Is there a way to make pandas Dataframes observable?
Lets say I have some Dataframes A, B, C that have the same index and C is calculated by
C = A + B
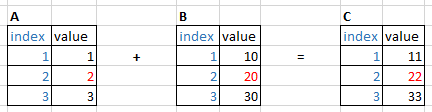
If I change a cell value in A (e.g. 2 => 4), I would like to automatically update the corresponding cell in C (e.g. 22 => 24).
=> How can I listen to changes in Dataframe A?
Is there some observable Dataframe, triggers or events I could use for that? If that is not possible with pandas Dataframes, is there some other observable table structure I could use?
Or would I need to implement my own spreadsheets?
Additional information:
The index of my tables might consist of multiple columns. There might be multiple value columns, too.
It would be great if I could use that data structure together with RxPy, so that I can create reactive pipes for table calculations.
My calculation pipes/chains might contain hundreds of tables. That's why I don't want to use Excel.
If it is hard to do such things in Python, I am also open for solutions based on JavaScript.
Related stuff
Here is some information I found so far. PyQt tables might be a way to go, because they support change events. However, I am looking for something with "less overhead" for my calculations.