In the Python library Statsmodels, you can print out the regression results with print(results.summary()), how can I print out the summary of more than one regressions in one table, for better comparison?
A linear regression, code taken from statsmodels documentation:
nsample = 100
x = np.linspace(0, 10, 100)
X = np.column_stack((x, x**2))
beta = np.array([0.1, 10])
e = np.random.normal(size=nsample)
y = np.dot(X, beta) + e
model = sm.OLS(y, X)
results_noconstant = model.fit()
Then I add a constant to the model and run the regression again:
beta = np.array([1, 0.1, 10])
X = sm.add_constant(X)
y = np.dot(X, beta) + e
model = sm.OLS(y, X)
results_withconstant = model.fit()
I'd like to see the summaries of results_noconstant and results_withconstant printed out in one table. This should be a very useful function, but I didn't find any instruction about this in the statsmodels documentation.
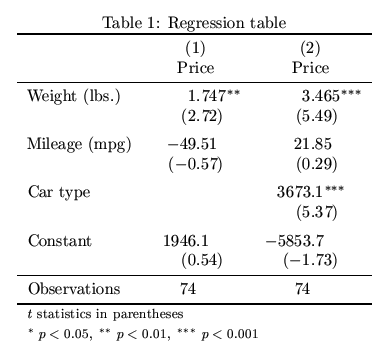
EDIT: The regression table I had in mind would be something like this, I wonder whether there is ready-made functionality to do this.
{kind=link}