I have vectors stored in BigQuery (see How can I compute TF/IDF with SQL (BigQuery)), and I want to find the most similar between them. How can I compute the cosine similarity with BigQuery standard SQL?
Cosine similarity with BigQuery SQL?
Asked Answered
This query looks at the vector defined for each doc, given its dimensions (by word) and multiplies them with the cosine distance formula:
#standardSQL
SELECT ANY_VALUE(title2) orig, ANY_VALUE(tf2id) id_orig, a.id id_similar
, ROUND(SAFE_DIVIDE( SUM(b.tf_idf * IFNULL(c.tf_idf,0)),(SQRT(SUM(b.tf_idf*b.tf_idf))*SQRT(SUM(POW(IFNULL(c.tf_idf,0),2))))),4) distance
, ANY_VALUE(title1) similar
, ARRAY_AGG((ROUND(b.tf_idf,4), ROUND(c.tf_idf,4))) weights
, ARRAY_AGG((b.word, c.word)) words
FROM (
SELECT id, tfidfs tf1, tf2, tf2id
, a.title title1
, b.title title2
FROM `fh-bigquery.stackoverflow.tf_idf_experiment_3` a
CROSS JOIN (
SELECT tfidfs tf2, id tf2id, title
FROM `fh-bigquery.stackoverflow.tf_idf_experiment_3`
WHERE id = 11353679
LIMIT 1
) b
) a
, UNNEST(tf1) b LEFT JOIN UNNEST(tf2) c ON b.word=c.word
GROUP BY id
ORDER BY distance DESC
First result is the same document, proving that we get distance 1 on itself:
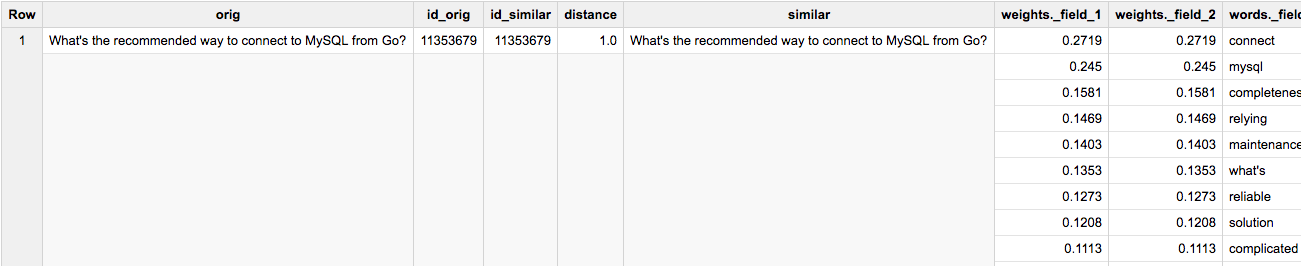
Second result:

Etc:

Caveat: This SQL code does a LEFT JOIN, so we only get nulls for words on the left document not on the right, and not the opposite.
Great answer from @Felipe Hoffa. Cosine distance (as well as Euclidean and Manhattan distances) are now native functions in BigQuery.
For two vectors (stored as arrays) a and b, 1 - ML.DISTANCE(a, b, 'COSINE') yields the cosine similarity for a, b.
Docs https://cloud.google.com/bigquery/docs/reference/standard-sql/bigqueryml-syntax-distance
Relationship between Cosine distance and Cosine similarity https://en.wikipedia.org/wiki/Cosine_similarity#Cosine_Distance
© 2022 - 2024 — McMap. All rights reserved.