Overview
I wrote a blog for how the consistent-hashing works, here to answer those original questions, below are the quick summary.
Consistent-hashing are more commonly used for the data partitioning purpose, and we usually see it in the components like
- Load balancer
- API gateway
- ...
To answer the questions, the below will covers
- How it works
- How to add/find/remove server nodes
- How to implement it
- Any alternatives to consistent hashing?
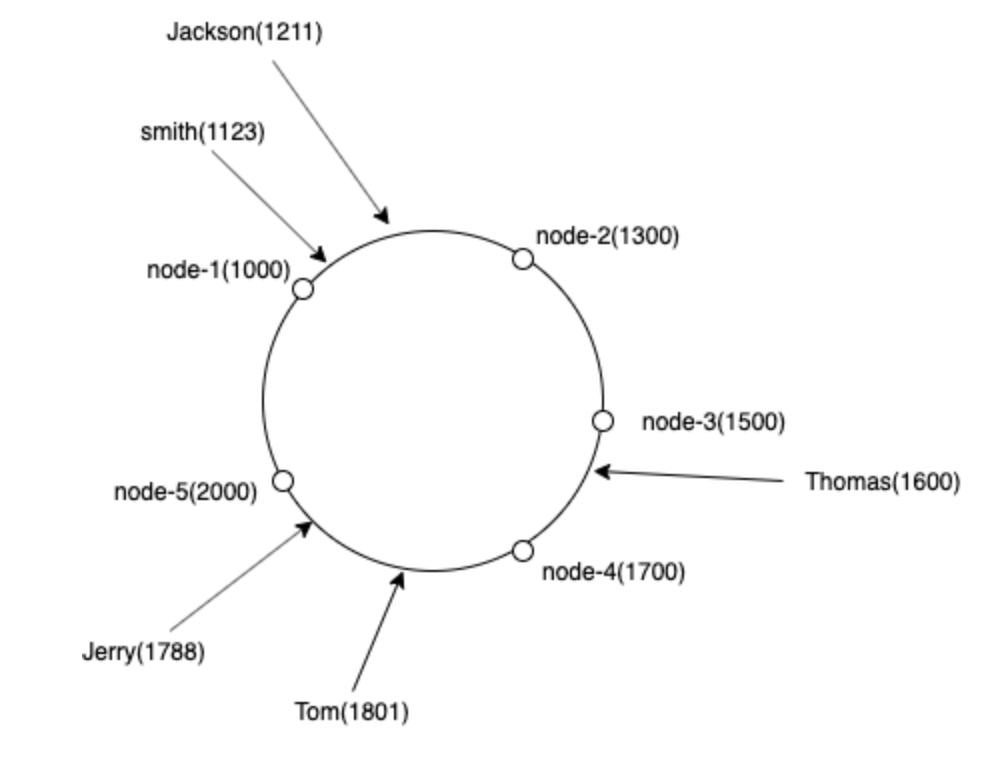
Let's use a simple example here the load balancer, the load balancer maps 2 origin nodes (servers behind the load balancer) and the incoming requests in the same hash ring circle (let's say the hash ring range is [0,255]).
Initial State
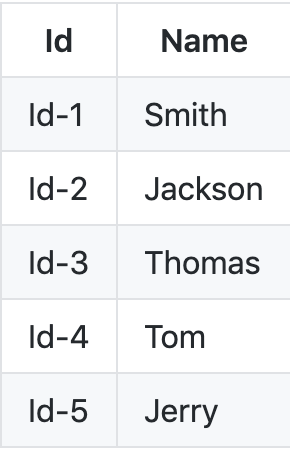
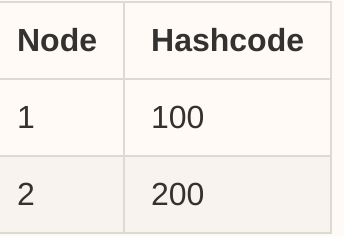
For the server nodes, we have a table:
![enter image description here]()
Find Node
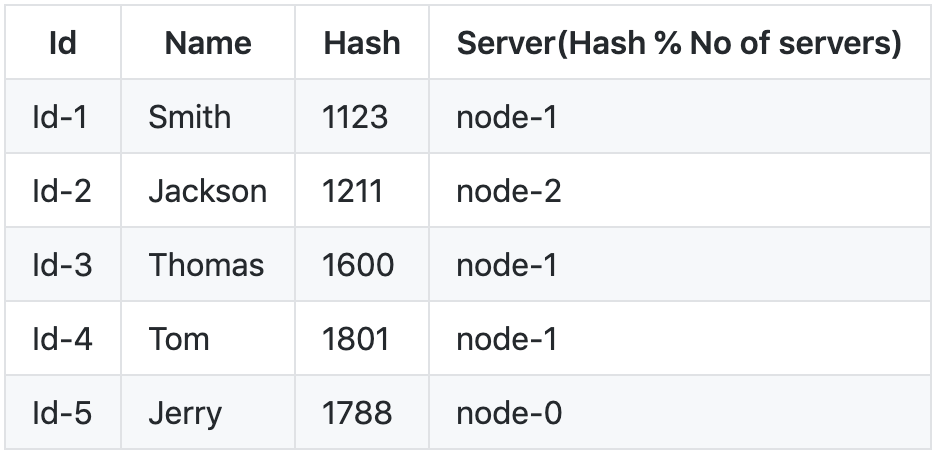
For any incoming request, we apply the same hash function, then we assume that we get a hashcode for a request which hashcode = 120, now from the table, we find the next closest node in the clockwise order, so the node 2 is the target node in this case.
Similarly, what if we get a request with hashcode = 220? Because the hash ring range is a circle, so we return the first node then.
Add Node
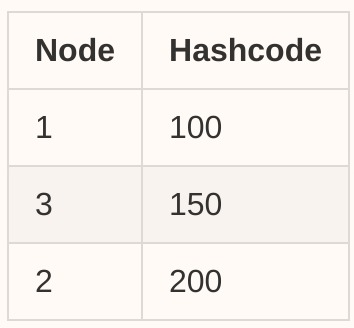
Now let's add one more node into the cluster: node 3 (hashcode 150), then our table will be updated to:
![enter image description here]()
Then we use the same algorithm in the Find Node section to find the next nearest node. Say, the request with hashcode = 120, now it will be routed to node-3.
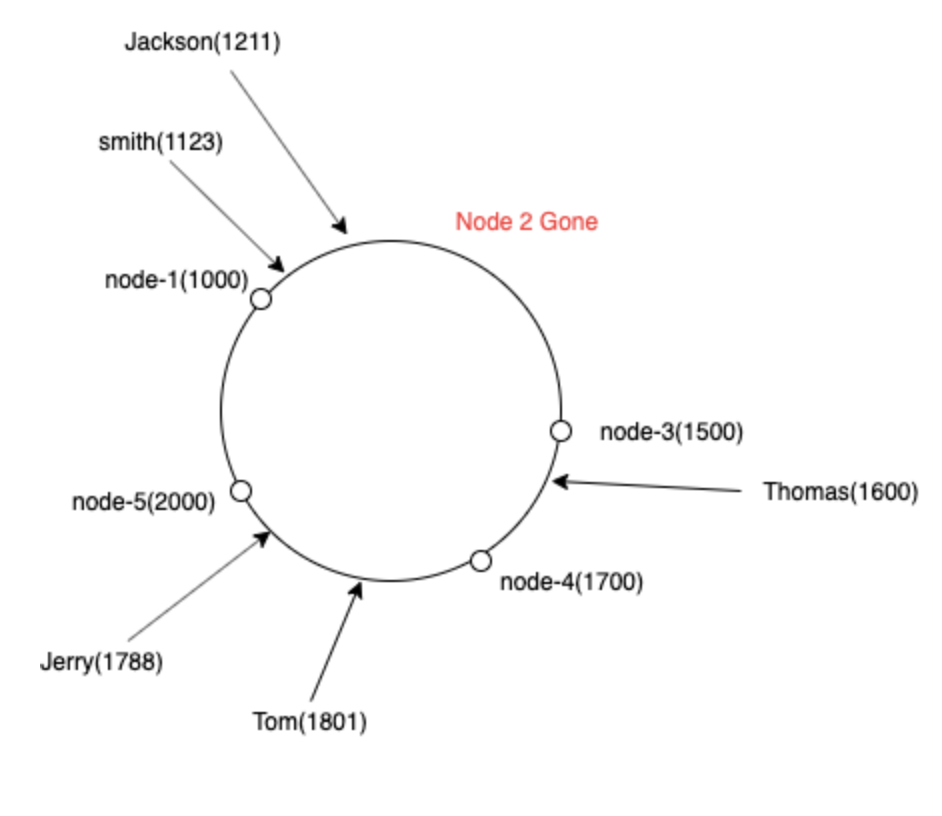
Remove Node
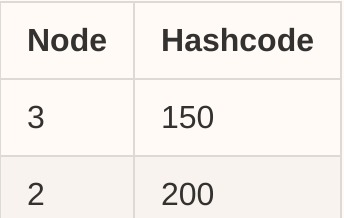
Removal is also straight forward, just remove the entry <node, hashcode> from the table, let's say we remove the node-1, then the table will be updated to:
![enter image description here]()
Then all the requests with:
- Hashcode in [201, 255] and [0, 150] will be routed to the node-3
- Hashcode in [151, 200] will be routed to node-2
Implementation
Below is a simple c++ version (with virtual-node enabled), which is quite similar to Java.
#define HASH_RING_SZ 256
struct Node {
int id_;
int repl_;
int hashCode_;
Node(int id, int replica) : id_(id), repl_(replica) {
hashCode_ =
hash<string>{} (to_string(id_) + "_" + to_string(repl_)) % HASH_RING_SZ;
}
};
class ConsistentHashing {
private:
unordered_map<int/*nodeId*/, vector<Node*>> id2node;
map<int/*hash code*/, Node*> ring;
public:
ConsistentHashing() {}
// Allow dynamically assign the node replicas
// O(Rlog(RN)) time
void addNode(int id, int replica) {
for (int i = 0; i < replica; i++) {
Node* repl = new Node(id, replica);
id2node[id].push_back(repl);
ring.insert({node->hashCode_, repl});
}
}
// O(Rlog(RN)) time
void removeNode(int id) {
auto repls = id2node[id];
if (repls.empty()) return;
for (auto* repl : repls) {
ring.erase(repl->hashCode_);
}
id2node.erase(id);
}
// Return the nodeId
// O(log(RN)) time
int findNode(const string& key) {
int h = hash<string>{}(key) % HASH_RING_SZ;
auto it = ring.lower_bound(h);
if (it == ring.end()) it == ring.begin();
return it->second->id;
}
};
Alternatives
If I understand the question correctly, the question is for asking any alternatives to consistent hashing for the data partitioning purpose. There are a lot actually, depends on the actual use case we may choose different approaches, like:
- Random
- Round-robin
- Weighted round-robin
- Mod-hashing
- Consistent-hash
- Weighted(Dynamic) consistent-hashing
- Range-based
- List-based
- Dictionary-based
- ...
And specifically in the load balancing domain, there are also some approaches like:
- Least Connection
- Least Response Time
- Least Bandwidth
- ...
All the above approaches have their own pros and cons, there is no best solution, we have to do the trade-off accordingly.
Last
Above just a quick summary for the original questions, for the further reading, like the:
- Consistent-hashing unbalancing issue
- Snow crash issue
- Virtual node concept
- How to tweak the replica number
I've covered them in the blog already, below are the shortcuts:
Have fun :)