What are the core architectural differences between these technologies?
Also, what use cases are generally more appropriate for each?
What are the core architectural differences between these technologies?
Also, what use cases are generally more appropriate for each?
Now that the question scope has been corrected, I might add something in this regard as well:
There are many comparisons between Apache Solr and Elasticsearch available, so I'll reference those I found most useful myself, i.e. covering the most important aspects:
Bob Yoplait already linked kimchy's answer to ElasticSearch, Sphinx, Lucene, Solr, Xapian. Which fits for which usage?, which summarizes the reasons why he went ahead and created ElasticSearch, which in his opinion provides a much superior distributed model and ease of use in comparison to Solr.
Ryan Sonnek's Realtime Search: Solr vs Elasticsearch provides an insightful analysis/comparison and explains why he switched from Solr to ElasticSeach, despite being a happy Solr user already - he summarizes this as follows:
Solr may be the weapon of choice when building standard search applications, but Elasticsearch takes it to the next level with an architecture for creating modern realtime search applications. Percolation is an exciting and innovative feature that singlehandedly blows Solr right out of the water. Elasticsearch is scalable, speedy and a dream to integrate with. Adios Solr, it was nice knowing you. [emphasis mine]
Advantages:
- Elasticsearch is distributed. No separate project required. Replicas are near real-time too, which is called "Push replication".
- ElasticSearch fully supports the near real-time search of Apache Lucene.
- Handling multitenancy is not a special configuration, where with Solr a more advanced setup is necessary.
- ElasticSearch introduces the concept of the Gateway, which makes full backups easier.
Disadvantages:
Only one main developer[not applicable anymore according to the current elasticsearch GitHub organization, besides having a pretty active committer base in the first place]No autowarming feature[not applicable anymore according to the new Index Warmup API]
They are completely different technologies addressing completely different use cases, thus cannot be compared at all in any meaningful way:
Apache Solr - Apache Solr offers Lucene's capabilities in an easy to use, fast search server with additional features like faceting, scalability and much more
Amazon ElastiCache - Amazon ElastiCache is a web service that makes it easy to deploy, operate, and scale an in-memory cache in the cloud.
Please note that Amazon ElastiCache is protocol-compliant with Memcached, a widely adopted memory object caching system, so code, applications, and popular tools that you use today with existing Memcached environments will work seamlessly with the service (see Memcached for details).
[emphasis mine]
Maybe this has been confused with the following two related technologies one way or another:
Elasticsearch - It is an Open Source (Apache 2), Distributed, RESTful, Search Engine built on top of Apache Lucene.
Amazon CloudSearch - Amazon CloudSearch is a fully-managed search service in the cloud that allows customers to easily integrate fast and highly scalable search functionality into their applications.
The Solr and Elasticsearch offerings sound strikingly similar at first sight, and both use the same backend search engine, namely Apache Lucene.
While Solr is older, quite versatile and mature and widely used accordingly, ElasticSearch has been developed specifically to address Solr shortcomings with scalability requirements in modern cloud environments, which are hard(er) to address with Solr.
As such it would probably be most useful to compare ElasticSearch with the recently introduced Amazon CloudSearch (see the introductory post Start Searching in One Hour for Less Than $100 / Month), because both claim to cover the same use cases in principle.
I see some of the above answers are now a bit out of date. From my perspective, and I work with both Solr(Cloud and non-Cloud) and ElasticSearch on a daily basis, here are some interesting differences:
For more thorough coverage of Solr vs. ElasticSearch topic have a look at https://sematext.com/blog/solr-vs-elasticsearch-part-1-overview/ . This is the first post in the series of posts from Sematext doing direct and neutral Solr vs. ElasticSearch comparison. Disclosure: I work at Sematext.
I see that a lot of folks here have answered this ElasticSearch vs Solr question in terms of features and functionality but I don't see much discussion here (or elsewhere) regarding how they compare in terms of performance.
That is why I decided to conduct my own investigation. I took an already coded heterogenous data source micro-service that already used Solr for term search. I switched out Solr for ElasticSearch then I ran both versions on AWS with an already coded load test application and captured the performance metrics for subsequent analysis.
Here is what I found. ElasticSearch had 13% higher throughput when it came to indexing documents but Solr was ten times faster. When it came to querying for documents, Solr had five times more throughput and was five times faster than ElasticSearch.
Since the long history of Apache Solr, I think one strength of the Solr is its ecosystem. There are many Solr plugins for different types of data and purposes.

Search platform in the following layers from bottom to top:
Reference article : Enterprise search
I have been working on both solr and elastic search for .Net applications. The major difference what i have faced is
Elastic search :
Solr :
I have created a table of major differences between elasticsearch and Solr and splunk, you can use it as 2016 update: 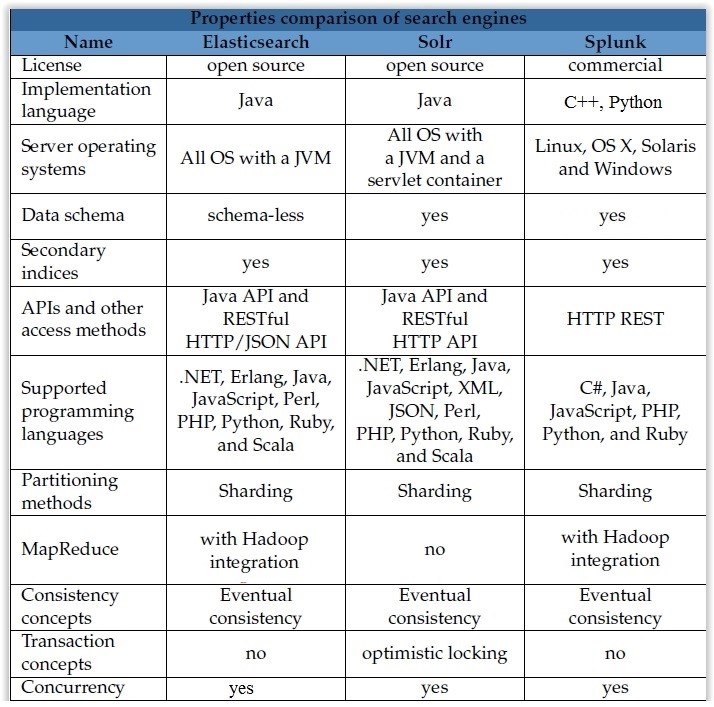
While all of the above links have merit, and have benefited me greatly in the past, as a linguist "exposed" to various Lucene search engines for the last 15 years, I have to say that elastic-search development is very fast in Python. That being said, some of the code felt non-intuitive to me. So, I reached out to one component of the ELK stack, Kibana, from an open source perspective, and found that I could generate the somewhat cryptic code of elasticsearch very easily in Kibana. Also, I could pull Chrome Sense es queries into Kibana as well. If you use Kibana to evaluate es, it will further speed up your evaluation. What took hours to run on other platforms was up and running in JSON in Sense on top of elasticsearch (RESTful interface) in a few minutes at worst (largest data sets); in seconds at best. The documentation for elasticsearch, while 700+ pages, didn't answer questions I had that normally would be resolved in SOLR or other Lucene documentation, which obviously took more time to analyze. Also, you may want to take a look at Aggregates in elastic-search, which have taken Faceting to a new level.
Bigger picture: if you're doing data science, text analytics, or computational linguistics, elasticsearch has some ranking algorithms that seem to innovate well in the information retrieval area. If you're using any TF/IDF algorithms, Text Frequency/Inverse Document Frequency, elasticsearch extends this 1960's algorithm to a new level, even using BM25, Best Match 25, and other Relevancy Ranking algorithms. So, if you are scoring or ranking words, phrases or sentences, elasticsearch does this scoring on the fly, without the large overhead of other data analytics approaches that take hours--another elasticsearch time savings. With es, combining some of the strengths of bucketing from aggregations with the real-time JSON data relevancy scoring and ranking, you could find a winning combination, depending on either your agile (stories) or architectural(use cases) approach.
Note: did see a similar discussion on aggregations above, but not on aggregations and relevancy scoring--my apology for any overlap. Disclosure: I don't work for elastic and won't be able to benefit in the near future from their excellent work due to a different architecural path, unless I do some charity work with elasticsearch, which wouldn't be a bad idea
If you are already using SOLR, remain stick to it. If you are starting up, go for Elastic search.
Maximum major issues have been fixed in SOLR and it is quite mature.
Imagine the use case:
Idea to have individual ES instance per each index - is huge overhead in this case.
Based on my experience, this kind of use case is very complex to support with Elasticsearch.
Why?
FIRST.
The major problem is fundamental back compatibility disregard.
Breaking changes are so cool! (Note: imagine SQL-server which require you to do small change in all your SQL-statements, when upgraded... can't imagine it. But for ES it's normal)
Deprecations which will dropped in next major release are so sexy! (Note: you know, Java contain some deprecations, which 20+ years old, but still working in actual Java version...)
And not only that, sometimes you even have something which nowhere documented (personally came across only once but... )
So. If you want to upgrade ES (because you need new features for some app or you want to get bug fixes) - you are in hell. Especially if it is about major version upgrade.
Client API will not back compatible. Index settings will not back compatible. And upgrade all app/services same moment with ES upgrade is not realistic.
But you must do it time to time. No other way.
Existing indexes is automatically upgraded? - Yes. But it not help you when you will need to change some old-index settings.
To live with that, you need constantly invest a lot of power in ... forward compatibility of you apps/services with future releases of ES. Or you need to build(and anyway constantly support) some kind of middleware between you app/services and ES, which provide you back compatible client API. (And, you can't use Transport Client (because it required jar upgrade for every minor version ES upgrade), and this fact do not make your life easier)
Is it looks simple & cheap? No, it's not. Far from it. Continuous maintenance of complex infrastructure which based on ES, is way to expensive in all possible senses.
SECOND. Simple API ? Well... no really. When you is really using complex conditions and aggregations.... JSON-request with 5 nested levels is whatever, but not simple.
Unfortunately, I have no experience with SOLR, can't say anything about it.
But Sphinxsearch is much better it this scenario, becasue of totally back compatible SphinxQL.
Note: Sphinxsearch/Manticore are indeed interesting. It's not Lucine based, and as result seriously different. Contain several unique features from the box which ES do not have and crazy fast with small/middle size indexes.
I have use Elasticsearch for 3 years and Solr for about a month, I feel elasticsearch cluster is quite easy to install as compared to Solr installation. Elasticsearch has a pool of help documents with great explanation. One of the use case I was stuck up with Histogram Aggregation which was available in ES however not found in Solr.
Add an nested document in solr very complex and nested data search also very complex. but Elastic Search easy to add nested document and search
I only use Elastic-search. Since I found solr is very hard to start. Elastic-search's features:
© 2022 - 2024 — McMap. All rights reserved.