The WORST possible scenario is using plain old strcat (or sprintf), since strcat takes a C string, and that has to be "counted" to find the end. For long strings, that's a real performance sufferer. C++ style strings are much better, and the performance problems are likely to be with the memory allocation, rather than counting lengths. But then again, the string grows geometrically (doubles each time it needs to grow), so it's not that terrible.
I'd very much suspect that all of the above methods end up with the same, or at least very similar, performance. If anything, I'd expect that stringstream is slower, because of the overhead in supporting formatting - but I also suspect it's marginal.
As this sort of thing is "fun", I will get back with a benchmark...
Edit:
Note that these result apply to MY machine, running x86-64 Linux, compiled with g++ 4.6.3. Other OS's, compilers and C++ runtime library implementations may vary. If performance is important to your application, then benchmark on the system(s) that are critical for you, using the compiler(s) that you use.
Here's the code I wrote to test this. It may not be the perfect representation of a real scenario, but I think it's a representative scenario:
#include <iostream>
#include <iomanip>
#include <string>
#include <sstream>
#include <cstring>
using namespace std;
static __inline__ unsigned long long rdtsc(void)
{
unsigned hi, lo;
__asm__ __volatile__ ("rdtsc" : "=a"(lo), "=d"(hi));
return ( (unsigned long long)lo)|( ((unsigned long long)hi)<<32 );
}
string build_string_1(const string &a, const string &b, const string &c)
{
string out = a + b + c;
return out;
}
string build_string_1a(const string &a, const string &b, const string &c)
{
string out;
out.resize(a.length()*3);
out = a + b + c;
return out;
}
string build_string_2(const string &a, const string &b, const string &c)
{
string out = a;
out += b;
out += c;
return out;
}
string build_string_3(const string &a, const string &b, const string &c)
{
string out;
out = a;
out.append(b);
out.append(c);
return out;
}
string build_string_4(const string &a, const string &b, const string &c)
{
stringstream ss;
ss << a << b << c;
return ss.str();
}
char *build_string_5(const char *a, const char *b, const char *c)
{
char* out = new char[strlen(a) * 3+1];
strcpy(out, a);
strcat(out, b);
strcat(out, c);
return out;
}
template<typename T>
size_t len(T s)
{
return s.length();
}
template<>
size_t len(char *s)
{
return strlen(s);
}
template<>
size_t len(const char *s)
{
return strlen(s);
}
void result(const char *name, unsigned long long t, const string& out)
{
cout << left << setw(22) << name << " time:" << right << setw(10) << t;
cout << " (per character: "
<< fixed << right << setw(8) << setprecision(2) << (double)t / len(out) << ")" << endl;
}
template<typename T>
void benchmark(const char name[], T (Func)(const T& a, const T& b, const T& c), const char *strings[])
{
unsigned long long t;
const T s1 = strings[0];
const T s2 = strings[1];
const T s3 = strings[2];
t = rdtsc();
T out = Func(s1, s2, s3);
t = rdtsc() - t;
if (len(out) != len(s1) + len(s2) + len(s3))
{
cout << "Error: out is different length from inputs" << endl;
cout << "Got `" << out << "` from `" << s1 << "` + `" << s2 << "` + `" << s3 << "`";
}
result(name, t, out);
}
void benchmark(const char name[], char* (Func)(const char* a, const char* b, const char* c),
const char *strings[])
{
unsigned long long t;
const char* s1 = strings[0];
const char* s2 = strings[1];
const char* s3 = strings[2];
t = rdtsc();
char *out = Func(s1, s2, s3);
t = rdtsc() - t;
if (len(out) != len(s1) + len(s2) + len(s3))
{
cout << "Error: out is different length from inputs" << endl;
cout << "Got `" << out << "` from `" << s1 << "` + `" << s2 << "` + `" << s3 << "`";
}
result(name, t, out);
delete [] out;
}
#define BM(func, size) benchmark(#func " " #size, func, strings ## _ ## size)
#define BM_LOT(size) BM(build_string_1, size); \
BM(build_string_1a, size); \
BM(build_string_2, size); \
BM(build_string_3, size); \
BM(build_string_4, size); \
BM(build_string_5, size);
int main()
{
const char *strings_small[] = { "Abc", "Def", "Ghi" };
const char *strings_medium[] = { "abcdefghijklmnopqrstuvwxyz",
"defghijklmnopqrstuvwxyzabc",
"ghijklmnopqrstuvwxyzabcdef" };
const char *strings_large[] =
{ "abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz"
"abcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyz",
"defghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabc"
"defghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabc"
"defghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabc"
"defghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabc"
"defghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabc"
"defghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabc"
"defghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabc"
"defghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabc"
"defghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabc"
"defghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabc",
"ghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdef"
"ghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdef"
"ghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdef"
"ghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdef"
"ghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdef"
"ghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdef"
"ghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdef"
"ghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdef"
"ghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdef"
"ghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcdef"
};
for(int i = 0; i < 5; i++)
{
BM_LOT(small);
BM_LOT(medium);
BM_LOT(large);
cout << "---------------------------------------------" << endl;
}
}
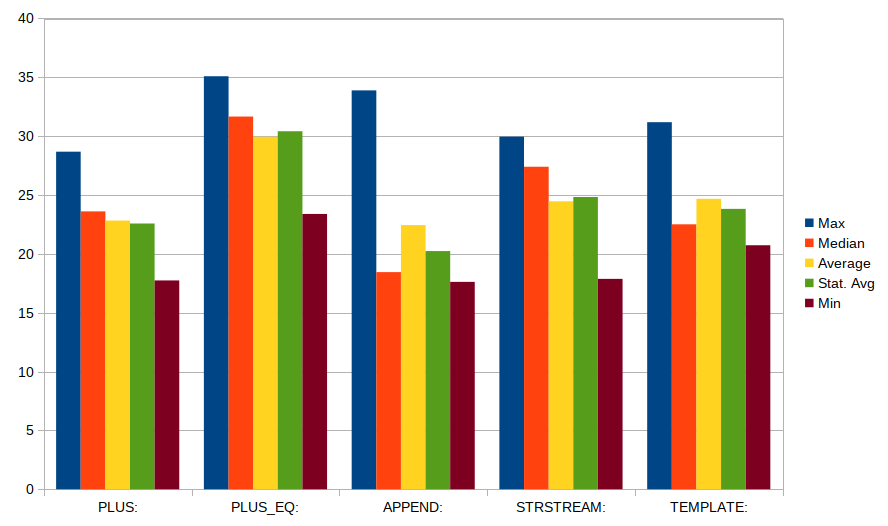
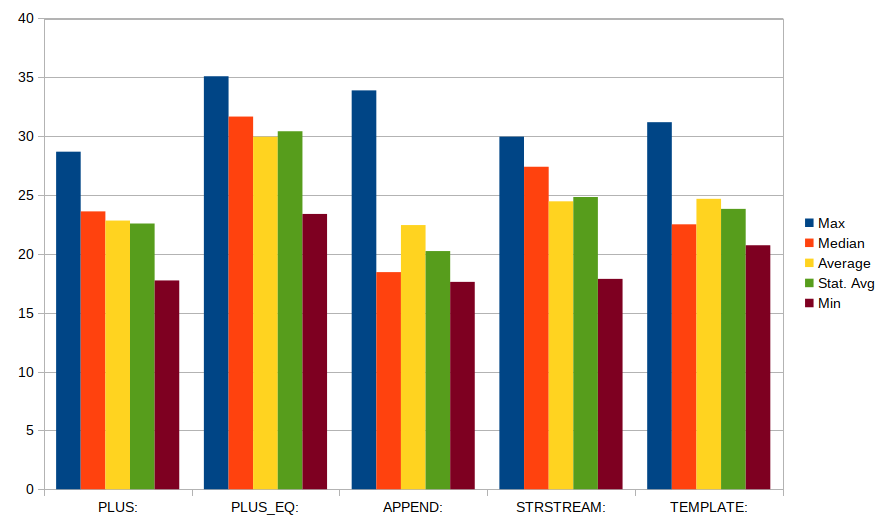
Here are some representative results:
build_string_1 small time: 4075 (per character: 452.78)
build_string_1a small time: 5384 (per character: 598.22)
build_string_2 small time: 2669 (per character: 296.56)
build_string_3 small time: 2427 (per character: 269.67)
build_string_4 small time: 19380 (per character: 2153.33)
build_string_5 small time: 6299 (per character: 699.89)
build_string_1 medium time: 3983 (per character: 51.06)
build_string_1a medium time: 6970 (per character: 89.36)
build_string_2 medium time: 4072 (per character: 52.21)
build_string_3 medium time: 4000 (per character: 51.28)
build_string_4 medium time: 19614 (per character: 251.46)
build_string_5 medium time: 6304 (per character: 80.82)
build_string_1 large time: 8491 (per character: 3.63)
build_string_1a large time: 9563 (per character: 4.09)
build_string_2 large time: 6154 (per character: 2.63)
build_string_3 large time: 5992 (per character: 2.56)
build_string_4 large time: 32450 (per character: 13.87)
build_string_5 large time: 15768 (per character: 6.74)
Same code, run as 32-bit:
build_string_1 small time: 4289 (per character: 476.56)
build_string_1a small time: 5967 (per character: 663.00)
build_string_2 small time: 3329 (per character: 369.89)
build_string_3 small time: 3047 (per character: 338.56)
build_string_4 small time: 22018 (per character: 2446.44)
build_string_5 small time: 3026 (per character: 336.22)
build_string_1 medium time: 4089 (per character: 52.42)
build_string_1a medium time: 8075 (per character: 103.53)
build_string_2 medium time: 4569 (per character: 58.58)
build_string_3 medium time: 4326 (per character: 55.46)
build_string_4 medium time: 22751 (per character: 291.68)
build_string_5 medium time: 2252 (per character: 28.87)
build_string_1 large time: 8695 (per character: 3.72)
build_string_1a large time: 12818 (per character: 5.48)
build_string_2 large time: 8202 (per character: 3.51)
build_string_3 large time: 8351 (per character: 3.57)
build_string_4 large time: 38250 (per character: 16.35)
build_string_5 large time: 8143 (per character: 3.48)
From this, we can conclude:
The best option is appending a bit at a time (out.append() or out +=), with the "chained" approach reasonably close.
Pre-allocating the string is not helpful.
Using stringstream is pretty poor idea (between 2-4x slower).
The char * uses new char[]. Using a local variable in the calling function makes it the fastest - but slightly unfairly to compare that.
There is a fair bit of overhead in combining short string - just copying data should be at most one cycle per byte [unless the data doesn't fit in the cache].
edit2
Added, as per comments:
string build_string_1b(const string &a, const string &b, const string &c)
{
return a + b + c;
}
and
string build_string_2a(const string &a, const string &b, const string &c)
{
string out;
out.reserve(a.length() * 3);
out += a;
out += b;
out += c;
return out;
}
Which gives these results:
build_string_1 small time: 3845 (per character: 427.22)
build_string_1b small time: 3165 (per character: 351.67)
build_string_2 small time: 3176 (per character: 352.89)
build_string_2a small time: 1904 (per character: 211.56)
build_string_1 large time: 9056 (per character: 3.87)
build_string_1b large time: 6414 (per character: 2.74)
build_string_2 large time: 6417 (per character: 2.74)
build_string_2a large time: 4179 (per character: 1.79)
(A 32-bit run, but the 64-bit shows very similar results on these).
{kind=link}
stringstreamis built for this use case,stringis not. So it is probably a good bet to start out withstringstream. – Bicapsularl_czTempStr = std::string("Test data1") + "Test data2" + "Test data3";. Other than that the answer is to time the different techniques. There are so many variables that it's is impossible to answer the question. The answer depends on the number and length of strings you are working with, plus the platform you are compiling on, and the platform you are compiling for. – Consolute+creates a new object, with some special cases in C++11). But don't optimise this unless you need to or your code will be unreadable. – Wittystd::ostringstreamis designed for formatting, and should normally only be used when you need formatting. All of his data are strings, sostd::stringand concatenation are the preferred solution. – Petuastd::ostream? Or "formatted output" (the term used in the standard to describe<<on anstd::ostream)? – Petuastringis as efficient as you can get and using aostreamcan only add overhead to the process (multiplevirtualcalls). – Lycurgusl_czTempStr) over and over, or do you use a new buffer each time ? Do you have the ability toreservethe memory when creating the buffer or do you append blind (causing reallocations) ? – Lycurgus