[EDIT] The answer by @Claudio gives me a really good tip on how to filter out outliers. I do want to start using a Kalman filter on my data though. So I changed the example data below so that it has subtle variation noise which are not so extreme (which I see a lot as well). If anybody else could give me some direction on how to use PyKalman on my data that would be great. [/EDIT]
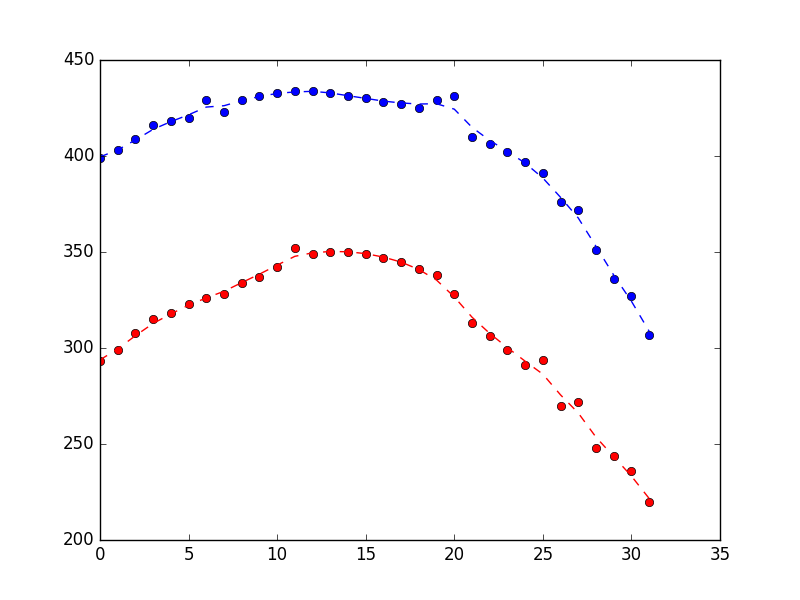
For a robotics project I'm trying to track a kite in the air with a camera. I'm programming in Python and I pasted some noisy location results below (every item also has a datetime object included, but I left them out for clarity).
[ # X Y
{'loc': (399, 293)},
{'loc': (403, 299)},
{'loc': (409, 308)},
{'loc': (416, 315)},
{'loc': (418, 318)},
{'loc': (420, 323)},
{'loc': (429, 326)}, # <== Noise in X
{'loc': (423, 328)},
{'loc': (429, 334)},
{'loc': (431, 337)},
{'loc': (433, 342)},
{'loc': (434, 352)}, # <== Noise in Y
{'loc': (434, 349)},
{'loc': (433, 350)},
{'loc': (431, 350)},
{'loc': (430, 349)},
{'loc': (428, 347)},
{'loc': (427, 345)},
{'loc': (425, 341)},
{'loc': (429, 338)}, # <== Noise in X
{'loc': (431, 328)}, # <== Noise in X
{'loc': (410, 313)},
{'loc': (406, 306)},
{'loc': (402, 299)},
{'loc': (397, 291)},
{'loc': (391, 294)}, # <== Noise in Y
{'loc': (376, 270)},
{'loc': (372, 272)},
{'loc': (351, 248)},
{'loc': (336, 244)},
{'loc': (327, 236)},
{'loc': (307, 220)}
]
I first thought of manually calculating outliers and then simply removing them from the data in real time. Then I read about Kalman filters and how they are specifically meant to smoothen out noisy data. So after some searching I found the PyKalman library which seems perfect for this. Since I was kinda lost in the whole Kalman filter terminology I read through the wiki and some other pages on Kalman filters. I get the general idea of a Kalman filter, but I'm really lost in how I should apply it to my code.
In the PyKalman docs I found the following example:
>>> from pykalman import KalmanFilter
>>> import numpy as np
>>> kf = KalmanFilter(transition_matrices = [[1, 1], [0, 1]], observation_matrices = [[0.1, 0.5], [-0.3, 0.0]])
>>> measurements = np.asarray([[1,0], [0,0], [0,1]]) # 3 observations
>>> kf = kf.em(measurements, n_iter=5)
>>> (filtered_state_means, filtered_state_covariances) = kf.filter(measurements)
>>> (smoothed_state_means, smoothed_state_covariances) = kf.smooth(measurements)
I simply substituted the observations for my own observations as follows:
from pykalman import KalmanFilter
import numpy as np
kf = KalmanFilter(transition_matrices = [[1, 1], [0, 1]], observation_matrices = [[0.1, 0.5], [-0.3, 0.0]])
measurements = np.asarray([(399,293),(403,299),(409,308),(416,315),(418,318),(420,323),(429,326),(423,328),(429,334),(431,337),(433,342),(434,352),(434,349),(433,350),(431,350),(430,349),(428,347),(427,345),(425,341),(429,338),(431,328),(410,313),(406,306),(402,299),(397,291),(391,294),(376,270),(372,272),(351,248),(336,244),(327,236),(307,220)])
kf = kf.em(measurements, n_iter=5)
(filtered_state_means, filtered_state_covariances) = kf.filter(measurements)
(smoothed_state_means, smoothed_state_covariances) = kf.smooth(measurements)
but that doesn't give me any meaningful data. For example, the smoothed_state_means becomes the following:
>>> smoothed_state_means
array([[-235.47463353, 36.95271449],
[-354.8712597 , 27.70011485],
[-402.19985301, 21.75847069],
[-423.24073418, 17.54604304],
[-433.96622233, 14.36072376],
[-443.05275258, 11.94368163],
[-446.89521434, 9.97960296],
[-456.19359012, 8.54765215],
[-465.79317394, 7.6133633 ],
[-474.84869079, 7.10419182],
[-487.66174033, 7.1211321 ],
[-504.6528746 , 7.81715451],
[-506.76051587, 8.68135952],
[-510.13247696, 9.7280697 ],
[-512.39637431, 10.9610031 ],
[-511.94189431, 12.32378146],
[-509.32990832, 13.77980587],
[-504.39389762, 15.29418648],
[-495.15439769, 16.762472 ],
[-480.31085928, 18.02633612],
[-456.80082586, 18.80355017],
[-437.35977492, 19.24869224],
[-420.7706184 , 19.52147918],
[-405.59500937, 19.70357845],
[-392.62770281, 19.8936389 ],
[-388.8656724 , 20.44525168],
[-361.95411607, 20.57651509],
[-352.32671579, 20.84174084],
[-327.46028214, 20.77224385],
[-319.75994982, 20.9443245 ],
[-306.69948771, 21.24618955],
[-287.03222693, 21.43135098]])
Could a brighter soul than me give me some hints or examples in the right direction? All tips are welcome!