Just for additional context and intuition, here's an explicit and concrete example of the differences.
Assume you have the following function seen below. (
This label function, will arbitrarily split the values into 'High' and 'Low', based upon the threshold you provide as the parameter (x). )
def label(element, x):
if element > x:
return 'High'
else:
return 'Low'
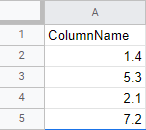
In this example, lets assume our dataframe has one column with random numbers.
![Df with one column that has random numbers]()
If you tried mapping the label function with map:
df['ColumnName'].map(label, x = 0.8)
You will result with the following error:
TypeError: map() got an unexpected keyword argument 'x'
Now take the same function and use apply, and you'll see that it works:
df['ColumnName'].apply(label, x=0.8)
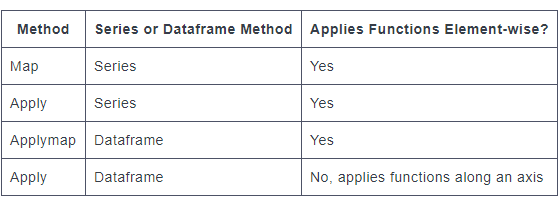
Series.apply() can take additional arguments element-wise, while the Series.map() method will return an error.
Now, if you're trying to apply the same function to several columns in your dataframe simultaneously, DataFrame.applymap() is used.
df[['ColumnName','ColumnName2','ColumnName3','ColumnName4']].applymap(label)
Lastly, you can also use the apply() method on a dataframe, but the DataFrame.apply() method has different capabilities. Instead of applying functions element-wise, the df.apply() method applies functions along an axis, either column-wise or row-wise. When we create a function to use with df.apply(), we set it up to accept a series, most commonly a column.
Here is an example:
df.apply(pd.value_counts)
When we applied the pd.value_counts function to the dataframe, it calculated the value counts for all the columns.
Notice, and this is very important, when we used the df.apply() method to transform multiple columns. This is only possible because the pd.value_counts function operates on a series. If we tried to use the df.apply() method to apply a function that works element-wise to multiple columns, we'd get an error:
For example:
def label(element):
if element > 1:
return 'High'
else:
return 'Low'
df[['ColumnName','ColumnName2','ColumnName3','ColumnName4']].apply(label)
This will result with the following error:
ValueError: ('The truth value of a Series is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().', u'occurred at index Economy')
In general, we should only use the apply() method when a vectorized function does not exist. Recall that pandas uses vectorization, the process of applying operations to whole series at once, to optimize performance. When we use the apply() method, we're actually looping through rows, so a vectorized method can perform an equivalent task faster than the apply() method.
![apply, applymap, map summarization]()
Here are some examples of vectorized functions that already exist that you do NOT want to recreate using any type of apply/map methods:
- Series.str.split() Splits each element in the Series
- Series.str.strip() Strips whitespace from each string in the Series.
- Series.str.lower() Converts strings in the Series to lowercase.
- Series.str.upper() Converts strings in the Series to uppercase.
- Series.str.get() Retrieves the ith element of each element in the Series.
- Series.str.replace() Replaces a regex or string in the Series with another string
- Series.str.cat() Concatenates strings in a Series.
- Series.str.extract() Extracts substrings from the Series matching a regex pattern.
DataFrame.pipe()method to the comparison? – Pleader