I am creating a deep convolutional neural network for pixel-wise classification. I am using adam optimizer, softmax with cross entropy.
I asked a similar question found here but the answer I was given did not result in me solving the problem. I also have a more detailed graph of what it going wrong. Whenever I use softmax, the problem in the graph occurs. I have done many things such as adjusting training and epsilon rates, trying different optimizers, etc. The loss never decreases past 500. I do not shuffle my data at the moment. Using sigmoid in place of softmax results in this problem not occurring. However, my problem has multiple classes, so the accuracy of sigmoid is not very good. It should also be mentioned that when the loss is low, my accuracy is only about 80%, I need much better than this. Why would my loss suddenly spike like this?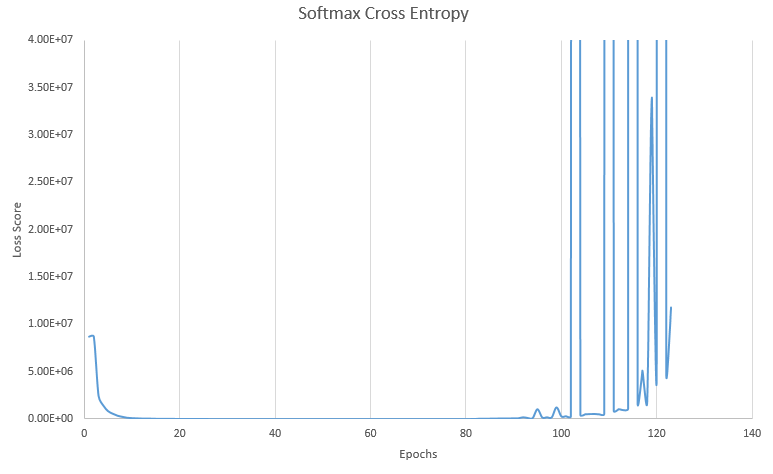
x = tf.placeholder(tf.float32, shape=[None, 7168])
y_ = tf.placeholder(tf.float32, shape=[None, 7168, 3])
#Many Convolutions and Relus omitted
final = tf.reshape(final, [-1, 7168])
keep_prob = tf.placeholder(tf.float32)
W_final = weight_variable([7168,7168,3])
b_final = bias_variable([7168,3])
final_conv = tf.tensordot(final, W_final, axes=[[1], [1]]) + b_final
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=final_conv))
train_step = tf.train.AdamOptimizer(1e-5).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(final_conv, 2), tf.argmax(y_, 2))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.add... Is this true ?? – Dowdytf.clipfor clipping the gradients... experiment with those deconv layers... – Dowdy