Assuming that aligned pointer loads and stores are naturally atomic on the target platform, what is the difference between this:
// Case 1: Dumb pointer, manual fence
int* ptr;
// ...
std::atomic_thread_fence(std::memory_order_release);
ptr = new int(-4);
this:
// Case 2: atomic var, automatic fence
std::atomic<int*> ptr;
// ...
ptr.store(new int(-4), std::memory_order_release);
and this:
// Case 3: atomic var, manual fence
std::atomic<int*> ptr;
// ...
std::atomic_thread_fence(std::memory_order_release);
ptr.store(new int(-4), std::memory_order_relaxed);
I was under the impression that they were all equivalent, however Relacy detects a data race in the first case (only):
struct test_relacy_behaviour : public rl::test_suite<test_relacy_behaviour, 2>
{
rl::var<std::string*> ptr;
rl::var<int> data;
void before()
{
ptr($) = nullptr;
rl::atomic_thread_fence(rl::memory_order_seq_cst);
}
void thread(unsigned int id)
{
if (id == 0) {
std::string* p = new std::string("Hello");
data($) = 42;
rl::atomic_thread_fence(rl::memory_order_release);
ptr($) = p;
}
else {
std::string* p2 = ptr($); // <-- Test fails here after the first thread completely finishes executing (no contention)
rl::atomic_thread_fence(rl::memory_order_acquire);
RL_ASSERT(!p2 || *p2 == "Hello" && data($) == 42);
}
}
void after()
{
delete ptr($);
}
};
I contacted the author of Relacy to find out if this was expected behaviour; he says that there is indeed a data race in my test case. However, I'm having trouble spotting it; can someone point out to me what the race is? Most importantly, what are the differences between these three cases?
Update: It's occurred to me that Relacy may simply be complaining about the atomicity (or lack thereof, rather) of the variable being accessed across threads... after all, it doesn't know that I intend only to use this code on platforms where aligned integer/pointer access is naturally atomic.
Another update: Jeff Preshing has written an excellent blog post explaining the difference between explicit fences and the built-in ones ("fences" vs "operations"). Cases 2 and 3 are apparently not equivalent! (In certain subtle circumstances, anyway.)
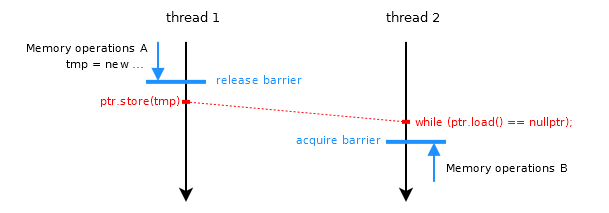
std::atomicvar (and the same manual fences). – Bernardinastd::atomic, but does have memory barrier primitives, so I used manual fences (this way I also need less than one per variable access). I guess my example code is kinda trivial, but I really do want to find out what the differences are between the samples, since this is exactly the kind of code that may turn out to fail only on one arch. Thanks for taking an interest by the way :-) – Bernardina