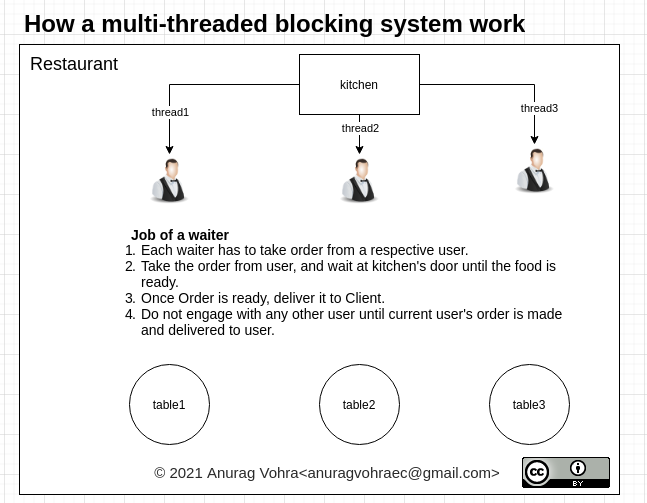
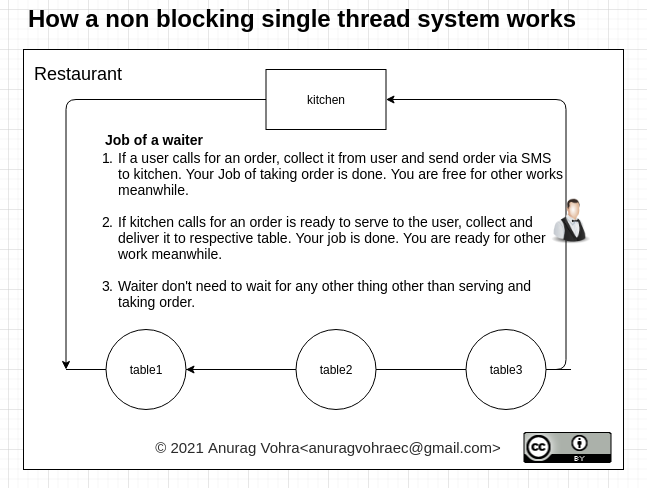
If you have to ask this question then you're probably unfamiliar with what most web applications/services do. You're probably thinking that all software do this:
user do an action
│
v
application start processing action
└──> loop ...
└──> busy processing
end loop
└──> send result to user
However, this is not how web applications, or indeed any application with a database as the back-end, work. Web apps do this:
user do an action
│
v
application start processing action
└──> make database request
└──> do nothing until request completes
request complete
└──> send result to user
In this scenario, the software spend most of its running time using 0% CPU time waiting for the database to return.
Multithreaded network app:
Multithreaded network apps handle the above workload like this:
request ──> spawn thread
└──> wait for database request
└──> answer request
request ──> spawn thread
└──> wait for database request
└──> answer request
request ──> spawn thread
└──> wait for database request
└──> answer request
So the thread spend most of their time using 0% CPU waiting for the database to return data. While doing so they have had to allocate the memory required for a thread which includes a completely separate program stack for each thread etc. Also, they would have to start a thread which while is not as expensive as starting a full process is still not exactly cheap.
Singlethreaded event loop
Since we spend most of our time using 0% CPU, why not run some code when we're not using CPU? That way, each request will still get the same amount of CPU time as multithreaded applications but we don't need to start a thread. So we do this:
request ──> make database request
request ──> make database request
request ──> make database request
database request complete ──> send response
database request complete ──> send response
database request complete ──> send response
In practice both approaches return data with roughly the same latency since it's the database response time that dominates the processing.
The main advantage here is that we don't need to spawn a new thread so we don't need to do lots and lots of malloc which would slow us down.
Magic, invisible threading
The seemingly mysterious thing is how both the approaches above manage to run workload in "parallel"? The answer is that the database is threaded. So our single-threaded app is actually leveraging the multi-threaded behaviour of another process: the database.
Where singlethreaded approach fails
A singlethreaded app fails big if you need to do lots of CPU calculations before returning the data. Now, I don't mean a for loop processing the database result. That's still mostly O(n). What I mean is things like doing Fourier transform (mp3 encoding for example), ray tracing (3D rendering) etc.
Another pitfall of singlethreaded apps is that it will only utilise a single CPU core. So if you have a quad-core server (not uncommon nowdays) you're not using the other 3 cores.
Where multithreaded approach fails
A multithreaded app fails big if you need to allocate lots of RAM per thread. First, the RAM usage itself means you can't handle as many requests as a singlethreaded app. Worse, malloc is slow. Allocating lots and lots of objects (which is common for modern web frameworks) means we can potentially end up being slower than singlethreaded apps. This is where node.js usually win.
One use-case that end up making multithreaded worse is when you need to run another scripting language in your thread. First you usually need to malloc the entire runtime for that language, then you need to malloc the variables used by your script.
So if you're writing network apps in C or go or java then the overhead of threading will usually not be too bad. If you're writing a C web server to serve PHP or Ruby then it's very easy to write a faster server in javascript or Ruby or Python.
Hybrid approach
Some web servers use a hybrid approach. Nginx and Apache2 for example implement their network processing code as a thread pool of event loops. Each thread runs an event loop simultaneously processing requests single-threaded but requests are load-balanced among multiple threads.
Some single-threaded architectures also use a hybrid approach. Instead of launching multiple threads from a single process you can launch multiple applications - for example, 4 node.js servers on a quad-core machine. Then you use a load balancer to spread the workload amongst the processes. The cluster module in node.js does exactly this.
In effect the two approaches are technically identical mirror-images of each other.