Table of contents:
- Relationships between features
- The desired graph
- Why fit & predict?
- Plotting 8 features?
Relationships between features:
The scientific term characterizing the "relationship" between features is correlation. This area is mostly explored during PCA (Principal Component Analysis). The idea is that not all your features are important or at least some of them are highly correlated. Think of this as similarity: if two features are highly correlated so they embody the same information and consequently you can drop one of them. Using pandas this looks like this:
import pandas as pd
import seaborn as sns
from pylab import rcParams
import matplotlib.pyplot as plt
def plot_correlation(data):
'''
plot correlation's matrix to explore dependency between features
'''
# init figure size
rcParams['figure.figsize'] = 15, 20
fig = plt.figure()
sns.heatmap(data.corr(), annot=True, fmt=".2f")
plt.show()
fig.savefig('corr.png')
# load your data
data = pd.read_csv('diabetes.csv')
# plot correlation & densities
plot_correlation(data)
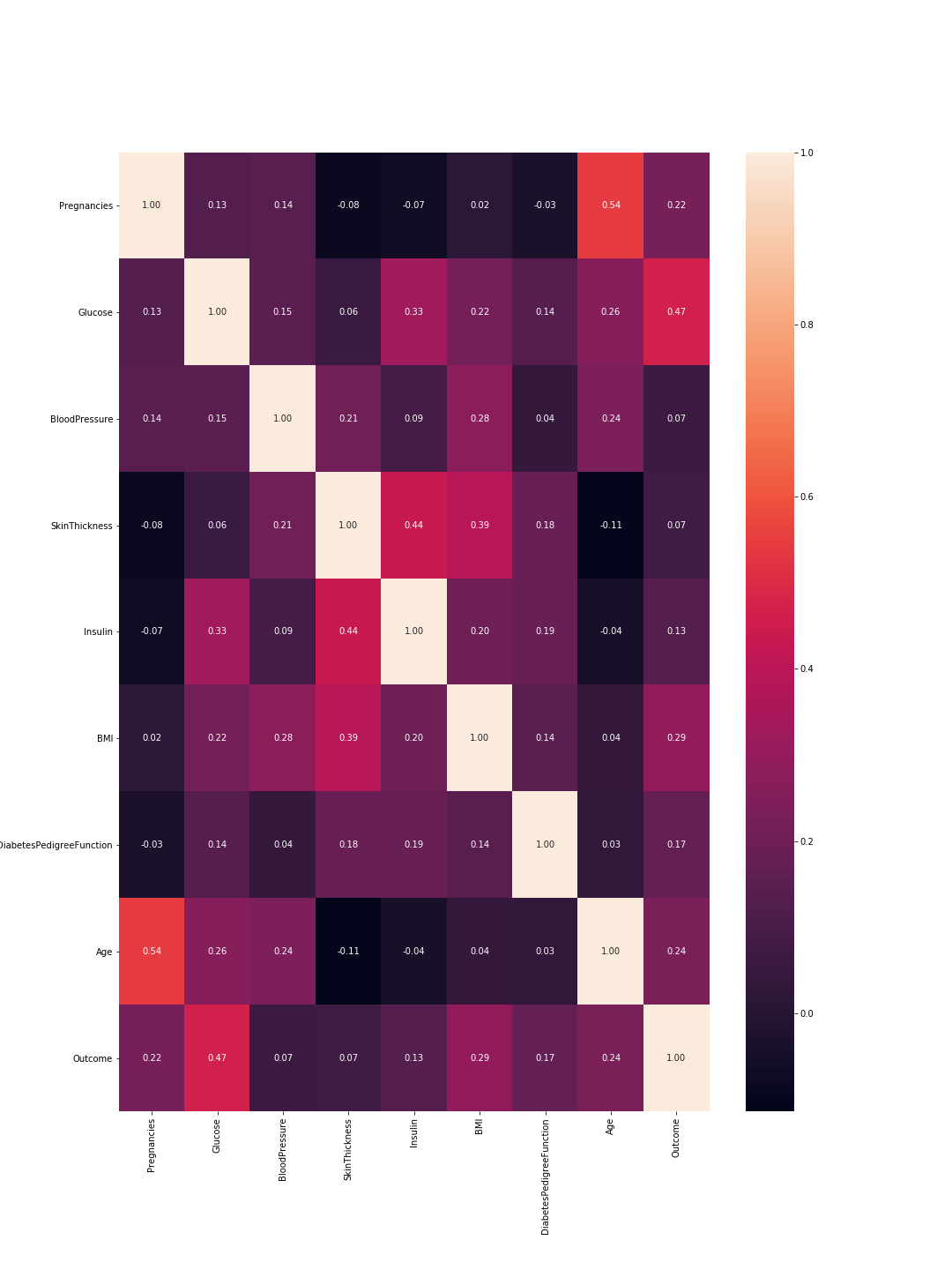
The output is the following correlation matrix:
![enter image description here]()
So here 1 means total correlation and as expected the diagonal is all ones because a feature is totally correlated with its self. Also, the lower the number, the less correlated are the features.
Here we need to consider the feature-to-feature correlations and the outcome-to-feature correlations. Between features: higher correlations mean we can drop one of them. However, high correlation between a feature and the outcome means that the feature is important and holds a lot of information. In our graph, the last line represents the correlation between features and the outcome. Accordingly, the highest values/ most important features are 'Glucose' (0.47) and 'MBI' (0.29). Furthermore, the correlation between these two is relatively low (0.22), which means they are not similar.
We can verify these results using the density plots for each feature with relevance to the outcome. This is not that complex since we only have two outcomes: 0 or 1. So it would look like this in code:
import pandas as pd
from pylab import rcParams
import matplotlib.pyplot as plt
def plot_densities(data):
'''
Plot features densities depending on the outcome values
'''
# change fig size to fit all subplots beautifully
rcParams['figure.figsize'] = 15, 20
# separate data based on outcome values
outcome_0 = data[data['Outcome'] == 0]
outcome_1 = data[data['Outcome'] == 1]
# init figure
fig, axs = plt.subplots(8, 1)
fig.suptitle('Features densities for different outcomes 0/1')
plt.subplots_adjust(left = 0.25, right = 0.9, bottom = 0.1, top = 0.95,
wspace = 0.2, hspace = 0.9)
# plot densities for outcomes
for column_name in names[:-1]:
ax = axs[names.index(column_name)]
#plt.subplot(4, 2, names.index(column_name) + 1)
outcome_0[column_name].plot(kind='density', ax=ax, subplots=True,
sharex=False, color="red", legend=True,
label=column_name + ' for Outcome = 0')
outcome_1[column_name].plot(kind='density', ax=ax, subplots=True,
sharex=False, color="green", legend=True,
label=column_name + ' for Outcome = 1')
ax.set_xlabel(column_name + ' values')
ax.set_title(column_name + ' density')
ax.grid('on')
plt.show()
fig.savefig('densities.png')
# load your data
data = pd.read_csv('diabetes.csv')
names = list(data.columns)
# plot correlation & densities
plot_densities(data)
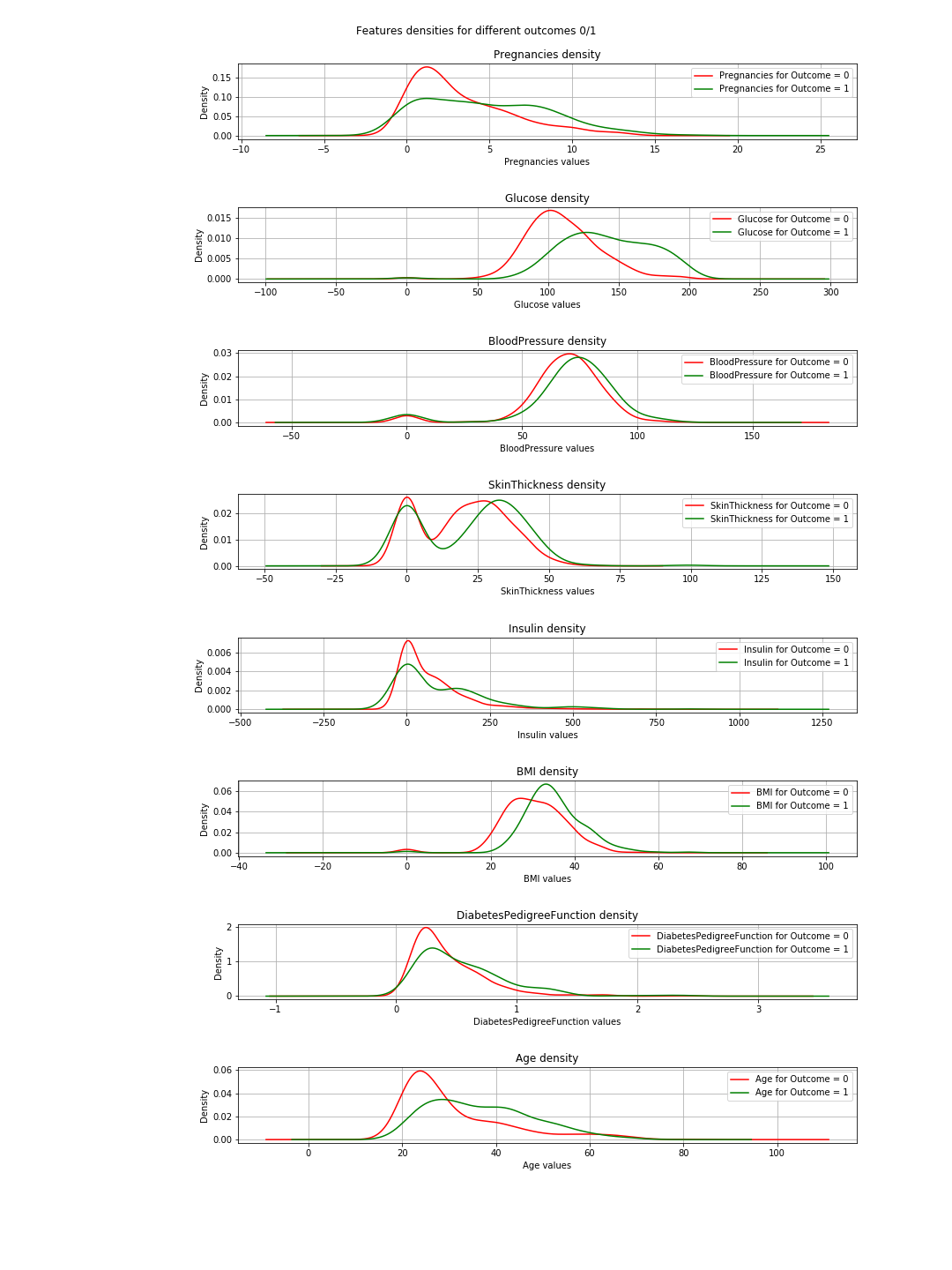
The output is the following density plots:
![enter image description here]()
In the plots, when the green and red curves are almost the same (overlapping), it means the feature does not separate the outcomes. In the case of the 'BMI' you can see some separation (the slight horizontal shift between both curves), and in 'Glucose' this is much clearer (This is in agreement with the correlation values).
=> The conclusion of this: If we have to choose just 2 features, then 'Glucose' and 'MBI' are the ones to choose.
The desired graph
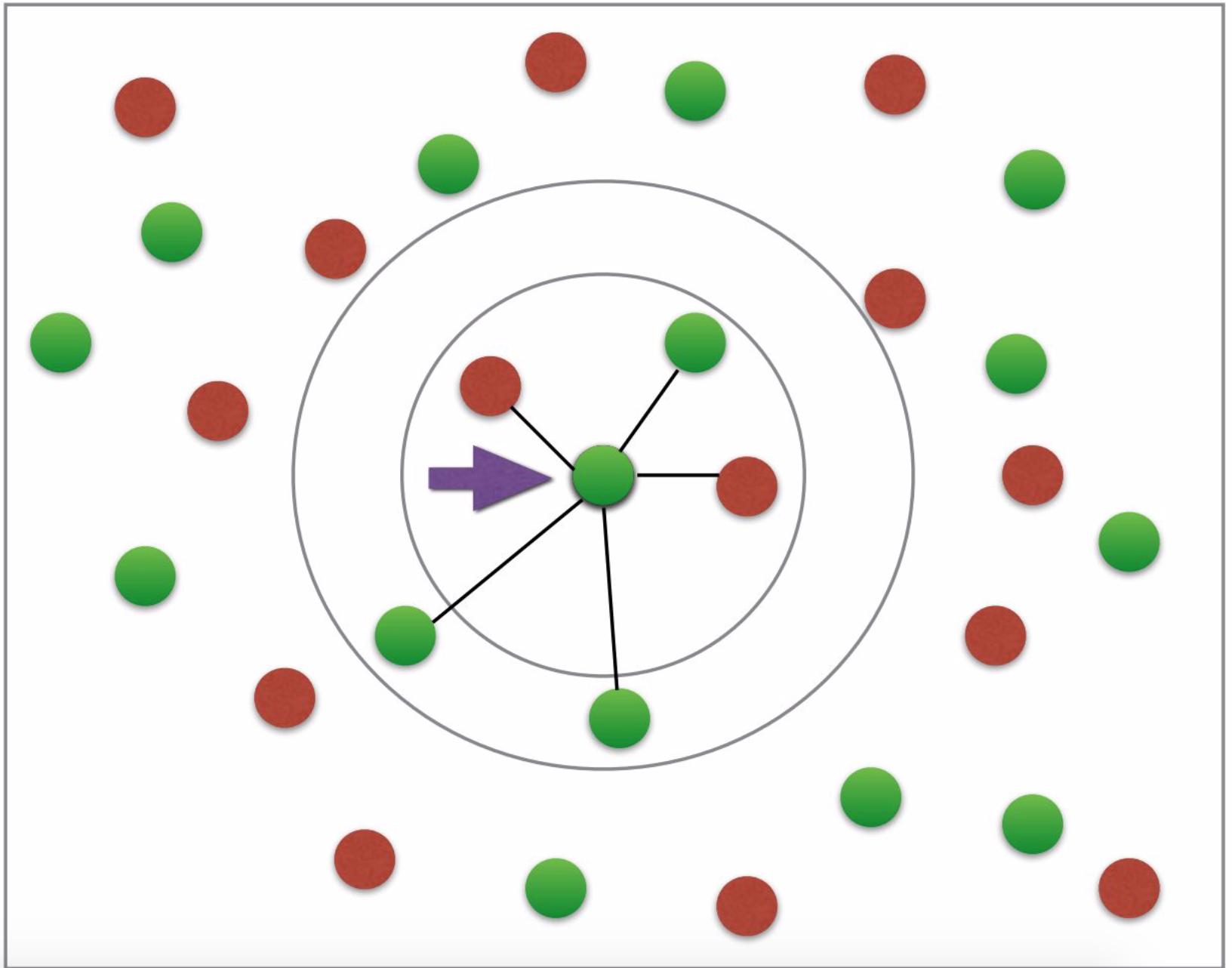
I do not have much to say about this except that the graph represents a basic explanation of the concept of k-nearest neighbor. It is simply not a representation of the classification.
Why fit & predict
Well this is a basic and vital Machine Learning (ML) concept. You have a dataset=[inputs, associated_outputs] and you want to build a ML algorithm that well learn to relate the inputs to their associated_outputs. This is a two step procedure. At first, you train/teach your algorithm how it is done. At this stage, you simply give it the inputs and the answers like you do with a kid. The second step is testing; now that the kid has learned, you want to test her/him. So you give her/him similar inputs and check if her/his answers are correct. Now, you do not want to give her/him the same inputs he learned because even if she/he gives the correct answers, she/he possibly just memorized the answers from the learning phase (this is called overfitting) and so she/he did not learn a thing.
Similarly you do with your algorithm, you first split your dataset into training data and testing data. Then you fit your training data into your algorithm or classifier in this case. This is called the training phase. After that you test how good is your classifier and whether he can classify new data correctly. That is the testing phase. Based on the testing results, you evaluate the performance of your classification using different evaluation-metrics like accuracy for example. The rule of thumbs here is to use 2/3 of the data for the training and 1/3 for the testing.
Plotting 8 features?
The simple answer is no you can't and if you can, please tell me how.
The funny answer: to visualize 8 dimensions, it is easy...just imagine n-dimensions and then let n=8 or just visualize 3-D and scream 8 at it.
The logical answer: So we live in the physical word and the objects we see are 3-dimensional so that is technically kind of the limit. However, you can visualize the 4th dimension as the color like in here you can also use the time as your 5th dimension and make your plot an animation. @Rohan suggested in his answer shapes but his code did not work for me, and I do not see how that would provide a good representation of the algorithm performance. Anyway, colors, time, shapes ... after a while you run out of those and you find yourself stuck. This is one of the reasons people do PCA. You can read about this aspect of the problem under dimensionality-reduction.
So what happens if we settle for 2 features after PCA and then train, test, evaluate and plot?.
Well you can use the following code to achieve that:
import warnings
import numpy as np
import pandas as pd
from pylab import rcParams
import matplotlib.pyplot as plt
from sklearn import neighbors
from matplotlib.colors import ListedColormap
from sklearn.neighbors import KNeighborsClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# filter warnings
warnings.filterwarnings("ignore")
def accuracy(k, X_train, y_train, X_test, y_test):
'''
compute accuracy of the classification based on k values
'''
# instantiate learning model and fit data
knn = KNeighborsClassifier(n_neighbors=k)
knn.fit(X_train, y_train)
# predict the response
pred = knn.predict(X_test)
# evaluate and return accuracy
return accuracy_score(y_test, pred)
def classify_and_plot(X, y):
'''
split data, fit, classify, plot and evaluate results
'''
# split data into training and testing set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.33, random_state = 41)
# init vars
n_neighbors = 5
h = .02 # step size in the mesh
# Create color maps
cmap_light = ListedColormap(['#FFAAAA', '#AAAAFF'])
cmap_bold = ListedColormap(['#FF0000', '#0000FF'])
rcParams['figure.figsize'] = 5, 5
for weights in ['uniform', 'distance']:
# we create an instance of Neighbours Classifier and fit the data.
clf = neighbors.KNeighborsClassifier(n_neighbors, weights=weights)
clf.fit(X_train, y_train)
# Plot the decision boundary. For that, we will assign a color to each
# point in the mesh [x_min, x_max]x[y_min, y_max].
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h),
np.arange(y_min, y_max, h))
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
# Put the result into a color plot
Z = Z.reshape(xx.shape)
fig = plt.figure()
plt.pcolormesh(xx, yy, Z, cmap=cmap_light)
# Plot also the training points, x-axis = 'Glucose', y-axis = "BMI"
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=cmap_bold, edgecolor='k', s=20)
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.title("0/1 outcome classification (k = %i, weights = '%s')" % (n_neighbors, weights))
plt.show()
fig.savefig(weights +'.png')
# evaluate
y_expected = y_test
y_predicted = clf.predict(X_test)
# print results
print('----------------------------------------------------------------------')
print('Classification report')
print('----------------------------------------------------------------------')
print('\n', classification_report(y_expected, y_predicted))
print('----------------------------------------------------------------------')
print('Accuracy = %5s' % round(accuracy(n_neighbors, X_train, y_train, X_test, y_test), 3))
print('----------------------------------------------------------------------')
# load your data
data = pd.read_csv('diabetes.csv')
names = list(data.columns)
# we only take the best two features and prepare them for the KNN classifier
rows_nbr = 30 # data.shape[0]
X_prime = np.array(data.iloc[:rows_nbr, [1,5]])
X = X_prime # preprocessing.scale(X_prime)
y = np.array(data.iloc[:rows_nbr, 8])
# classify, evaluate and plot results
classify_and_plot(X, y)
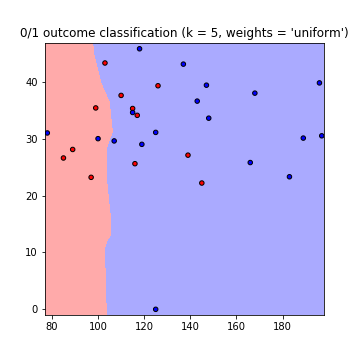
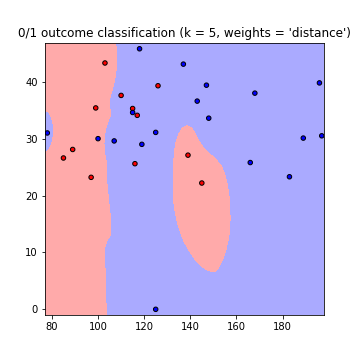
This results in the following plots of the decision boundaries using weights='uniform' and weights='distance' (to read on the difference between both go here):
![enter image description here]()
![enter image description here]()
Note that: x-axis = 'Glucose', y-axis = 'BMI'
Improvements:
K value
What k value to use? how many neighbors to consider. Low k values means less dependence between data, but big values means longer runtimes. So it is a compromise. You can use this code to find the value of k resulting in the highest accuracy:
best_n_neighbours = np.argmax(np.array([accuracy(k, X_train, y_train, X_test, y_test) for k in range(1, int(rows_nbr/2))])) + 1
print('For best accuracy use k = ', best_n_neighbours)
Using more data
So when using all the data you might run into a memory problems (as I did) other then the overfitting issue. You can overcome this by pre-processing your data. Consider this as a scaling and formatting of your data. In code just use:
from sklearn import preprocessing
X = preprocessing.scale(X_prime)
The full code can be found in this gist
 So there are 8 features, plus one "outcome" column.
So there are 8 features, plus one "outcome" column. 
fitandpredictpasses are the plotting. The problem is that you're trying to cram an 8-D plot into 2-D space. This requires a best-fit function, finding the least error between the 2-D distance and the given 8-D distance. – Lustrousimport) commands inside a function, method, or loop. – Lustrous