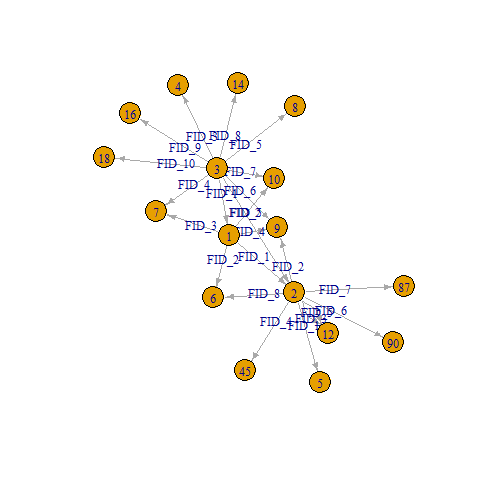
I want to identify networks where all people in the same network directly or indirectly connected through friendship nominations while no students from different networks are connected.
I am using the Add Health data. Each student nominates upto 10 friends. Say, sample data may look like this:
ID FID_1 FID_2 FID_3 FID_4 FID_5 FID_6 FID_7 FID_8 FID_9 FID_10
1 2 6 7 9 10 NA NA NA NA NA
2 5 9 12 45 13 90 87 6 NA NA
3 1 2 4 7 8 9 10 14 16 18
100 110 120 122 125 169 178 190 200 500 520
500 100 110 122 125 169 178 190 200 500 520
700 800 789 900 NA NA NA NA NA NA NA
1000 789 2000 820 900 NA NA NA NA NA NA
There are around 85,000 individuals. Could anyone please tell me how I can get network ID? So, I would like the data to look the following
ID network_ID ID network_ID
1 1 700 3
2 1 789 3
3 1 800 3
4 1 820 3
5 1 900 3
6 1 1000 3
7 1 2000 3
8 1
9 1
10 1
12 1
13 1
14 1
16 1
18 1
90 1
87 1
100 2
110 2
120 2
122 2
125 2
169 2
178 2
190 2
200 2
500 2
520 2
So, everyone directly or indirectly connected to ID 1 belong to network 1. 2 is a friend of 1. So, everyone directly or indirectly connected to 2 are also in 1's network and so on. 700 is not connected to 1 or friend of 1 or friend of friend of 1 and so on. Thus 700 is in a different network, which is network 3.
Any help will be much appreciated...
Network_ID|Student_ID, in which each row indicates the membership of that student in that network? This would be awkward as a wide table (Network_ID|Student_1_ID|Student_2_ID|Student_3_ID| ...) because, theoretically, there could be a "friendship path" connecting all of your students...and the wide table would need a new column for every student. UPDATE: Just saw your edit. Looks like my guess was right! – Diacetylmorphinetidyr::pivot_longer(). As for network analysis, there should definitely be something in this helpful article, though I'm still checking if any of those packages allow for the kind of tabulated output you desire. If not, a recursive algorithm should do the trick... – Diacetylmorphine