Given:
[
{"name": "Tom", "age": 10},
{"name": "Mark", "age": 5},
{"name": "Pam", "age": 7}
]
How do I search by name == "Pam" to retrieve the corresponding dictionary below?
{"name": "Pam", "age": 7}
Given:
[
{"name": "Tom", "age": 10},
{"name": "Mark", "age": 5},
{"name": "Pam", "age": 7}
]
How do I search by name == "Pam" to retrieve the corresponding dictionary below?
{"name": "Pam", "age": 7}
You can use a generator expression:
>>> dicts = [
... { "name": "Tom", "age": 10 },
... { "name": "Mark", "age": 5 },
... { "name": "Pam", "age": 7 },
... { "name": "Dick", "age": 12 }
... ]
>>> next(item for item in dicts if item["name"] == "Pam")
{'age': 7, 'name': 'Pam'}
If you need to handle the item not being there, then you can do what user Matt suggested in his comment and provide a default using a slightly different API:
next((item for item in dicts if item["name"] == "Pam"), None)
And to find the index of the item, rather than the item itself, you can enumerate() the list:
next((i for i, item in enumerate(dicts) if item["name"] == "Pam"), None)
[item for item in dicts if item["name"] == "Pam"][0]? –
Infeld upper() to both strings before comparing them, although of course there are many other ways to do it. –
Horrific dicts.index(next(item for item in dicts if item["name"] == "Pam"))? –
Canaveral enumerate() to generate a running index: next(i for i, item in enumerate(dicts) if item["name"] == "Pam"). –
Exo next((item for item in dicts if item.get("name") == "Pam"), None) –
Oversee This looks to me the most pythonic way:
people = [
{'name': "Tom", 'age': 10},
{'name': "Mark", 'age': 5},
{'name': "Pam", 'age': 7}
]
filter(lambda person: person['name'] == 'Pam', people)
result (returned as a list in Python 2):
[{'age': 7, 'name': 'Pam'}]
Note: In Python 3, a filter object is returned. So the python3 solution would be:
list(filter(lambda person: person['name'] == 'Pam', people))
len(), you need to call list() on the result first. Or: #19182688 –
Maisel r is a list –
Maggiore next(filter(lambda x: x['name'] == 'Pam', dicts)) –
Xylograph @Frédéric Hamidi's answer is great. In Python 3.x the syntax for .next() changed slightly. Thus a slight modification:
>>> dicts = [
{ "name": "Tom", "age": 10 },
{ "name": "Mark", "age": 5 },
{ "name": "Pam", "age": 7 },
{ "name": "Dick", "age": 12 }
]
>>> next(item for item in dicts if item["name"] == "Pam")
{'age': 7, 'name': 'Pam'}
As mentioned in the comments by @Matt, you can add a default value as such:
>>> next((item for item in dicts if item["name"] == "Pam"), False)
{'name': 'Pam', 'age': 7}
>>> next((item for item in dicts if item["name"] == "Sam"), False)
False
>>>
You can use a list comprehension:
def search(name, people):
return [element for element in people if element['name'] == name]
age to the function def search2(name, age, people): and don't forget to pass this argument, as well =). I've just tried two conditions and it works! –
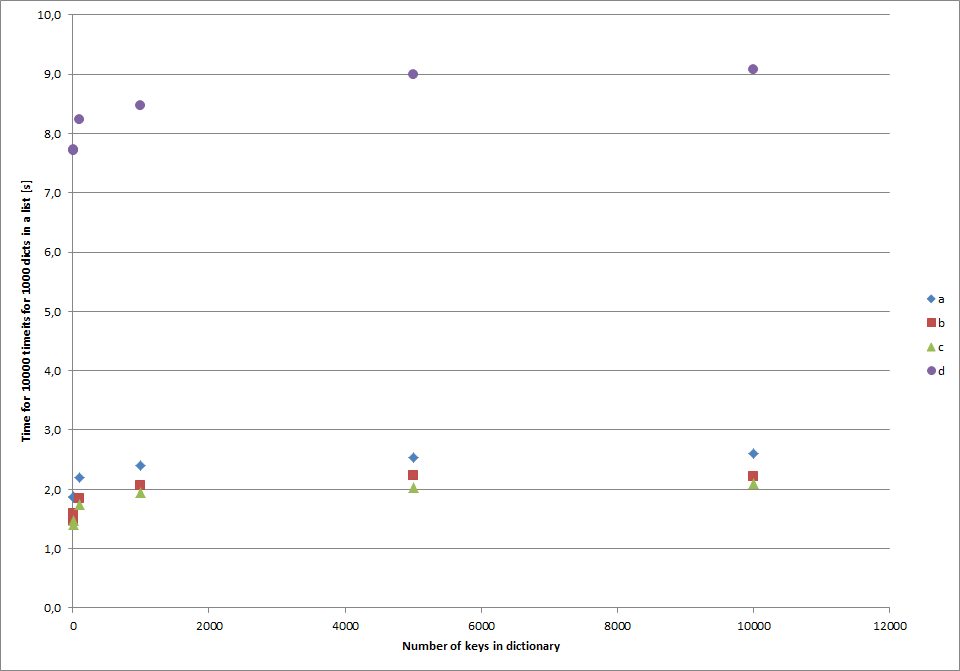
Holiday I tested various methods to go through a list of dictionaries and return the dictionaries where key x has a certain value.
Results:
All tests done with Python 3.6.4, W7x64.
from random import randint
from timeit import timeit
list_dicts = []
for _ in range(1000): # number of dicts in the list
dict_tmp = {}
for i in range(10): # number of keys for each dict
dict_tmp[f"key{i}"] = randint(0,50)
list_dicts.append( dict_tmp )
def a():
# normal iteration over all elements
for dict_ in list_dicts:
if dict_["key3"] == 20:
pass
def b():
# use 'generator'
for dict_ in (x for x in list_dicts if x["key3"] == 20):
pass
def c():
# use 'list'
for dict_ in [x for x in list_dicts if x["key3"] == 20]:
pass
def d():
# use 'filter'
for dict_ in filter(lambda x: x['key3'] == 20, list_dicts):
pass
Results:
1.7303 # normal list iteration
1.3849 # generator expression
1.3158 # list comprehension
7.7848 # filter
c() would be that much faster than simply iterating over the list a() –
Maffick people = [
{'name': "Tom", 'age': 10},
{'name': "Mark", 'age': 5},
{'name': "Pam", 'age': 7}
]
def search(name):
for p in people:
if p['name'] == name:
return p
search("Pam")
def search(list, key, value): for item in list: if item[key] == value: return item –
Somme Have you ever tried out the pandas package? It's perfect for this kind of search task and optimized too.
import pandas as pd
listOfDicts = [
{"name": "Tom", "age": 10},
{"name": "Mark", "age": 5},
{"name": "Pam", "age": 7}
]
# Create a data frame, keys are used as column headers.
# Dict items with the same key are entered into the same respective column.
df = pd.DataFrame(listOfDicts)
# The pandas dataframe allows you to pick out specific values like so:
df2 = df[ (df['name'] == 'Pam') & (df['age'] == 7) ]
# Alternate syntax, same thing
df2 = df[ (df.name == 'Pam') & (df.age == 7) ]
I've added a little bit of benchmarking below to illustrate pandas' faster runtimes on a larger scale i.e. 100k+ entries:
setup_large = 'dicts = [];\
[dicts.extend(({ "name": "Tom", "age": 10 },{ "name": "Mark", "age": 5 },\
{ "name": "Pam", "age": 7 },{ "name": "Dick", "age": 12 })) for _ in range(25000)];\
from operator import itemgetter;import pandas as pd;\
df = pd.DataFrame(dicts);'
setup_small = 'dicts = [];\
dicts.extend(({ "name": "Tom", "age": 10 },{ "name": "Mark", "age": 5 },\
{ "name": "Pam", "age": 7 },{ "name": "Dick", "age": 12 }));\
from operator import itemgetter;import pandas as pd;\
df = pd.DataFrame(dicts);'
method1 = '[item for item in dicts if item["name"] == "Pam"]'
method2 = 'df[df["name"] == "Pam"]'
import timeit
t = timeit.Timer(method1, setup_small)
print('Small Method LC: ' + str(t.timeit(100)))
t = timeit.Timer(method2, setup_small)
print('Small Method Pandas: ' + str(t.timeit(100)))
t = timeit.Timer(method1, setup_large)
print('Large Method LC: ' + str(t.timeit(100)))
t = timeit.Timer(method2, setup_large)
print('Large Method Pandas: ' + str(t.timeit(100)))
#Small Method LC: 0.000191926956177
#Small Method Pandas: 0.044392824173
#Large Method LC: 1.98827004433
#Large Method Pandas: 0.324505090714
To add just a tiny bit to @FrédéricHamidi.
In case you are not sure a key is in the the list of dicts, something like this would help:
next((item for item in dicts if item.get("name") and item["name"] == "Pam"), None)
item.get("name") == "Pam" –
Kidskin One simple way using list comprehensions is , if l is the list
l = [
{"name": "Tom", "age": 10},
{"name": "Mark", "age": 5},
{"name": "Pam", "age": 7}
]
then
[d['age'] for d in l if d['name']=='Tom']
def dsearch(lod, **kw):
return filter(lambda i: all((i[k] == v for (k, v) in kw.items())), lod)
lod=[{'a':33, 'b':'test2', 'c':'a.ing333'},
{'a':22, 'b':'ihaha', 'c':'fbgval'},
{'a':33, 'b':'TEst1', 'c':'s.ing123'},
{'a':22, 'b':'ihaha', 'c':'dfdvbfjkv'}]
list(dsearch(lod, a=22))
[{'a': 22, 'b': 'ihaha', 'c': 'fbgval'},
{'a': 22, 'b': 'ihaha', 'c': 'dfdvbfjkv'}]
list(dsearch(lod, a=22, b='ihaha'))
[{'a': 22, 'b': 'ihaha', 'c': 'fbgval'},
{'a': 22, 'b': 'ihaha', 'c': 'dfdvbfjkv'}]
list(dsearch(lod, a=22, c='fbgval'))
[{'a': 22, 'b': 'ihaha', 'c': 'fbgval'}]
You can achieve this with the usage of filter and next methods in Python.
filter method filters the given sequence and returns an iterator.
next method accepts an iterator and returns the next element in the list.
So you can find the element by,
my_dict = [
{"name": "Tom", "age": 10},
{"name": "Mark", "age": 5},
{"name": "Pam", "age": 7}
]
next(filter(lambda obj: obj.get('name') == 'Pam', my_dict), None)
and the output is,
{'name': 'Pam', 'age': 7}
Note: The above code will return None incase if the name we are searching is not found.
Simply using list comprehension:
[i for i in dct if i['name'] == 'Pam'][0]
Sample code:
dct = [
{'name': 'Tom', 'age': 10},
{'name': 'Mark', 'age': 5},
{'name': 'Pam', 'age': 7}
]
print([i for i in dct if i['name'] == 'Pam'][0])
> {'age': 7, 'name': 'Pam'}
Put the accepted answer in a function to easy re-use
def get_item(collection, key, target):
return next((item for item in collection if item[key] == target), None)
Or also as a lambda
get_item_lambda = lambda collection, key, target : next((item for item in collection if item[key] == target), None)
Result
key = "name"
target = "Pam"
print(get_item(target_list, key, target))
print(get_item_lambda(target_list, key, target))
#{'name': 'Pam', 'age': 7}
#{'name': 'Pam', 'age': 7}
KeyErrordef get_item(collection, key, target):
return next((item for item in collection if item.get(key, None) == target), None)
get_item_lambda = lambda collection, key, target : next((item for item in collection if item.get(key, None) == target), None)
This is a general way of searching a value in a list of dictionaries:
def search_dictionaries(key, value, list_of_dictionaries):
return [element for element in list_of_dictionaries if element[key] == value]
names = [{'name':'Tom', 'age': 10}, {'name': 'Mark', 'age': 5}, {'name': 'Pam', 'age': 7}]
resultlist = [d for d in names if d.get('name', '') == 'Pam']
first_result = resultlist[0]
This is one way...
dicts=[
{"name": "Tom", "age": 10},
{"name": "Mark", "age": 5},
{"name": "Pam", "age": 7}
]
from collections import defaultdict
dicts_by_name=defaultdict(list)
for d in dicts:
dicts_by_name[d['name']]=d
print dicts_by_name['Tom']
#output
#>>>
#{'age': 10, 'name': 'Tom'}
You can try this:
''' lst: list of dictionaries '''
lst = [{"name": "Tom", "age": 10}, {"name": "Mark", "age": 5}, {"name": "Pam", "age": 7}]
search = raw_input("What name: ") #Input name that needs to be searched (say 'Pam')
print [ lst[i] for i in range(len(lst)) if(lst[i]["name"]==search) ][0] #Output
>>> {'age': 7, 'name': 'Pam'}
My first thought would be that you might want to consider creating a dictionary of these dictionaries ... if, for example, you were going to be searching it more a than small number of times.
However that might be a premature optimization. What would be wrong with:
def get_records(key, store=dict()):
'''Return a list of all records containing name==key from our store
'''
assert key is not None
return [d for d in store if d['name']==key]
Most (if not all) implementations proposed here have two flaws:
An updated proposition:
def find_first_in_list(objects, **kwargs):
return next((obj for obj in objects if
len(set(obj.keys()).intersection(kwargs.keys())) > 0 and
all([obj[k] == v for k, v in kwargs.items() if k in obj.keys()])),
None)
Maybe not the most pythonic, but at least a bit more failsafe.
Usage:
>>> obj1 = find_first_in_list(list_of_dict, name='Pam', age=7)
>>> obj2 = find_first_in_list(list_of_dict, name='Pam', age=27)
>>> obj3 = find_first_in_list(list_of_dict, name='Pam', address='nowhere')
>>>
>>> print(obj1, obj2, obj3)
{"name": "Pam", "age": 7}, None, {"name": "Pam", "age": 7}
The gist.
Here is a comparison using iterating throuhg list, using filter+lambda or refactoring(if needed or valid to your case) your code to dict of dicts rather than list of dicts
import time
# Build list of dicts
list_of_dicts = list()
for i in range(100000):
list_of_dicts.append({'id': i, 'name': 'Tom'})
# Build dict of dicts
dict_of_dicts = dict()
for i in range(100000):
dict_of_dicts[i] = {'name': 'Tom'}
# Find the one with ID of 99
# 1. iterate through the list
lod_ts = time.time()
for elem in list_of_dicts:
if elem['id'] == 99999:
break
lod_tf = time.time()
lod_td = lod_tf - lod_ts
# 2. Use filter
f_ts = time.time()
x = filter(lambda k: k['id'] == 99999, list_of_dicts)
f_tf = time.time()
f_td = f_tf- f_ts
# 3. find it in dict of dicts
dod_ts = time.time()
x = dict_of_dicts[99999]
dod_tf = time.time()
dod_td = dod_tf - dod_ts
print 'List of Dictionries took: %s' % lod_td
print 'Using filter took: %s' % f_td
print 'Dict of Dicts took: %s' % dod_td
And the output is this:
List of Dictionries took: 0.0099310874939
Using filter took: 0.0121960639954
Dict of Dicts took: 4.05311584473e-06
Conclusion: Clearly having a dictionary of dicts is the most efficient way to be able to search in those cases, where you know say you will be searching by id's only. interestingly using filter is the slowest solution.
I would create a dict of dicts like so:
names = ["Tom", "Mark", "Pam"]
ages = [10, 5, 7]
my_d = {}
for i, j in zip(names, ages):
my_d[i] = {"name": i, "age": j}
or, using exactly the same info as in the posted question:
info_list = [{"name": "Tom", "age": 10}, {"name": "Mark", "age": 5}, {"name": "Pam", "age": 7}]
my_d = {}
for d in info_list:
my_d[d["name"]] = d
Then you could do my_d["Pam"] and get {"name": "Pam", "age": 7}
Ducks will be a lot faster than a list comprehension or filter. It builds an index on your objects so lookups don't need to scan every item.
pip install ducks
from ducks import Dex
dicts = [
{"name": "Tom", "age": 10},
{"name": "Mark", "age": 5},
{"name": "Pam", "age": 7}
]
# Build the index
dex = Dex(dicts, {'name': str, 'age': int})
# Find matching objects
dex[{'name': 'Pam', 'age': 7}]
Result: [{'name': 'Pam', 'age': 7}]
Short and multi words search:
selected_items=[item for item in items if item['name'] in ['Mark','Pam']]
You have to go through all elements of the list. There is not a shortcut!
Unless somewhere else you keep a dictionary of the names pointing to the items of the list, but then you have to take care of the consequences of popping an element from your list.
I found this thread when I was searching for an answer to the same question. While I realize that it's a late answer, I thought I'd contribute it in case it's useful to anyone else:
def find_dict_in_list(dicts, default=None, **kwargs):
"""Find first matching :obj:`dict` in :obj:`list`.
:param list dicts: List of dictionaries.
:param dict default: Optional. Default dictionary to return.
Defaults to `None`.
:param **kwargs: `key=value` pairs to match in :obj:`dict`.
:returns: First matching :obj:`dict` from `dicts`.
:rtype: dict
"""
rval = default
for d in dicts:
is_found = False
# Search for keys in dict.
for k, v in kwargs.items():
if d.get(k, None) == v:
is_found = True
else:
is_found = False
break
if is_found:
rval = d
break
return rval
if __name__ == '__main__':
# Tests
dicts = []
keys = 'spam eggs shrubbery knight'.split()
start = 0
for _ in range(4):
dct = {k: v for k, v in zip(keys, range(start, start+4))}
dicts.append(dct)
start += 4
# Find each dict based on 'spam' key only.
for x in range(len(dicts)):
spam = x*4
assert find_dict_in_list(dicts, spam=spam) == dicts[x]
# Find each dict based on 'spam' and 'shrubbery' keys.
for x in range(len(dicts)):
spam = x*4
assert find_dict_in_list(dicts, spam=spam, shrubbery=spam+2) == dicts[x]
# Search for one correct key, one incorrect key:
for x in range(len(dicts)):
spam = x*4
assert find_dict_in_list(dicts, spam=spam, shrubbery=spam+1) is None
# Search for non-existent dict.
for x in range(len(dicts)):
spam = x+100
assert find_dict_in_list(dicts, spam=spam) is None
data = [
{"name": "Tom", "age": 10},
{"name": "Mark", "age": 5},
{"name": "Pam", "age": 7}
]
target_name = "Pam"
for person in data:
if person["name"] == target_name:
print(person) # This will print the dictionary for Pam
break # You can add a break statement to stop after finding the first match
"""Alternatively, to store the result in a variable:"""
pam_data = None
for person in data:
if person["name"] == target_name:
pam_data = person
break
if pam_data:
print(pam_data) # This will print the dictionary for Pam (if found)
© 2022 - 2024 — McMap. All rights reserved.
{kind=link}