Extending to other great answers, I would like to describe with few images.
In Spark Standalone mode, there are master node and worker nodes.
If we represent both master and workers(each worker can have multiple executors if CPU and memory are available) at one place for standalone mode.
![Spark Standalone mode]()
If you are curious about how Spark works with YARN? check this post Spark on YARN
1. Does two worker instance mean one worker node with two worker processes?
In general, we call worker instance as a slave as it's a process to execute spark tasks/jobs. Suggested mapping for a node(a physical or virtual machine) and a worker is,
1 Node = 1 Worker process
2. Does every worker instance hold an executor for the specific application (which manages storage, task) or one worker node holds one executor?
Yes, A worker node can be holding multiple executors (processes) if it has sufficient CPU, Memory and Storage.
Check the Worker node in the given image.
![A Worker node in a cluster]()
BTW, the Number of executors in a worker node at a given point of time entirely depends on workload on the cluster and capability of the node to run how many executors.
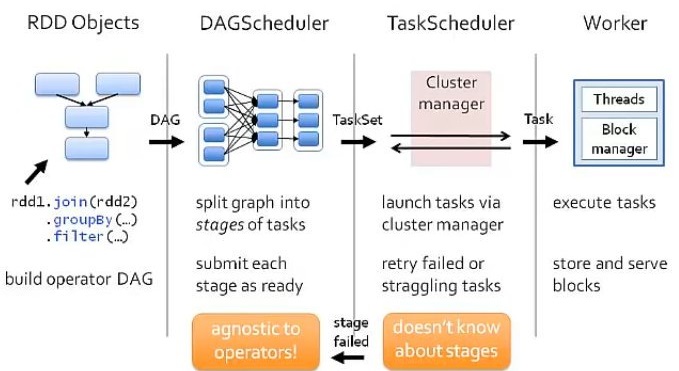
3. Is there a flow chart explaining how spark runtime?
If we look at the execution from Spark perspective over any resource manager for a program, which join two rdds and do some reduce operation then filter
![Spark runtime for a sample code]()
HIH