I run an application with the following settings --executor-cores 50 --total-executor-cores 10.
In each of these examples, How many executors? How many threads per executor? How many cores? How is the number of executors decided per application? Is it always the same as the number of workers?