Disclaimer
I am posting this answer to clear this topic of any misconceptions (as pointed out by @PeterCordes).
Paging
The memory management in Linux (x86 protected mode) uses paging for mapping the physical addresses to a virtualized flat linear address space, from 0x00000000 to 0xFFFFFFFF (on 32-bit), known as the flat memory model. Linux, along with the CPU's MMU (Memory Management Unit), will maintain every virtual and logical address mapped 1:1 to the corresponding physical address. The physical memory is usually split into 4KiB pages, to allow an easier management of memory.
The kernel virtual addresses can be contiguous kernel logical addresses directly mapped into contiguous physical pages; other kernel virtual addresses are fully virtual addresses mapped in not-contiguous physical pages used for large buffer allocations (exceeding the contiguous area on small-memory systems) and/or PAE memory (32-bit only). MMIO ports (Memory-Mapped I/O) are also mapped using kernel virtual addresses.
Every dereferenced address must be a virtual address. Either it is a logical or a fully virtual address, physical RAM and MMIO ports are mapped in the virtual address space prior to use.
The kernel obtains a chunk of virtual memory using kmalloc(), pointed by a virtual address, but more importantly, that is also a kernel logical address, meaning it has direct mapping to contiguous physical pages (thus suitable for DMA). On the other hand, the vmalloc() routine will return a chunk of fully virtual memory, pointed by a virtual address, but only contiguous on the virtual address space and mapped to not-contiguous physical pages.
Kernel logical addresses use a fixed mapping between physical and virtual address space. This means virtually-contiguous regions are by nature also physically contiguous. This is not the case with fully virtual addresses, which point to not-contiguous physical pages.
The user virtual addresses - unlike kernel logical addresses - do not use a fixed mapping between virtual and physical addresses, userland processes make full use of the MMU:
- Only used portions of physical memory are mapped;
- Memory is not-contiguous;
- Memory may be swapped out;
- Memory can be moved;
In more details, physical memory pages of 4KiB are mapped to virtual addresses in the OS page table, each mapping known as a PTE (Page Table Entry). The CPU's MMU will then keep a cache of each recently used PTEs from the OS page table. This caching area, is known as the TLB (Translation Lookaside Buffer). The cr3 register is used to locate the OS page table.
Whenever a virtual address needs to be translated into a physical one, the TLB will be searched. If a match is found (TLB hit), the physical address is returned and accessed. However, if there is no match (TLB miss), the TLB miss handler will look up the page table to see whether a mapping exists (page walk). If one exists, it is written back to the TLB and the faulting instruction is restarted, this
subsequent translation will then find a TLB hit and the memory access will continue. This is known as a minor page fault.
Sometimes, the OS may need to increase the size of physical RAM by moving pages into the hard disk. If a virtual address resolve to a page mapped in the hard disk, the page needs to be loaded in physical RAM prior to be accessed. This is known as a major page fault. The OS page fault handler will then need to find a free page in memory.
The translation process may fail if there is no mapping available for the virtual address, meaning that the virtual address is invalid. This is known as an invalid page fault exception, and a segfault will be issued to the process by the OS page fault handler.
Memory segmentation
Real mode
Real mode still uses a 20-bit segmented memory address space, with 1MiB of addressable memory (0x00000 - 0xFFFFF) and unlimited direct software access to all addressable memory, bus addresses, PMIO ports (Port-Mapped I/O) and peripheral hardware. Real mode provides no memory protection, no privilege levels and no virtualized addresses. Typically, a segment register contains the segment selector value, and the memory operand is an offset value relative to the segment base.
To work around segmentation (C compilers usually only support the flat memory model), C compilers used the unofficial far pointer type to represent a physical address with a segment:offset logical address notation. For instance, the logical address 0x5555:0x0005, after computing 0x5555 * 16 + 0x0005 yields the 20-bit physical address 0x55555, usable in a far pointer as shown below:
char far *ptr; /* declare a far pointer */
ptr = (char far *)0x55555; /* initialize a far pointer */
As of today, most modern x86 CPUs still start in real mode for backwards compatibility and switch to protected mode thereafter.
Protected mode
In protected mode, with the flat memory model, segmentation is unused. The four segments, namely __KERNEL_CS, __KERNEL_DS, __USER_CS, __USER_DS all have their base addresses set to 0. These segments are just legacy baggage from the former x86 model where segmented memory management was used. In protected mode, since all segments base addresses are set to 0, logical addresses are equivalent to linear addresses.
Protected mode with the flat memory model means no segmentation. The only exception where a segment has its base address set to a value other than 0 is when thread-local storage is involved. The FS (and GS on 64-bit) segment registers are used for this purpose.
However, segment registers such as SS (stack segment register), DS (data segment register) or CS (code segment register) are still present and used to store 16-bit segment selectors, which contain indexes to segment descriptors in the LDT and GDT (Local & Global Descriptor Table).
Each instruction that touches memory implicitly uses a segment register. Depending on the context, a particular segment register is used. For instance, the JMP instruction uses CS while PUSH uses SS. Selectors can be loaded into registers with instructions like MOV, the sole exception being the CS register which is only modified by instructions affecting the flow of execution, like CALL or JMP.
The CS register is particularly useful because it keeps track in of the CPL (Current Privilege Level) in its segment selector, thus conserving the privilege level for the present segment. This 2-bit CPL value is always equivalent to the CPU current privilege level.
Memory protection
Paging
The CPU privilege level, also known as the mode bit or protection ring, from 0 to 3, restricts some instructions that can subvert the protection mechanism or cause chaos if allowed in user mode, so they are reserved to the kernel. An attempt to run them outside of ring 0 causes a general-protection fault exception, same scenario when a invalid segment access error occurs (privilege, type, limit, read/write rights). Likewise, any access to memory and MMIO devices is restricted based on privilege level and every attempt to access a protected page without the required privilege level will cause a page fault exception.
The mode bit will be automatically switched from user mode to supervisor mode whenever an interrupt request (IRQ), either software (ie. syscall) or hardware, occurs.
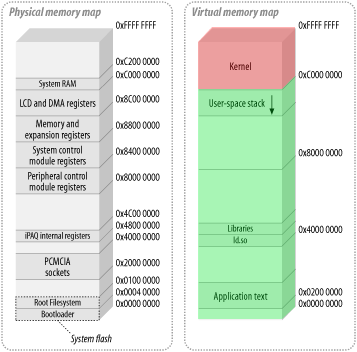
On a 32-bit system, only 4GiB of memory can be effectively addressed, and the memory is split in a 3GiB/1GiB form. Linux (with paging enabled) uses a protection schema known as the higher half kernel where the flat addressing space is divided into two ranges of virtual addresses:
Addresses in the range 0xC0000000 - 0xFFFFFFFF are kernel virtual addresses (red area). The 896MiB range 0xC0000000 - 0xF7FFFFFF directly maps kernel logical addresses 1:1 with kernel physical addresses into the contiguous low-memory pages (using the __pa() and __va() macros). The remaining 128MiB range 0xF8000000 - 0xFFFFFFFF is then used to map virtual addresses for large buffer allocations, MMIO ports (Memory-Mapped I/O) and/or PAE memory into the not-contiguous high-memory pages (using ioremap() and iounmap()).
Addresses in the range 0x00000000 - 0xBFFFFFFF are user virtual addresses (green area), where userland code, data and libraries reside. The mapping can be in not-contiguous low-memory and high-memory pages.
High-memory is only present on 32-bit systems. All memory allocated with kmalloc() has a logical virtual address (with a direct physical mapping); memory allocated by vmalloc() has a fully virtual address (but no direct physical mapping). 64-bit systems have a huge addressing capability hence does not need high-memory, since every page of physical RAM can be effectively addressed.
![Linux memory management]()
The boundary address between the supervisor higher half and the userland lower half is known as TASK_SIZE_MAX in the Linux kernel. The kernel will check that every accessed virtual address from any userland process resides below that boundary, as seen in the code below:
static int fault_in_kernel_space(unsigned long address)
{
/*
* On 64-bit systems, the vsyscall page is at an address above
* TASK_SIZE_MAX, but is not considered part of the kernel
* address space.
*/
if (IS_ENABLED(CONFIG_X86_64) && is_vsyscall_vaddr(address))
return false;
return address >= TASK_SIZE_MAX;
}
If an userland process tries to access a memory address higher than TASK_SIZE_MAX, the do_kern_addr_fault() routine will call the __bad_area_nosemaphore() routine, eventually signaling the faulting task with a SIGSEGV (using get_current() to get the task_struct):
/*
* To avoid leaking information about the kernel page table
* layout, pretend that user-mode accesses to kernel addresses
* are always protection faults.
*/
if (address >= TASK_SIZE_MAX)
error_code |= X86_PF_PROT;
force_sig_fault(SIGSEGV, si_code, (void __user *)address, tsk); /* Kill the process */
Pages also have a privilege bit, known as the User/Supervisor flag, used for SMAP (Supervisor Mode Access Prevention) in addition to the Read/Write flag that SMEP (Supervisor Mode Execution Prevention) uses.
Segmentation
Older architectures using segmentation usually perform segment access verification using the GDT privilege bit for each requested segment. The privilege bit of the requested segment, known as the DPL (Descriptor Privilege Level), is compared to the CPL of the current segment, ensuring that CPL <= DPL. If true, the memory access is then allowed to the requested segment.

mmapandbrk). Because we have a flat memory model, it's just simple integer comparisons, and kernel addresses will never be part of a task's valid virtual address space. – Brandy-EFAULT, so it doesn't matter whether an invalid address for user-space happens to be mapped for the kernel (e.g. callingwrite()on a kernel address that happens to be mapped inside the kernel). All that matters is that valid user-space addresses are still valid in kernel mode, inside a system call. – BrandyTASK_MAXdefined value, not relying on HW but a simple comparison, and emits-EFAULTaccording to this rule. – Meowless /proc/self/mapsto see the mappings for a simple process. Passing an address not part of one of those also needs to return-EFAULT, for example the address0. – Brandy#PFexceptions in hardware because the PTE isn't present + valid (+ writeable), but the kernel doesn't deliver SIGSEGV; it does the copy-on-write or whatever and returns to user-space which will re-run the faulting instruction successfully. This is a "valid" page fault. – Brandy-EFAULTto the process. – Meow-EFAULTreturn value from passing a bad address to a system call. If you actually dereference a bad pointer in userspace, e.g.mov eax, [0], it's not a hard or soft page-fault, it's an invalid page-fault and the kernel delivers aSIGSEGVsignal to your process. The page-fault handler has to sort out whether it's a valid or invalid page fault by checking the address against the logical memory map, the same way the kernel does to decide to return-EFAULTor not. – BrandySIGSEGVto the process (which you can ignore, but then the address will not be addressed whatsoever). – MeowSIGKILLto terminate the process for good ? – MeowSIG_IGN, the kernel doesn't special-case that. It's just a terrible idea, and not much different from catching it and returning from the handler without fixing the problem if that's what user-space chooses to do. But note that another thread could be cross-modifying the machine code of the thread stuck in a SIGSEGV-ignored loop. Or more simply, another thread could make anmmapsystem call that results in the memory access no longer faulting. Or if a debugger is single-stepping the faulting process withptrace, there's no loop. – Brandy