TL;DR - There is a seperate MMU per CPU, but an MMU generally has several LEVELS of page tables and these may be shared.
For instance, on an ARM the top level (PGD or page global directory name used in Linux) covers 1MB of address space. In simple systems, you can map in 1MB sections. However, this normally points to a 2nd level table (PTE or page table entry).
One way to implement multi-CPU efficiently is to have a separate top level PGD per CPU. The OS code and data will be consistent between cores. Each core will have its own TLB and L1-cache; L2/L3 caches maybe shared or may not. The maintenance of data/code caches depend on whether they are VIVT or VIPT, but that is a side issue and shouldn't affect the use of MMU and multi-core.
The process or user portion of the 2nd level page tables remain the same per process; otherwise they would have different memory or you would need to synchronize redundant tables. Individual cores may have different sets of 2nd level page tables (different top level page table pointer) when they run different processes. If it is multi-threaded, and running on two CPUs then the top level table may contain the same 2nd level page table entries for the process. In fact, the entire top level page table maybe identical (but different memory) when two CPUs run the same process. If thread local data is implemented with an MMU a single entry could differ. However, thread local data is usually implemented in other ways due to TLB and cache issue (flushing/coherency).
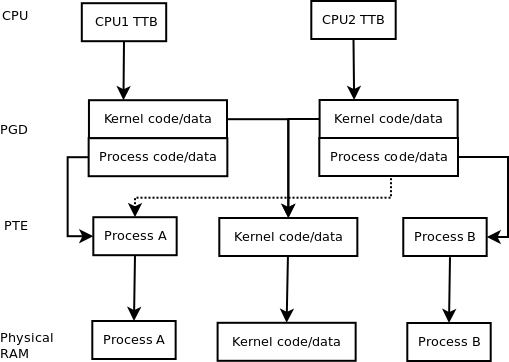
The image below may help. The CPU, PGD, and PTE entries in the diagram are sort of like pointers.
![Multi-cpu MMU]()
The dashed line is the only difference between running different processes and the same processes (multi-threading case) with the MMU; it is an alternate to the solid line running from the CPU2 PGD to the process B PTE or 2nd level page table. The kernel is always a multi-threaded CPU application.
When a virtual address is translated, different bit portions are indexes into each table. If a virtual address is not in the TLB, then the CPU must do a table walk (and fetch different table memory). So a single read of a process memory would result in three memory accesses (if the TLB wasn't present).
The access permission of the kernel code/data are obviously different. In fact, there will probably be other issues such as device memory, etc. However, I think the diagram should make it obvious how the MMU manages to keep multi-threaded memory the same.
It is entirely possible that an entry in the 2nd level table could be different per thread. However, this would incur a cost when switching threads on the same CPU so normally data for all 'thread locals' is mapped and some other way to select the data is used. Normally the thread local data is found via a pointer or index register (special per CPU) which is mapped/points to data inside the 'process' or user memory. 'Thread local data' is not isolated from other threads, so if you have a memory overwrite in one thread you could kill another threads data.

{kind=link}