I'm doing text analysis over reddit comments, and I want to calculate the TF-IDF within BigQuery.
How can I compute TF/IDF with SQL (BigQuery)
Asked Answered
This one might be easier to understand - takes a dataset that already has the # of words per TV station and day:
# in this query the combination of date+station represents a "document"
WITH data AS (
SELECT *
FROM `gdelt-bq.gdeltv2.iatv_1grams`
WHERE DATE BETWEEN 20190601 AND 20190629
AND station NOT IN ('KSTS', 'KDTV')
)
, word_day_station AS (
# how many times a word is mentioned in each "document"
SELECT word, SUM(count) counts, date, station
FROM data
GROUP BY 1, 3, 4
)
, day_station AS (
# total # of words in each "document"
SELECT SUM(count) counts, date, station
FROM data
GROUP BY 2,3
)
, tf AS (
# TF for a word in a "document"
SELECT word, date, station, a.counts/b.counts tf
FROM word_day_station a
JOIN day_station b
USING(date, station)
)
, word_in_docs AS (
# how many "documents" have a word
SELECT word, COUNT(DISTINCT FORMAT('%i %s', date, station)) indocs
FROM word_day_station
GROUP BY 1
)
, total_docs AS (
# total # of docs
SELECT COUNT(DISTINCT FORMAT('%i %s', date, station)) total_docs
FROM data
)
, idf AS (
# IDF for a word
SELECT word, LOG(total_docs.total_docs/indocs) idf
FROM word_in_docs
CROSS JOIN total_docs
)
SELECT date,
ARRAY_AGG(STRUCT(station, ARRAY_TO_STRING(words, ', ')) ORDER BY station) top_words
FROM (
SELECT date, station, ARRAY_AGG(word ORDER BY tfidf DESC LIMIT 5) words
FROM (
SELECT word, date, station, tf.tf * idf.idf tfidf
FROM tf
JOIN idf
USING(word)
)
GROUP BY date, station
)
GROUP BY date
ORDER BY date DESC
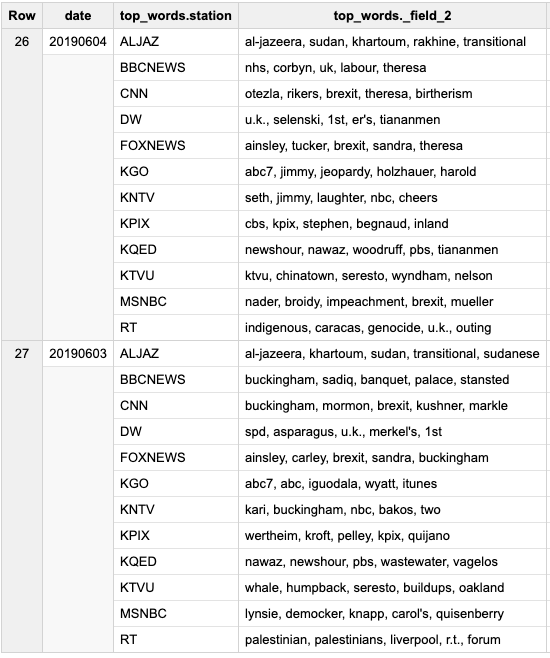
This query works on 5 stages:
- Obtain all reddit posts I'm interested in. Normalize words (LOWER, only letters and
', unescape some HTML). Split those words into an array. - Calculate the tf (term frequency) for each word in each doc - count how many times it shows up in each doc, relative to the number of words in said doc.
- For each word, calculate the number of docs that contain it.
- From (3.), obtain idf (inverse document frequency): "inverse fraction of the documents that contain the word, obtained by dividing the total number of documents by the number of documents containing the term, and then taking the logarithm of that quotient"
- Multiply tf*idf to obtain tf-idf.
This query manages to do this on one pass, by passing the obtained values up the chain.
#standardSQL
WITH words_by_post AS (
SELECT CONCAT(link_id, '/', id) id, REGEXP_EXTRACT_ALL(
REGEXP_REPLACE(REGEXP_REPLACE(LOWER(body), '&', '&'), r'&[a-z]{2,4};', '*')
, r'[a-z]{2,20}\'?[a-z]+') words
, COUNT(*) OVER() docs_n
FROM `fh-bigquery.reddit_comments.2017_07`
WHERE body NOT IN ('[deleted]', '[removed]')
AND subreddit = 'movies'
AND score > 100
), words_tf AS (
SELECT id, word, COUNT(*) / ARRAY_LENGTH(ANY_VALUE(words)) tf, ARRAY_LENGTH(ANY_VALUE(words)) words_in_doc
, ANY_VALUE(docs_n) docs_n
FROM words_by_post, UNNEST(words) word
GROUP BY id, word
HAVING words_in_doc>30
), docs_idf AS (
SELECT tf.id, word, tf.tf, ARRAY_LENGTH(tfs) docs_with_word, LOG(docs_n/ARRAY_LENGTH(tfs)) idf
FROM (
SELECT word, ARRAY_AGG(STRUCT(tf, id, words_in_doc)) tfs, ANY_VALUE(docs_n) docs_n
FROM words_tf
GROUP BY 1
), UNNEST(tfs) tf
)
SELECT *, tf*idf tfidf
FROM docs_idf
WHERE docs_with_word > 1
ORDER BY tfidf DESC
LIMIT 1000
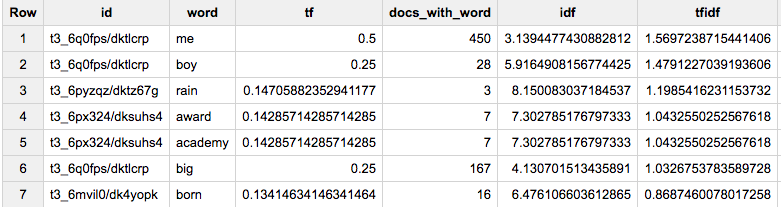
Thanks for checking @MikhailBerlyant! The difference would be if words can end on a
'? –
Ferous That is exactly what I thought - so check what if comment has word surraunding apostrophy - like 'abc' for example :o) –
Kordofanian
I was successful in getting this to work on a completely different data set. Thank you! Now I am trying to add stemming into the mix. If you have a stemming version, I'd love to see it. My plan is to use a simple dictionary stemmer and do a join to replace the 'word' with a 'stem'. Any suggestions on better approaches? –
Piste
Stack Overflow dataset version:
#standardSQL
WITH words_by_post AS (
SELECT id, REGEXP_EXTRACT_ALL(
REGEXP_REPLACE(
REGEXP_REPLACE(
REGEXP_REPLACE(
LOWER(CONCAT(title, ' ', body))
, r'&', '&')
, r'&[a-z]*;', '')
, r'<[= \-:a-z0-9/\."]*>', '')
, r'[a-z]{2,20}\'?[a-z]+') words
, title, body
, COUNT(*) OVER() docs_n
FROM `bigquery-public-data.stackoverflow.posts_questions`
WHERE score >= 150
), words_tf AS (
SELECT id, words
, ARRAY(
SELECT AS STRUCT w word, COUNT(*)/ARRAY_LENGTH(words) tf
FROM UNNEST(words) a
JOIN (SELECT DISTINCT w FROM UNNEST(words) w) b
ON a=b.w
WHERE w NOT IN ('the', 'and', 'for', 'this', 'that', 'can', 'but')
GROUP BY word ORDER BY word
) tfs
, ARRAY_LENGTH((words)) words_in_doc
, docs_n
, title, body
FROM words_by_post
WHERE ARRAY_LENGTH(words)>20
), docs_idf AS (
SELECT *, LOG(docs_n/docs_with_word) idf
FROM (
SELECT id, word, tf.tf, COUNTIF(word IN UNNEST(words)) OVER(PARTITION BY word) docs_with_word, docs_n
, title, body
FROM words_tf, UNNEST(tfs) tf
)
)
SELECT id, ARRAY_AGG(STRUCT(word, tf*idf AS tf_idf, docs_with_word) ORDER BY tf*idf DESC) tfidfs
# , ANY_VALUE(title) title, ANY_VALUE(body) body # makes query slower
FROM docs_idf
WHERE docs_with_word > 1
GROUP BY 1
Improvements versus the previous answer: One less GROUP BY across the dataset is needed, helping the query run faster.
This one might be easier to understand - takes a dataset that already has the # of words per TV station and day:
# in this query the combination of date+station represents a "document"
WITH data AS (
SELECT *
FROM `gdelt-bq.gdeltv2.iatv_1grams`
WHERE DATE BETWEEN 20190601 AND 20190629
AND station NOT IN ('KSTS', 'KDTV')
)
, word_day_station AS (
# how many times a word is mentioned in each "document"
SELECT word, SUM(count) counts, date, station
FROM data
GROUP BY 1, 3, 4
)
, day_station AS (
# total # of words in each "document"
SELECT SUM(count) counts, date, station
FROM data
GROUP BY 2,3
)
, tf AS (
# TF for a word in a "document"
SELECT word, date, station, a.counts/b.counts tf
FROM word_day_station a
JOIN day_station b
USING(date, station)
)
, word_in_docs AS (
# how many "documents" have a word
SELECT word, COUNT(DISTINCT FORMAT('%i %s', date, station)) indocs
FROM word_day_station
GROUP BY 1
)
, total_docs AS (
# total # of docs
SELECT COUNT(DISTINCT FORMAT('%i %s', date, station)) total_docs
FROM data
)
, idf AS (
# IDF for a word
SELECT word, LOG(total_docs.total_docs/indocs) idf
FROM word_in_docs
CROSS JOIN total_docs
)
SELECT date,
ARRAY_AGG(STRUCT(station, ARRAY_TO_STRING(words, ', ')) ORDER BY station) top_words
FROM (
SELECT date, station, ARRAY_AGG(word ORDER BY tfidf DESC LIMIT 5) words
FROM (
SELECT word, date, station, tf.tf * idf.idf tfidf
FROM tf
JOIN idf
USING(word)
)
GROUP BY date, station
)
GROUP BY date
ORDER BY date DESC
© 2022 - 2024 — McMap. All rights reserved.
REGEXP_EXTRACT_ALLinstead ofr'[a-z]{2,20}\'?[a-z]*'you should user'[a-z]{2,20}\'?[a-z]+'– Kordofanian