As known in since C++11 there are 6 memory orders, and in documentation written about std::memory_order_acquire:
memory_order_acquire
A load operation with this memory order performs the acquire operation on the affected memory location: no memory accesses in the current thread can be reordered before this load. This ensures that all writes in other threads that release the same atomic variable are visible in the current thread.
1. Non-atomic-load can be reordered after atomic-acquire-load:
I.e. it does not guarantee that non-atomic-load can not be reordered after acquire-atomic-load.
static std::atomic<int> X;
static int L;
...
void thread_func()
{
int local1 = L; // load(L)-load(X) - can be reordered with X ?
int x_local = X.load(std::memory_order_acquire); // load(X)
int local2 = L; // load(X)-load(L) - can't be reordered with X
}
Can load int local1 = L; be reordered after X.load(std::memory_order_acquire);?
2. We can think that non-atomic-load can not be reordered after atomic-acquire-load:
Some articles contained a picture showing the essence of acquire-release semantics. That is easy to understand, but can cause confusion.
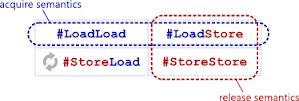

For example, we may think that std::memory_order_acquire can't reorder any series of Load-Load operations, even non-atomic-load can't be reordered after atomic-acquire-load.
3. Non-atomic-load can be reordered after atomic-acquire-load:
Good thing that there is clarified: Acquire semantics prevent memory reordering of the read-acquire with any read or write operation which follows it in program order. http://preshing.com/20120913/acquire-and-release-semantics/
But also known, that: On strongly-ordered systems (x86, SPARC TSO, IBM mainframe), release-acquire ordering is automatic for the majority of operations.
And Herb Sutter on page 34 shows: https://onedrive.live.com/view.aspx?resid=4E86B0CF20EF15AD!24884&app=WordPdf&authkey=!AMtj_EflYn2507c
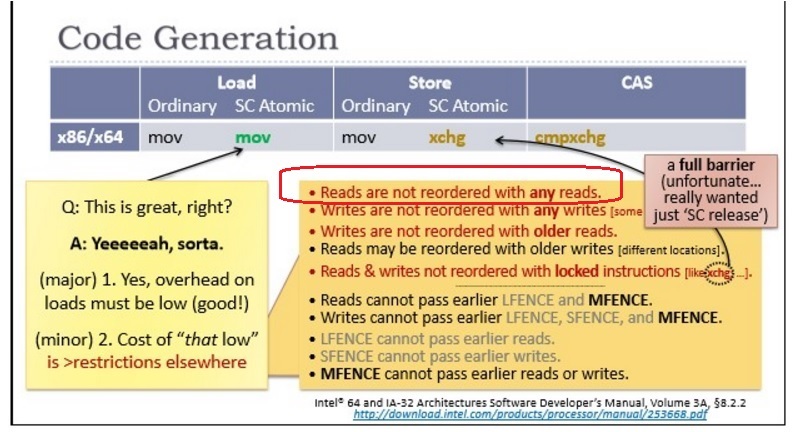
4. I.e. again, we can think that non-atomic-load can not be reordered after atomic-acquire-load:
I.e. for x86:
- release-acquire ordering is automatic for the majority of operations
- Reads are not reordered with any reads. (any - i.e. regardless of older or not)
So can non-atomic-load be reordered after atomic-acquire-load in C++11?
L, you have a data race. Therefore, from the standpoint of the C++ standard, the question is moot. – ShulemLto ensure such a relationship? I just don't see it. – ShulemLare synchronized with this read, then it wouldn't matter whether or not it gets reordered with the load ofX. Once again, a program with such synchronization wouldn't be able to detect whether the reordering occurred, so why would anyone care? Can you show an example that a) is race-free, and b) would produce different output depending on whether the reordering occurred? – Shulemthread_func()your whole thread? – Abyssal