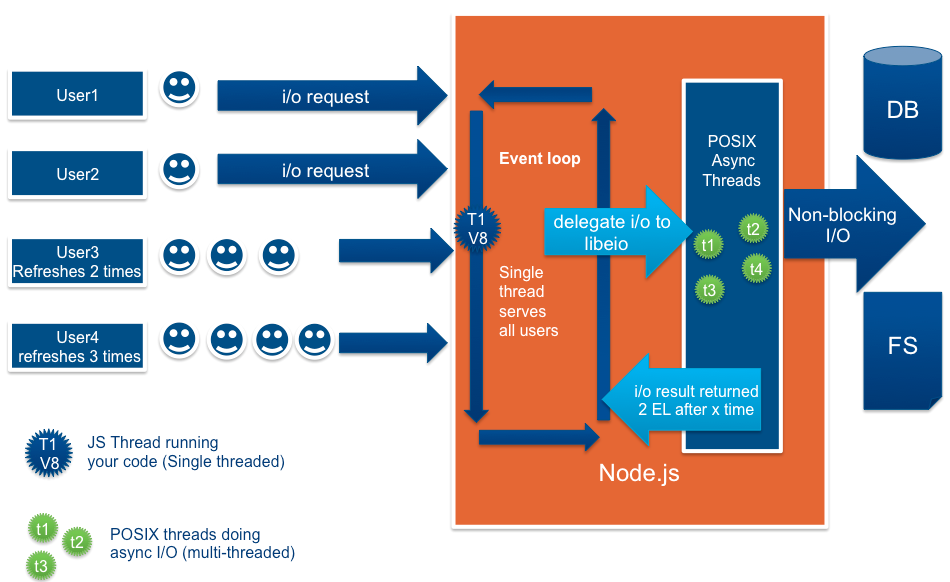
Your confusion might be coming from not focusing on the event loop enough. Clearly you have an idea of how this works, but maybe you do not have the full picture yet.
Part 1, Event Loop Basics
When you call the use method, what happens behind the scenes is another thread is created to listen for connections.
However, when a request comes in, because we're in a different thread than the V8 engine (and cannot directly invoke the route function), a serialized call to the function is appended onto the shared event loop, for it to be called later. ('event loop' is a poor name in this context, as it operates more like a queue or stack)
At the end of the JavaScript file, the V8 engine will check if there are any running theads or messages in the event loop. If there are none, it will exit with a code of 0 (this is why server code keeps the process running). So the first Timing nuance to understand is that no request will be processed until the synchronous end of the JavaScript file is reached.
If the event loop was appended to while the process was starting up, each function call on the event loop will be handled one by one, in its entirety, synchronously.
For simplicity, let me break down your example into something more expressive.
function callback() {
setTimeout(function inner() {
console.log('hello inner!');
}, 0); // †
console.log('hello callback!');
}
setTimeout(callback, 0);
setTimeout(callback, 0);
† setTimeout with a time of 0, is a quick and easy way to put something on the event loop without any timer complications, since no matter what, it has always been at least 0ms.
In this example, the output will always be:
hello callback!
hello callback!
hello inner!
hello inner!
Both serialized calls to callback are appended to the event loop before either of them is called. This is guaranteed. That happens because nothing can be invoked from the event loop until after the full synchronous execution of the file.
It can be helpful to think of the execution of your file, as the first thing on the event loop. Because each invocation from the event loop can only happen in series, it becomes a logical consequence, that no other event loop invocation can occur during its execution; Only when the previous invocation is finished, can the next event loop function be invoked.
Part 2, The inner Callback
The same logic applies to the inner callback as well, and can be used to explain why the program will never output:
hello callback!
hello inner!
hello callback!
hello inner!
Like you might expect.
By the end of the execution of the file, two serialized function calls will be on the event loop, both for callback. As the Event loop is a FIFO (first in, first out), the setTimeout that came first, will be be invoked first.
The first thing callback does is perform another setTimeout. As before, this will append a serialized call, this time to the inner function, to the event loop. setTimeout immediately returns, and execution will move on to the first console.log.
At this time, the event loop looks like this:
1 [callback] (executing)
2 [callback] (next in line)
3 [inner] (just added by callback)
The return of callback is the signal for the event loop to remove that invocation from itself. This leaves 2 things in the event loop now: 1 more call to callback, and 1 call to inner.
Now callback is the next function in line, so it will be invoked next. The process repeats itself. A call to inner is appended to the event loop. A console.log prints Hello Callback! and we finish by removing this invocation of callback from the event loop.
This leaves the event loop with 2 more functions:
1 [inner] (next in line)
2 [inner] (added by most recent callback)
Neither of these functions mess with the event loop any further. They execute one after the other, the second one waiting for the first one's return. Then when the second one returns, the event loop is left empty. This fact, combined with the fact that there are no other threads currently running, triggers the end of the process, which exits with a return code of 0.
Part 3, Relating to the Original Example
The first thing that happens in your example, is that a thread is created within the process which will create a server bound to a particular port. Note, this is happening in precompiled C++ code, not JavaScript, and is not a separate process, it's a thread within the same process. see: C++ Thread Tutorial.
So now, whenever a request comes in, the execution of your original code won't be disturbed. Instead, incoming connection requests will be opened, held onto, and appended to the event loop.
The use function, is the gateway into catching the events for incoming requests. Its an abstraction layer, but for the sake of simplicity, it's helpful to think of the use function like you would a setTimeout. Except, instead of waiting a set amount of time, it appends the callback to the event loop upon incoming http requests.
So, let's assume that there are two requests coming in to the server: T1 and T2. In your question you say they come in concurrently, since this is technically impossible, I'm going to assume they are one after the other, with a negligible time in between them.
Whichever request comes in first, will be handled first by the secondary thread from earlier. Once that connection has been opened, it's appended to the event loop, and we move on to the next request, and repeat.
At any point after the first request is added to the event loop, V8 can begin execution of the use callback.
A quick aside about readImage
Since its unclear whether readImage is from a particular library, something you wrote or otherwise, it's impossible to tell exactly what it will do in this case. There are only 2 possibilities though, so here they are:
- It's entirely synchronous, never using an alternate thread or the event loop
function readImage (path, callback) {
let image = fs.readFileSync(path);
callback(null, image);
// a definition like this will force the callback to
// fully return before readImage returns. This means
// means readImage will block any subsequent calls.
}
- It's entirely asynchronous, and takes advantage of fs' async callback.
function readImage (path, callback) {
fs.readFile(path, (err, data) => {
callback(err, data);
});
// a definition like this will force the readImage
// to immediately return, and allow exectution
// to continue.
}
For the purposes of explanation, I'll be operating under the assumption that readImage will immediately return, as proper asynchronous functions should.
Once the use callback execution is started, the following will happen:
- The first console log will print.
readImage will kick off a worker thread and immediately return.- The second console log will print.
During all of this, its important to note, these operations are happening synchronously; No other event loop invocation can start until these are finished. readImage may be asynchronous, but calling it is not, the callback and usage of a worker thread is what makes it asynchronous.
After this use callback returns, the next request has probably already finished parsing and was added to the event loop, while V8 was busy doing our console logs and readImage call.
So the next use callback is invoked, and repeats the same process: log, kick off a readImage thread, log again, return.
After this point, the readImage functions (depending on how long they take) have probably already retrieved what they needed and appended their callback to the event loop. So they will get executed next, in order of whichever one retrieved its data first. Remember, these operations were happening in separate threads, so they happened not only in parallel to the main javascript thread, but also parallel to each other, so here, it doesn't matter which one got called first, it matters which one finished first, and got 'dibs' on the event loop.
Whichever readImage completed first will be the first one to execute. So, assuming no errors occured, we'll print out to the console, then write to the response for the corresponding request, held in lexical scope.
When that send returns, the next readImage callback will begin execution: console log, and writing to the response.
At this point, both readImage threads have died, and the event loop is empty, but the thread that holds the server port binding is keeping the process alive, waiting for something else to add to the event loop, and the cycle to continue.
I hope this helps you understand the mechanics behind the asynchronous nature of the example you provided.