I vectorized the dot product between 2 vectors with SSE 4.2 and AVX 2, as you can see below. The code was compiled with GCC 4.8.4 with the -O2 optimization flag. As expected the performance got better with both (and AVX 2 faster than SSE 4.2), but when I profiled the code with PAPI, I found out that the total number of misses (mainly L1 and L2) increased a lot:
Without Vectorization:
PAPI_L1_TCM: 784,112,091
PAPI_L2_TCM: 195,315,365
PAPI_L3_TCM: 79,362
With SSE 4.2:
PAPI_L1_TCM: 1,024,234,171
PAPI_L2_TCM: 311,541,918
PAPI_L3_TCM: 68,842
With AVX 2:
PAPI_L1_TCM: 2,719,959,741
PAPI_L2_TCM: 1,459,375,105
PAPI_L3_TCM: 108,140
Might there be something wrong with my code or is this kind of behavior normal?
AVX 2 code:
double vec_dotProduct(const vec& vecs, const unsigned int& start_a, const unsigned int& start_b, const int& n) {
double dot = 0;
register int i = 0;
const int loopBound = n-3;
__m256d vsum, vecPi, vecCi, vecQCi;
vsum = _mm256_set1_pd(0);
double * const pA = vecs.x+start_a ;
double * const pB = vecs.x+start_b ;
for( ; i<loopBound ;i+=4){
vecPi = _mm256_loadu_pd(&(pA)[i]);
vecCi = _mm256_loadu_pd(&(pB)[i]);
vecQCi = _mm256_mul_pd(vecPi,vecCi);
vsum = _mm256_add_pd(vsum,vecQCi);
}
vsum = _mm256_hadd_pd(vsum, vsum);
dot = ((double*)&vsum)[0] + ((double*)&vsum)[2];
for( ; i<n; i++)
dot += pA[i] * pB[i];
return dot;
}
SSE 4.2 code:
double vec_dotProduct(const vec& vecs, const unsigned int& start_a, const unsigned int& start_b, const int& n) {
double dot = 0;
register int i = 0;
const int loopBound = n-1;
__m128d vsum, vecPi, vecCi, vecQCi;
vsum = _mm_set1_pd(0);
double * const pA = vecs.x+start_a ;
double * const pB = vecs.x+start_b ;
for( ; i<loopBound ;i+=2){
vecPi = _mm_load_pd(&(pA)[i]);
vecCi = _mm_load_pd(&(pB)[i]);
vecQCi = _mm_mul_pd(vecPi,vecCi);
vsum = _mm_add_pd(vsum,vecQCi);
}
vsum = _mm_hadd_pd(vsum, vsum);
_mm_storeh_pd(&dot, vsum);
for( ; i<n; i++)
dot += pA[i] * pB[i];
return dot;
}
Non-vectorized code:
double dotProduct(const vec& vecs, const unsigned int& start_a, const unsigned int& start_b, const int& n) {
double dot = 0;
register int i = 0;
for (i = 0; i < n; ++i)
{
dot += vecs.x[start_a+i] * vecs.x[start_b+i];
}
return dot;
}
Edit: Assembly of the non-vectorized code:
0x000000000040f9e0 <+0>: mov (%rcx),%r8d
0x000000000040f9e3 <+3>: test %r8d,%r8d
0x000000000040f9e6 <+6>: jle 0x40fa1d <dotProduct(vec const&, unsigned int const&, unsigned int const&, int const&)+61>
0x000000000040f9e8 <+8>: mov (%rsi),%eax
0x000000000040f9ea <+10>: mov (%rdi),%rcx
0x000000000040f9ed <+13>: mov (%rdx),%edi
0x000000000040f9ef <+15>: vxorpd %xmm0,%xmm0,%xmm0
0x000000000040f9f3 <+19>: add %eax,%r8d
0x000000000040f9f6 <+22>: sub %eax,%edi
0x000000000040f9f8 <+24>: nopl 0x0(%rax,%rax,1)
0x000000000040fa00 <+32>: mov %eax,%esi
0x000000000040fa02 <+34>: lea (%rdi,%rax,1),%edx
0x000000000040fa05 <+37>: add $0x1,%eax
0x000000000040fa08 <+40>: vmovsd (%rcx,%rsi,8),%xmm1
0x000000000040fa0d <+45>: cmp %r8d,%eax
0x000000000040fa10 <+48>: vmulsd (%rcx,%rdx,8),%xmm1,%xmm1
0x000000000040fa15 <+53>: vaddsd %xmm1,%xmm0,%xmm0
0x000000000040fa19 <+57>: jne 0x40fa00 <dotProduct(vec const&, unsigned int const&, unsigned int const&, int const&)+32>
0x000000000040fa1b <+59>: repz retq
0x000000000040fa1d <+61>: vxorpd %xmm0,%xmm0,%xmm0
0x000000000040fa21 <+65>: retq
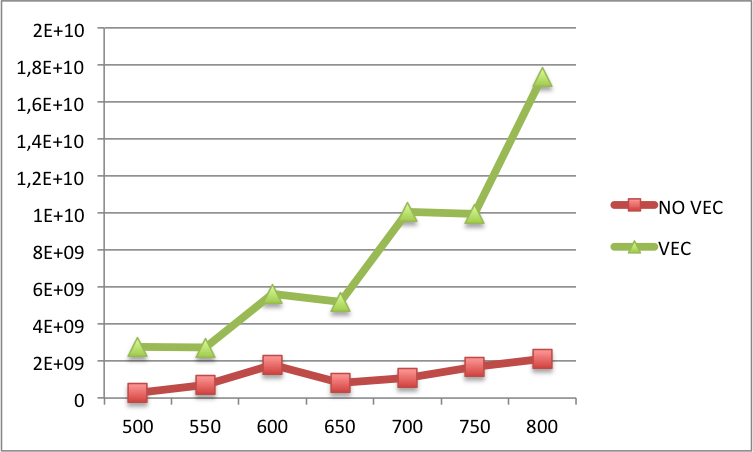
Edit2: Below you can find the comparison of L1 cache misses between the vectorized and the non-vectorized code for bigger N's (N on the x-label and L1 cache misses on the y-label). Basically, for bigger N's there are still more misses in the vectorized version than in the non-vectorized version.
-O2and GCC only vectorizes code with-O3unless the OP also usedftree-vectorize. – Mucousstart_aandstart_aa multiple of32/sizeof(double)=4? I guess we can assume that it's okay for SSE4.2 since you use aligned load for SSE4.2 but not for AVX2. – Mucousn? – Mucousnis 500 and not a multiple of 4. – Martinenis 500 and not a multiple of 4500=4*125. Also, yourloopBoundlogic seems wrong. 16byte alignment is not good enough for AVX, but you can get 32byte alignment either by shifting 16bytes if required or_mm_malloc(or_aligned_mallocdepending on your system, but beware that you must free that with_mm_freeor_aligned_free, respectively). – Accoutermentnmight not be a multiple of 4, but yeah, in this particular case it is. Is it also possible to specify the alignment withnew? – Martinenew. – Accouterment