How do I remove duplicates from a list, while preserving order? Using a set to remove duplicates destroys the original order. Is there a built-in or a Pythonic idiom?
How do I remove duplicates from a list, while preserving order?
Asked Answered
Here you have some alternatives: http://www.peterbe.com/plog/uniqifiers-benchmark
Fastest one:
def f7(seq):
seen = set()
seen_add = seen.add
return [x for x in seq if not (x in seen or seen_add(x))]
Why assign seen.add to seen_add instead of just calling seen.add? Python is a dynamic language, and resolving seen.add each iteration is more costly than resolving a local variable. seen.add could have changed between iterations, and the runtime isn't smart enough to rule that out. To play it safe, it has to check the object each time.
If you plan on using this function a lot on the same dataset, perhaps you would be better off with an ordered set: http://code.activestate.com/recipes/528878/
O(1) insertion, deletion and member-check per operation.
(Small additional note: seen.add() always returns None, so the or above is there only as a way to attempt a set update, and not as an integral part of the logical test.)
@JesseDhillon
seen.add could have changed between iterations, and the runtime isn't smart enough to rule that out. To play safe, it has to check the object each time. -- If you look at the bytecode with dis.dis(f), you can see that it executes LOAD_ATTR for the add member on each iteration. ideone.com/tz1Tll –
Requiescat Technically, O(1) for insertions and lookups is impossible, if you are careful with definitions. If most elements are distinct, hashing is best analyzed as O(log N), not O(1), much like counting the digits in a 64-bit number takes 64 operations. –
Dooley
When I try this on a list of lists I get: TypeError: unhashable type: 'list' –
Dd
@JensTimmerman Yes. Lists in Python are not hashable, and thus can't be used for fast look-up. You can either convert the sub-lists to a hashable type (tuple?), or swap
set() and seen.add for list() and seen.append. –
Requiescat Your solution is not the fastest one. In Python 3 (did not test 2) this is faster (300k entries list - 0.045s (yours) vs 0.035s (this one): seen = set(); return [x for x in lines if x not in seen and not seen.add(x)]. I could not find any speed effect of the seen_add line you did. –
Collocation
A small comment: the insertion/deletion/member methods on sets in Python are O(n) worst case and O(1) average case: they use a hashset with linked lists as is explained here. –
Murrhine
@Collocation Please link to your tests. How many times did you run them?
seen_add is an improvement but timings can be affected by system resources at the time. Would be interested to see full timings –
Pallium Did you test this solution across Python implementations, or only on CPython? I would be surprised if the seen_add line helped much given PyPy's JIT for example. –
Breuer
Even on standard CPython (3.5) I see no timing difference. Timeit gives 3.048, 2.898, 2.852 without seen_add, and 2.960, 3.008, 2.959 with. (All tests run 1000 times on the same list of 50,000 random integers 0-9). Something seems fishy about the explanation - seen_add should execute the same code as seen.add; both are shown as <built-in method add of set object at 0x01234567>. –
Ary
It is a micro-optimization. The disassembled code changes from
LOAD_DEREF 0 (seen) + LOAD_ATTR 0 (add) to just LOAD_DEREF 1 (seen_add). Optimizing compilers might do something similar. –
Requiescat I am not able to understand
seen_add(x). wouldn't it return None every time? Please explain. –
Cretinism @prof.phython Yes. It is just there because
if not() is a convenient way to execute the function inline. x in seen or seen_add(x) evaluates to either False or None, both of which turn into True when prefixed by not. –
Requiescat @MarkusJarderot Okay. But why are we doing
(x in seen or seen_add(x))'. wouldn't only (x in seen)` would work? What does seen_add(x) do in this statement? Thanks –
Cretinism @prof.phython
seen_add is a reference to seen.add(), which adds the item the set while the list is being processed. The next time an identical item is found, it will be skipped. –
Requiescat @MarkusJarderot Yes i can understand that. My only confusion is that why
return [x for x in seq if not (x in seen)] cannot work. Why do we need seen.add() to check? –
Cretinism @prof.phython It is not there to affect the result. It is there to update the set if the check fails (
x in seen). –
Requiescat To anyone who is writing Python code, you really should think twice before sacrificing readability and commonly-agreed Python conventions just to squeeze out a few more nanoseconds per loop. Testing with and without
seen_add = seen.add yields only a 1% increase in speed. It's hardly significant. –
Stane @Stane What data did you test it with? For
seq = list(range(19000)) I get ~1.9 ms with seen_add and ~2.3 ms with seen.add. That's not 1% but about 20%. –
Anathema @Ary Of course you didn't see a big difference for that. With 50,000 random integers 0-9,
seen.add or seen_add will be called only 10 times, which is insignificant. Try something like the seq = list(range(19000)) that I just mentioned. –
Anathema @sleblanc: A couple notes: 1) As Stefan notes, for a case with few/no duplicates, the cost of
seen.add is higher (for seq = tuple(range(10000)) on Python 3.10.0, %timeit f7(seq) takes around 487 µs, vs. 557 µs w/o caching, 14.4% more). 2) At the time the answer was written, the cost of calling methods was higher; in 3.7+, the LOAD_METHOD/CALL_METHOD opcodes often avoid constructing a bound method in cases like this, but in 3.6 and earlier, it always had to build and discard a bound method; same test, same machine, using 3.6.4 took 602 µs w/caching, 792 µs w/o (31.5% more). –
Christmann @sleblanc: All that said, it's still clearly a microoptimization that comes at the expense of readability (heck, the ugliness of forcing it into the listcomp in the first place is an ugly microoptimization over a straightforward
for loop that would occupy four lines with explicit membership testing controlling modifications to both seen and a list used as the retval). This solution is good if profiling says you really need it (and you're use pre-Python-3.5 where dict is unordered and OrderedDict is still implemented in Python), but otherwise, the benefits aren't worth ugly code. –
Christmann And rewriting it in C++ would yield 100% improvement or more. I don't see why you're spending so much time on that. If you truly care about sub-millisecond performance improvements, starting with Python is a dead-end. –
Stane
This needs to be downvoted off the page. Don't write Python like this. –
Enact
@Enact This is just a comparison of speed, not style.
f7 was the fastest when that article was written. It could easily be written more pythonic, if you don't care about top speed. –
Requiescat @MarkusJarderot 1. Nothing in the question ever asked for speed or suggested performance was a concern, so why suggest the ugly micro-optimizations? 2. Even for an attempt at writing a fast solution this is bad, using
list(dict.fromkeys(...)) offers a ~45% improvement (timed it with a list of 200 integers between 0-100). –
Enact Actually the question asked for a "Pythonic idiom", which this is the opposite of. –
Enact
This is a weird edge case solution just for performance enhancement. This is not Pythonic, not mainstream, and not as readable as the other simpler answers. As many others have commented, it is also NOT the fastest solution. This is not acceptable as the accepted answer. I give it a downvote as the "accepted" answer and encourage others to downvote it or vote to have it removed. –
Harve
The best solution varies by Python version and environment constraints:
Python 3.7+ (and most interpreters supporting 3.6, as an implementation detail):
First introduced in PyPy 2.5.0, and adopted in CPython 3.6 as an implementation detail, before being made a language guarantee in Python 3.7, plain dict is insertion-ordered, and even more efficient than the (also C implemented as of CPython 3.5) collections.OrderedDict. So the fastest solution, by far, is also the simplest:
>>> items = [1, 2, 0, 1, 3, 2]
>>> list(dict.fromkeys(items)) # Or [*dict.fromkeys(items)] if you prefer
[1, 2, 0, 3]
Like list(set(items)) this pushes all the work to the C layer (on CPython), but since dicts are insertion ordered, dict.fromkeys doesn't lose ordering. It's slower than list(set(items)) (takes 50-100% longer typically), but much faster than any other order-preserving solution (takes about half the time of hacks involving use of sets in a listcomp).
Important note: The unique_everseen solution from more_itertools (see below) has some unique advantages in terms of laziness and support for non-hashable input items; if you need these features, it's the only solution that will work.
Python 3.5 (and all older versions if performance isn't critical)
As Raymond pointed out, in CPython 3.5 where OrderedDict is implemented in C, ugly list comprehension hacks are slower than OrderedDict.fromkeys (unless you actually need the list at the end - and even then, only if the input is very short). So on both performance and readability the best solution for CPython 3.5 is the OrderedDict equivalent of the 3.6+ use of plain dict:
>>> from collections import OrderedDict
>>> items = [1, 2, 0, 1, 3, 2]
>>> list(OrderedDict.fromkeys(items))
[1, 2, 0, 3]
On CPython 3.4 and earlier, this will be slower than some other solutions, so if profiling shows you need a better solution, keep reading.
Python 3.4 and earlier, if performance is critical and third-party modules are acceptable
As @abarnert notes, the more_itertools library (pip install more_itertools) contains a unique_everseen function that is built to solve this problem without any unreadable (not seen.add) mutations in list comprehensions. This is the fastest solution too:
>>> from more_itertools import unique_everseen
>>> items = [1, 2, 0, 1, 3, 2]
>>> list(unique_everseen(items))
[1, 2, 0, 3]
Just one simple library import and no hacks.
The module is adapting the itertools recipe unique_everseen which looks like:
def unique_everseen(iterable, key=None):
"List unique elements, preserving order. Remember all elements ever seen."
# unique_everseen('AAAABBBCCDAABBB') --> A B C D
# unique_everseen('ABBCcAD', str.lower) --> A B C D
seen = set()
seen_add = seen.add
if key is None:
for element in filterfalse(seen.__contains__, iterable):
seen_add(element)
yield element
else:
for element in iterable:
k = key(element)
if k not in seen:
seen_add(k)
yield element
but unlike the itertools recipe, it supports non-hashable items (at a performance cost; if all elements in iterable are non-hashable, the algorithm becomes O(n²), vs. O(n) if they're all hashable).
Important note: Unlike all the other solutions here, unique_everseen can be used lazily; the peak memory usage will be the same (eventually, the underlying set grows to the same size), but if you don't listify the result, you just iterate it, you'll be able to process unique items as they're found, rather than waiting until the entire input has been deduplicated before processing the first unique item.
Python 3.4 and earlier, if performance is critical and third party modules are unavailable
You have two options:
Copy and paste in the
unique_everseenrecipe to your code and use it per themore_itertoolsexample aboveUse ugly hacks to allow a single listcomp to both check and update a
setto track what's been seen:seen = set() [x for x in seq if x not in seen and not seen.add(x)]at the expense of relying on the ugly hack:
not seen.add(x)which relies on the fact that
set.addis an in-place method that always returnsNonesonot Noneevaluates toTrue.
Note that all of the solutions above are O(n) (save calling unique_everseen on an iterable of non-hashable items, which is O(n²), while the others would fail immediately with a TypeError), so all solutions are performant enough when they're not the hottest code path. Which one to use depends on which versions of the language spec/interpreter/third-party modules you can rely on, whether or not performance is critical (don't assume it is; it usually isn't), and most importantly, readability (because if the person who maintains this code later ends up in a murderous mood, your clever micro-optimization probably wasn't worth it).
Converting to some custom kind of dict just to take keys? Just another crutch. –
Endosmosis
@Endosmosis I don't really see how it's a crutch. It doesn't expose any mutable state, so its very clean in that sense. Internally, Python sets are implemented with dict() (#3949810), so basically you're just doing what the interpreter would've done anyway. –
Eponym
Just use side effects and do
[seen.add(x) for x in seq if x not in seen], or if you don't like comprehension side effects just use a for loop: for x in seq: seen.add(x) if x not in seen else None (still a one-liner, although in this case I think one-liner-ness is a silly property to try to have in a solution. –
Longevity @EMS That doesn't preserve order. You could just as well do
seen = set(seq). –
R Sure, when
seen is a set. Just use seen=[] and [seen.append(x) for x in seq if x not in seen] does preserve order. –
Longevity This solution is extremly slower than the mentioned "hack". For my list of 300k entries over 50x slower. –
Collocation
I agree its slower, for speed I would definitely use the hack –
Pallium
The run-time complexity is strictly speaking O(n^2) worst-case and O(n) average case... –
Murrhine
@CommuSoft I agree, although practically it's almost always O(n) due to the super highly unlikely worst case –
Pallium
I'm getting a no module named 'more_itertools' found. Is the module deprecated? –
Unshod
@Unshod It's an external library so you have to install it. eg.
pip install more_itertools –
Pallium @Imran: Internally, Python's
set uses hashtables, but they're not actually implemented with dict. Back when they were first introduced in Python 2.4, they were wrappers around a dict where all the keys were True, but they diverged rapidly from there, removing the dict wrapping in 2.5 in favor of their own dedicated code that was based on dict but maintained independently, and slowly diverging from dict (mostly it was dict diverging from set as dict added all sorts of optimizations to make it more efficient when used as the __dict__ for classes and instances). –
Christmann @Imran: To be clear, I don't disagree with your core point (that using
dict/OrderedDict for ordered set-like behaviors is a perfectly reasonable thing to do), but you're not just "doing what the interpreter would have done anyway" (even the code using plain list(dict.fromkeys(iterable)) in Python 3.7+ takes about twice as long as using list(set(iterable)), because set is optimized for that use case and dict isn't, even though they're both hash tables and in theory should perform identically, save the cost of storing values for the dict). –
Christmann See also: #1654470 –
Jem
In CPython 3.6+ (and all other Python implementations starting with Python 3.7+), dictionaries are ordered, so the way to remove duplicates from an iterable while keeping it in the original order is:
>>> list(dict.fromkeys('abracadabra'))
['a', 'b', 'r', 'c', 'd']
In Python 3.5 and below (including Python 2.7), use the OrderedDict. My timings show that this is now both the fastest and shortest of the various approaches for Python 3.5 (when it gained a C implementation; prior to 3.5 it's still the clearest solution, though not the fastest).
>>> from collections import OrderedDict
>>> list(OrderedDict.fromkeys('abracadabra'))
['a', 'b', 'r', 'c', 'd']
The only gotcha is that the iterable "elements" must be hashable - would be nice to have the equivalent for iterables with arbitrary elements (as a list of lists) –
Puerperium
Insertion order iteration over a dict provides functionality that services more use-cases than removing duplicates. For example, scientific analyses rely on reproducible computations which non-deterministic dict iteration doesn't support. Reproducibility is a major current objective in computational scientific modeling, so we welcome this new feature. Although I know it's trivial to build with a deterministic dict, a high-performance, deterministic
set() would help more naive users develop reproducible codes. –
Calderon What about using
[*dict.fromkeys('abracadabra')] (unpacking) instead of calling the function list(...)? In my tests this is faster, although only very small differences can be detected. So I'm not sure if this is just a coincidence. –
Friedland @Friedland Yes, that would work. The small speed difference is likely due to operators not having to lookup a builtin function. There is a matter of clarity to considered as well. –
Gravitate
@RaymondHettinger: The lookup cost was small (got smaller with 3.8's
LOAD_GLOBAL); main advantage was avoiding constructor code paths (requiring construction of a tuple for args and passing NULL pointer as kwargs dict, then calling both the mostly empty __new__ and the __init__ separately, the latter of which then has to go through generalized argument parsing code, all to pass 0-1 positional arguments). As of 3.9 though, list() bypasses most of that via the vectorcall protocol, reducing the incremental benefit from 60-70 ns (3.8.5) to 20-30 ns (3.10.0) on my machine. –
Christmann @Mr_and_Mrs_D, it just isn't possible to deduplicate elements in O(n) without hashing. Deduplicating arbitrary elements would be O(n^2). –
Merrymaker
Not to kick a dead horse (this question is very old and already has lots of good answers), but here is a solution using pandas that is quite fast in many circumstances and is dead simple to use.
import pandas as pd
my_list = [0, 1, 2, 3, 4, 1, 2, 3, 5]
>>> pd.Series(my_list).drop_duplicates().tolist()
# Output:
# [0, 1, 2, 3, 4, 5]
useful, but doesn't preserve the ordering.
more_itertools.unique_everseen does. –
Crazed In Python 3.7 and above, dictionaries are guaranteed to remember their key insertion order. The answer to this question summarizes the current state of affairs.
The OrderedDict solution thus becomes obsolete and without any import statements we can simply issue:
>>> lst = [1, 2, 1, 3, 3, 2, 4]
>>> list(dict.fromkeys(lst))
[1, 2, 3, 4]
sequence = ['1', '2', '3', '3', '6', '4', '5', '6']
unique = []
[unique.append(item) for item in sequence if item not in unique]
unique → ['1', '2', '3', '6', '4', '5']
It's worth noting that this runs in
n^2 –
Tacheometer Ick. 2 strikes: Using a list for membership testing (slow, O(N) for each test) and using a list comprehension for the side effects (building another list of
Nonereferences in the process!) –
Auberbach I agree with @MartijnPieters there's absolutely no reason for the list comprehension with side effects. Just use a
for loop instead –
Pallium from itertools import groupby
[key for key, _ in groupby(sortedList)]
The list doesn't even have to be sorted, the sufficient condition is that equal values are grouped together.
Edit: I assumed that "preserving order" implies that the list is actually ordered. If this is not the case, then the solution from MizardX is the right one.
Community edit: This is however the most elegant way to "compress duplicate consecutive elements into a single element".
But this doesn't preserve order! –
Deepseated
Hrm, this is problematic, since I cannot guarantee that equal values are grouped together without looping once over the list, by which time I could have pruned the duplicates. –
Rupture
I assumed that "preserving order" implied that the list is actually ordered. –
Caliphate
Ah, yes, I read sortedList as sorted(List) :-( But the input list can be in a different order. –
Deepseated
Maybe the specification of the input list is a little bit unclear. The values don't even need to be grouped together: [2, 1, 3, 1]. So which values to keep and which to delete? –
Deepseated
I think that the question should be reattached as a coment under the original question. –
Caliphate
What the
_ is doing in this case? –
Cathycathyleen @Cathycathyleen Ignoring the second element of the pair(s). –
Caliphate
This doesn't work! Try sortedList = [2, 3, 2, 4, 1] –
Haught
However to remove consecutive duplicates from a list/iterable I found this solution to be perfect. –
Evangelicalism
This answers a different question that has been asked elsewhere: stackoverflow.com/questions/5738901 –
Jem
I think if you wanna maintain the order,
you can try this:
list1 = ['b','c','d','b','c','a','a']
list2 = list(set(list1))
list2.sort(key=list1.index)
print list2
OR similarly you can do this:
list1 = ['b','c','d','b','c','a','a']
list2 = sorted(set(list1),key=list1.index)
print list2
You can also do this:
list1 = ['b','c','d','b','c','a','a']
list2 = []
for i in list1:
if not i in list2:
list2.append(i)`
print list2
It can also be written as this:
list1 = ['b','c','d','b','c','a','a']
list2 = []
[list2.append(i) for i in list1 if not i in list2]
print list2
Your first two answers assume that the order of the list can be rebuilt using a sorting function, but this may not be so. –
Gav
Most answers are focused on performance. For lists that aren't large enough to worry about performance, the sorted(set(list1),key=list1.index) is the best thing I've seen. No extra import, no extra function, no extra variable, and it's fairly simple and readable. –
Billion
Just to add another (very performant) implementation of such a functionality from an external module1: iteration_utilities.unique_everseen:
>>> from iteration_utilities import unique_everseen
>>> lst = [1,1,1,2,3,2,2,2,1,3,4]
>>> list(unique_everseen(lst))
[1, 2, 3, 4]
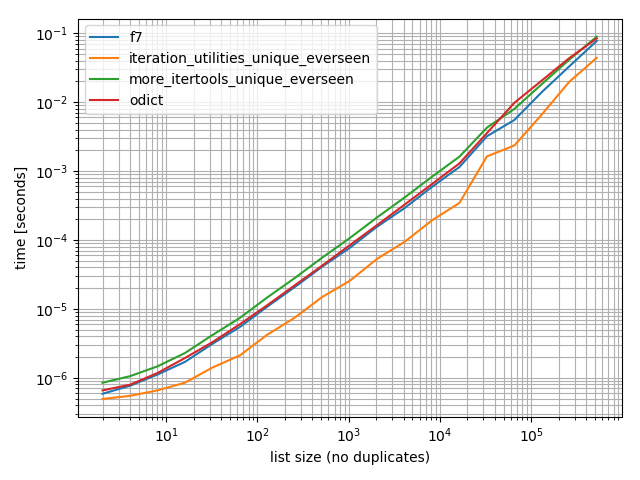
Timings
I did some timings (Python 3.6) and these show that it's faster than all other alternatives I tested, including OrderedDict.fromkeys, f7 and more_itertools.unique_everseen:
%matplotlib notebook
from iteration_utilities import unique_everseen
from collections import OrderedDict
from more_itertools import unique_everseen as mi_unique_everseen
def f7(seq):
seen = set()
seen_add = seen.add
return [x for x in seq if not (x in seen or seen_add(x))]
def iteration_utilities_unique_everseen(seq):
return list(unique_everseen(seq))
def more_itertools_unique_everseen(seq):
return list(mi_unique_everseen(seq))
def odict(seq):
return list(OrderedDict.fromkeys(seq))
from simple_benchmark import benchmark
b = benchmark([f7, iteration_utilities_unique_everseen, more_itertools_unique_everseen, odict],
{2**i: list(range(2**i)) for i in range(1, 20)},
'list size (no duplicates)')
b.plot()
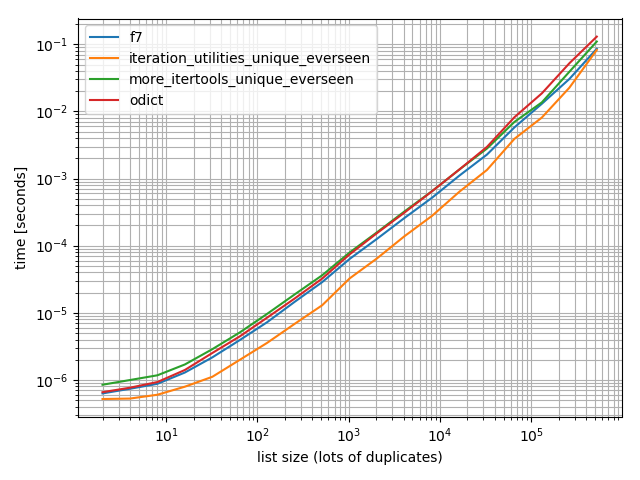
And just to make sure I also did a test with more duplicates just to check if it makes a difference:
import random
b = benchmark([f7, iteration_utilities_unique_everseen, more_itertools_unique_everseen, odict],
{2**i: [random.randint(0, 2**(i-1)) for _ in range(2**i)] for i in range(1, 20)},
'list size (lots of duplicates)')
b.plot()
And one containing only one value:
b = benchmark([f7, iteration_utilities_unique_everseen, more_itertools_unique_everseen, odict],
{2**i: [1]*(2**i) for i in range(1, 20)},
'list size (only duplicates)')
b.plot()
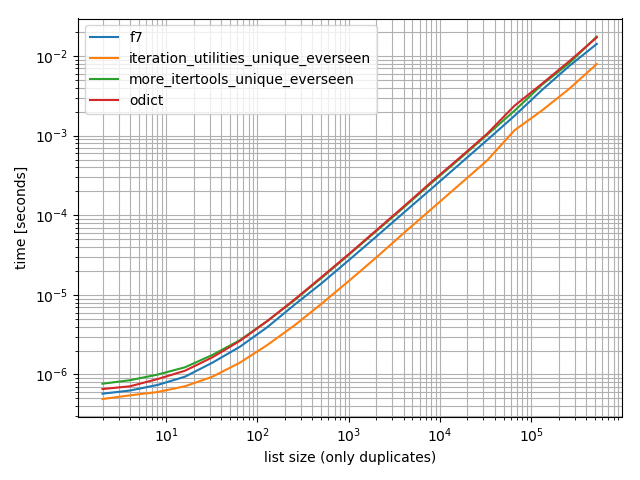
In all of these cases the iteration_utilities.unique_everseen function is the fastest (on my computer).
This iteration_utilities.unique_everseen function can also handle unhashable values in the input (however with an O(n*n) performance instead of the O(n) performance when the values are hashable).
>>> lst = [{1}, {1}, {2}, {1}, {3}]
>>> list(unique_everseen(lst))
[{1}, {2}, {3}]
1 Disclaimer: I'm the author of that package.
I do not understand the necessity für this line:
seen_add = seen.add -- is this needed for the benchmarks? –
Finnish @Finnish This is the approach given in this answer. It would make more sense to ask it there. I just used the approach from that answer to compare the timings. –
Stipulate
can you add the
dict.fromkeys() method to your chart please? –
Kassala I'm not really sure if I have the same to do the timings soonish. Do you think it's much faster than the
ordereddict.fromkeys? –
Stipulate "This iteration_utilities.unique_everseen function can also handle unhashable values in the input" -- yes, this is really important. If you have a list of dicts of dicts of dicts etc this is the only way to do the job, even at small scale. –
Chatterjee
why use this instead of
more_itertools.unique_everseen ? I'm not sure why they bear the same name –
Crazed @Crazed if you already have
more-itertools then that's probably better and easier to use the function from more-itertools (less dependencies). If you need to get the optimal performance then iteration_uitilities is (or at least was at the time of writing) significantly faster, it seems like ~2 times faster if I read the graphs correctly. If you don't care too much about performance: Just use what you want. E.g. there are implementations in other answers here that are pretty short and can probably copy&pasted easily :) –
Stipulate For another very late answer to another very old question:
The itertools recipes have a function that does this, using the seen set technique, but:
- Handles a standard
keyfunction. - Uses no unseemly hacks.
- Optimizes the loop by pre-binding
seen.addinstead of looking it up N times. (f7also does this, but some versions don't.) - Optimizes the loop by using
ifilterfalse, so you only have to loop over the unique elements in Python, instead of all of them. (You still iterate over all of them insideifilterfalse, of course, but that's in C, and much faster.)
Is it actually faster than f7? It depends on your data, so you'll have to test it and see. If you want a list in the end, f7 uses a listcomp, and there's no way to do that here. (You can directly append instead of yielding, or you can feed the generator into the list function, but neither one can be as fast as the LIST_APPEND inside a listcomp.) At any rate, usually, squeezing out a few microseconds is not going to be as important as having an easily-understandable, reusable, already-written function that doesn't require DSU when you want to decorate.
As with all of the recipes, it's also available in more-iterools.
If you just want the no-key case, you can simplify it as:
def unique(iterable):
seen = set()
seen_add = seen.add
for element in itertools.ifilterfalse(seen.__contains__, iterable):
seen_add(element)
yield element
I completely overlooked
more-itertools this is clearly the best answer. A simple from more_itertools import unique_everseen list(unique_everseen(items)) A much faster approach than mine and much better than the accepted answer, I think the library download is worth it. I am going to community wiki my answer and add this in. –
Pallium For no hashable types (e.g. list of lists), based on MizardX's:
def f7_noHash(seq)
seen = set()
return [ x for x in seq if str( x ) not in seen and not seen.add( str( x ) )]
pandas users should check out pandas.unique.
>>> import pandas as pd
>>> lst = [1, 2, 1, 3, 3, 2, 4]
>>> pd.unique(lst)
array([1, 2, 3, 4])
The function returns a NumPy array. If needed, you can convert it to a list with the tolist method.
Nice one. I would never imagine using pandas for that but it works –
Variety
list(pd.unique(a)) will convert it to the normal list that OP would want. upvoted for the pandas solution. Never thought of doing it this way. –
Excommunicate pd.unique(lst).tolist() is even better idiom. cc: @JoeFerndz –
Alfeus 5 x faster reduce variant but more sophisticated
>>> l = [5, 6, 6, 1, 1, 2, 2, 3, 4]
>>> reduce(lambda r, v: v in r[1] and r or (r[0].append(v) or r[1].add(v)) or r, l, ([], set()))[0]
[5, 6, 1, 2, 3, 4]
Explanation:
default = (list(), set())
# use list to keep order
# use set to make lookup faster
def reducer(result, item):
if item not in result[1]:
result[0].append(item)
result[1].add(item)
return result
>>> reduce(reducer, l, default)[0]
[5, 6, 1, 2, 3, 4]
here is a simple way to do it:
list1 = ["hello", " ", "w", "o", "r", "l", "d"]
sorted(set(list1 ), key=list1.index)
that gives the output:
["hello", " ", "w", "o", "r", "l", "d"]
You can reference a list comprehension as it is being built by the symbol '_[1]'.
For example, the following function unique-ifies a list of elements without changing their order by referencing its list comprehension.
def unique(my_list):
return [x for x in my_list if x not in locals()['_[1]']]
Demo:
l1 = [1, 2, 3, 4, 1, 2, 3, 4, 5]
l2 = [x for x in l1 if x not in locals()['_[1]']]
print l2
Output:
[1, 2, 3, 4, 5]
Also note that it would make it an O(n^2) operation, where as creating a set/dict (which has constant look up time) and adding only previously unseen elements will be linear. –
Longevity
This is Python 2.6 only I believe. And yes it is O(N^2) –
Pallium
What @Pallium means is that this works in Python 2.7 and earlier only, not later. –
Emulous
@GlennSlayden No I meant only Python 2.6. Python 2.6 and earlier (not sure how much earlier exactly). Python 2.6 was more popular at the time so that's why I said Python 2.6 only in comparison to Python 2.7 –
Pallium
@Pallium Ok, but my point is, not any Python 3.x, which wasn’t clear to me from your Jun 7 2015 comment. –
Emulous
Borrowing the recursive idea used in definining Haskell's nub function for lists, this would be a recursive approach:
def unique(lst):
return [] if lst==[] else [lst[0]] + unique(filter(lambda x: x!= lst[0], lst[1:]))
e.g.:
In [118]: unique([1,5,1,1,4,3,4])
Out[118]: [1, 5, 4, 3]
I tried it for growing data sizes and saw sub-linear time-complexity (not definitive, but suggests this should be fine for normal data).
In [122]: %timeit unique(np.random.randint(5, size=(1)))
10000 loops, best of 3: 25.3 us per loop
In [123]: %timeit unique(np.random.randint(5, size=(10)))
10000 loops, best of 3: 42.9 us per loop
In [124]: %timeit unique(np.random.randint(5, size=(100)))
10000 loops, best of 3: 132 us per loop
In [125]: %timeit unique(np.random.randint(5, size=(1000)))
1000 loops, best of 3: 1.05 ms per loop
In [126]: %timeit unique(np.random.randint(5, size=(10000)))
100 loops, best of 3: 11 ms per loop
I also think it's interesting that this could be readily generalized to uniqueness by other operations. Like this:
import operator
def unique(lst, cmp_op=operator.ne):
return [] if lst==[] else [lst[0]] + unique(filter(lambda x: cmp_op(x, lst[0]), lst[1:]), cmp_op)
For example, you could pass in a function that uses the notion of rounding to the same integer as if it was "equality" for uniqueness purposes, like this:
def test_round(x,y):
return round(x) != round(y)
then unique(some_list, test_round) would provide the unique elements of the list where uniqueness no longer meant traditional equality (which is implied by using any sort of set-based or dict-key-based approach to this problem) but instead meant to take only the first element that rounds to K for each possible integer K that the elements might round to, e.g.:
In [6]: unique([1.2, 5, 1.9, 1.1, 4.2, 3, 4.8], test_round)
Out[6]: [1.2, 5, 1.9, 4.2, 3]
Note that performance will get bad when the number of unique elements is very large relative to the total number of elements, since each successive recursive call's use of
filter will barely benefit from the previous call at all. But if the number of unique elements is small relative to the array size, this should perform pretty well. –
Longevity Eliminating the duplicate values in a sequence, but preserve the order of the remaining items. Use of general purpose generator function.
# for hashable sequence
def remove_duplicates(items):
seen = set()
for item in items:
if item not in seen:
yield item
seen.add(item)
a = [1, 5, 2, 1, 9, 1, 5, 10]
list(remove_duplicates(a))
# [1, 5, 2, 9, 10]
# for unhashable sequence
def remove_duplicates(items, key=None):
seen = set()
for item in items:
val = item if key is None else key(item)
if val not in seen:
yield item
seen.add(val)
a = [ {'x': 1, 'y': 2}, {'x': 1, 'y': 3}, {'x': 1, 'y': 2}, {'x': 2, 'y': 4}]
list(remove_duplicates(a, key=lambda d: (d['x'],d['y'])))
# [{'x': 1, 'y': 2}, {'x': 1, 'y': 3}, {'x': 2, 'y': 4}]
1. These solutions are fine…
For removing duplicates while preserving order, the excellent solution(s) proposed elsewhere on this page:
seen = set()
[x for x in seq if not (x in seen or seen.add(x))]
and variation(s), e.g.:
seen = set()
[x for x in seq if x not in seen and not seen.add(x)]
are indeed popular because they are simple, minimalistic, and deploy the correct hashing for optimal efficency. The main complaint about these seems to be that using the invariant None "returned" by method seen.add(x) as a constant (and therefore excess/unnecessary) value in a logical expression—just for its side-effect—is hacky and/or confusing.
2. …but they waste one hash lookup per iteration.
Surprisingly, given the amount of discussion and debate on this topic, there is actually a significant improvement to the code that seems to have been overlooked. As shown, each "test-and-set" iteration requires two hash lookups: the first to test membership x not in seen and then again to actually add the value seen.add(x). Since the first operation guarantees that the second will always be successful, there is a wasteful duplication of effort here. And because the overall technique here is so efficient, the excess hash lookups will likely end up being the most expensive proportion of what little work remains.
3. Instead, let the set do its job!
Notice that the examples above only call set.add with the foreknowledge that doing so will always result in an increase in set membership. The set itself never gets an chance to reject a duplicate; our code snippet has essentially usurped that role for itself. The use of explicit two-step test-and-set code is robbing set of its core ability to exclude those duplicates itself.
4. The single-hash-lookup code:
The following version cuts the number of hash lookups per iteration in half—from two down to just one.
seen = set()
[x for x in seq if len(seen) < len(seen.add(x) or seen)]
This really needs a benchmark. Function calls are relatively expensive, so I would not at all be surprised if this is slower. –
Martlet
I did one now with various sequences and indeed this is much slower. Please show your evidence for your claim that "This improves the performance [...] considerably". –
Martlet
@KellyBundy Thanks for the feedback; I edited my answer to remove the unsubstantiated claim. –
Emulous
I've compared all relevant answers with perfplot and found that,
list(dict.fromkeys(data))
is fastest. This also holds true for small numpy arrays. For larger numpy arrays, pandas.unique is actually fastest.
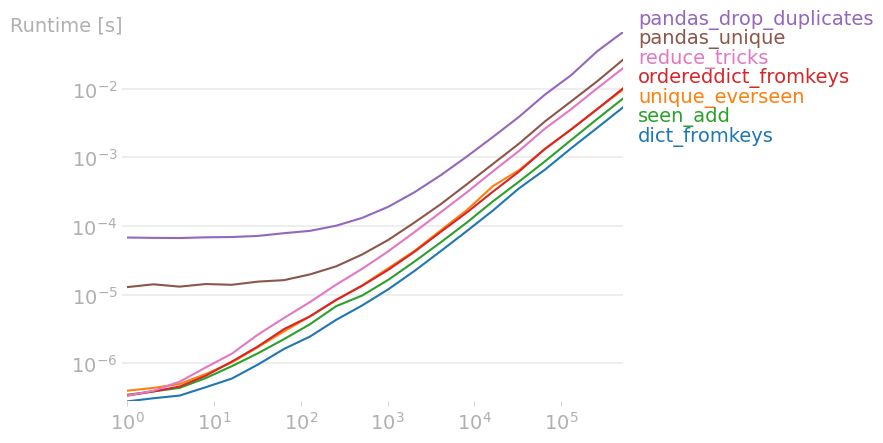
Code to reproduce the plot:
from collections import OrderedDict
from functools import reduce
from itertools import groupby
import numpy as np
import pandas as pd
import perfplot
from more_itertools import unique_everseen as ue
def dict_fromkeys(data):
return list(dict.fromkeys(data))
def unique_everseen(data):
return list(ue(data))
def seen_add(data):
seen = set()
seen_add = seen.add
return [x for x in data if not (x in seen or seen_add(x))]
def ordereddict_fromkeys(data):
return list(OrderedDict.fromkeys(data))
def pandas_drop_duplicates(data):
return pd.Series(data).drop_duplicates().tolist()
def pandas_unique(data):
return pd.unique(data)
def itertools_groupby(data):
return [key for key, _ in groupby(data)]
def reduce_tricks(data):
return reduce(
lambda r, v: v in r[1] and r or (r[0].append(v) or r[1].add(v)) or r,
data,
([], set()),
)[0]
b = perfplot.bench(
setup=lambda n: np.random.randint(100, size=n).tolist(),
kernels=[
dict_fromkeys,
unique_everseen,
seen_add,
ordereddict_fromkeys,
pandas_drop_duplicates,
pandas_unique,
reduce_tricks,
],
n_range=[2**k for k in range(20)],
)
b.save("out.png")
b.show()
Actually... It would be good to vary not just the input size but also the output size. I.e., the amount of duplication. MSeifert's answer did that fairly well, with its three plots from "no duplicates" to "only duplicates". –
Martlet
If you need one liner then maybe this would help:
reduce(lambda x, y: x + y if y[0] not in x else x, map(lambda x: [x],lst))
... should work but correct me if i'm wrong
it's a conditional expression so it's good –
Richman
In Python 3, you have to
from functools import reduce. –
Bogy MizardX's answer gives a good collection of multiple approaches.
This is what I came up with while thinking aloud:
mylist = [x for i,x in enumerate(mylist) if x not in mylist[i+1:]]
Your solution is nice, but it takes the last appearance of each element. To take the first appearance use: [x for i,x in enumerate(mylist) if x not in mylist[:i]] –
Speiss
Since searching in a list is an
O(n) operation and you perform it on each item, the resulting complexity of your solution would be O(n^2). This is just unacceptable for such a trivial problem. –
Zedoary Relatively effective approach with _sorted_ a numpy arrays:
b = np.array([1,3,3, 8, 12, 12,12])
numpy.hstack([b[0], [x[0] for x in zip(b[1:], b[:-1]) if x[0]!=x[1]]])
Outputs:
array([ 1, 3, 8, 12])
You could do a sort of ugly list comprehension hack.
[l[i] for i in range(len(l)) if l.index(l[i]) == i]
Prefer
i,e in enumerate(l) to l[i] for i in range(len(l)). –
Compulsory l = [1,2,2,3,3,...]
n = []
n.extend(ele for ele in l if ele not in set(n))
A generator expression that uses the O(1) look up of a set to determine whether or not to include an element in the new list.
Clever use of
extend with a generator expression which depends on the thing being extended (so +1), but set(n) is recomputed at each stage (which is linear) and this bumps the overall approach to being quadratic. In fact, this is almost certainly worse than simply using ele in n. Making a set for a single membership test isn't worth the expense of the set creation. Still -- it is an interesting approach. –
Infuscate A simple recursive solution:
def uniquefy_list(a):
return uniquefy_list(a[1:]) if a[0] in a[1:] else [a[0]]+uniquefy_list(a[1:]) if len(a)>1 else [a[0]]
this will preserve order and run in O(n) time. basically the idea is to create a hole wherever there is a duplicate found and sink it down to the bottom. makes use of a read and write pointer. whenever a duplicate is found only the read pointer advances and write pointer stays on the duplicate entry to overwrite it.
def deduplicate(l):
count = {}
(read,write) = (0,0)
while read < len(l):
if l[read] in count:
read += 1
continue
count[l[read]] = True
l[write] = l[read]
read += 1
write += 1
return l[0:write]
One liner list comprehension:
values_non_duplicated = [value for index, value in enumerate(values) if value not in values[ : index]]
x = [1, 2, 1, 3, 1, 4]
# brute force method
arr = []
for i in x:
if not i in arr:
arr.insert(x[i],i)
# recursive method
tmp = []
def remove_duplicates(j=0):
if j < len(x):
if not x[j] in tmp:
tmp.append(x[j])
i = j+1
remove_duplicates(i)
remove_duplicates()
If you routinely use pandas, and aesthetics is preferred over performance, then consider the built-in function pandas.Series.drop_duplicates:
import pandas as pd
import numpy as np
uniquifier = lambda alist: pd.Series(alist).drop_duplicates().tolist()
# from the chosen answer
def f7(seq):
seen = set()
seen_add = seen.add
return [ x for x in seq if not (x in seen or seen_add(x))]
alist = np.random.randint(low=0, high=1000, size=10000).tolist()
print uniquifier(alist) == f7(alist) # True
Timing:
In [104]: %timeit f7(alist)
1000 loops, best of 3: 1.3 ms per loop
In [110]: %timeit uniquifier(alist)
100 loops, best of 3: 4.39 ms per loop
A solution without using imported modules or sets:
text = "ask not what your country can do for you ask what you can do for your country"
sentence = text.split(" ")
noduplicates = [(sentence[i]) for i in range (0,len(sentence)) if sentence[i] not in sentence[:i]]
print(noduplicates)
Gives output:
['ask', 'not', 'what', 'your', 'country', 'can', 'do', 'for', 'you']
this is O(N**2) complexity + list slicing each time. –
Exeat
An in-place method
This method is quadratic, because we have a linear lookup into the list for every element of the list (to that we have to add the cost of rearranging the list because of the del s).
That said, it is possible to operate in place if we start from the end of the list and proceed toward the origin removing each term that is present in the sub-list at its left
This idea in code is simply
for i in range(len(l)-1,0,-1):
if l[i] in l[:i]: del l[i]
A simple test of the implementation
In [91]: from random import randint, seed
In [92]: seed('20080808') ; l = [randint(1,6) for _ in range(12)] # Beijing Olympics
In [93]: for i in range(len(l)-1,0,-1):
...: print(l)
...: print(i, l[i], l[:i], end='')
...: if l[i] in l[:i]:
...: print( ': remove', l[i])
...: del l[i]
...: else:
...: print()
...: print(l)
[6, 5, 1, 4, 6, 1, 6, 2, 2, 4, 5, 2]
11 2 [6, 5, 1, 4, 6, 1, 6, 2, 2, 4, 5]: remove 2
[6, 5, 1, 4, 6, 1, 6, 2, 2, 4, 5]
10 5 [6, 5, 1, 4, 6, 1, 6, 2, 2, 4]: remove 5
[6, 5, 1, 4, 6, 1, 6, 2, 2, 4]
9 4 [6, 5, 1, 4, 6, 1, 6, 2, 2]: remove 4
[6, 5, 1, 4, 6, 1, 6, 2, 2]
8 2 [6, 5, 1, 4, 6, 1, 6, 2]: remove 2
[6, 5, 1, 4, 6, 1, 6, 2]
7 2 [6, 5, 1, 4, 6, 1, 6]
[6, 5, 1, 4, 6, 1, 6, 2]
6 6 [6, 5, 1, 4, 6, 1]: remove 6
[6, 5, 1, 4, 6, 1, 2]
5 1 [6, 5, 1, 4, 6]: remove 1
[6, 5, 1, 4, 6, 2]
4 6 [6, 5, 1, 4]: remove 6
[6, 5, 1, 4, 2]
3 4 [6, 5, 1]
[6, 5, 1, 4, 2]
2 1 [6, 5]
[6, 5, 1, 4, 2]
1 5 [6]
[6, 5, 1, 4, 2]
In [94]:
Before posting I have searched the body of the answers for 'place' to no avail. If others have solved the problem in a similar way please alert me and I'll remove my answer asap. –
Neologism
You could just use
l[:] = <one of the the faster methods> if you wanted an in-place operation, no? –
Leveridge @Leveridge Yes and no… When I do
a=[1]; b=a; a[:]=[2] then b==[2] value is True and we can say that we are doing it in-place, nevertheless what you propose is using new space to have a new list, replace the old data with the new data and mark the old data for garbage collection because is no more referenced by anything, so saying it's operating in-place is a little bit stretching the concept wrt what I've shown it is possible... is it inefficient? yes, but I've told that in advance. –
Neologism © 2022 - 2024 — McMap. All rights reserved.
seen.addreally resolved each iteration? Wouldn't it be resolved once when the list comprehension is parsed and transformed? – Syntactics