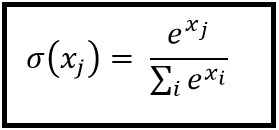I am attempting to replicate an deep convolution neural network from a research paper. I have implemented the architecture, but after 10 epochs, my cross entropy loss suddenly increases to infinity. This can be seen in the chart below. You can ignore what happens to the accuracy after the problem occurs.
Here is the github repository with a picture of the architecture
After doing some research I think using an AdamOptimizer or relu might be a problem.
x = tf.placeholder(tf.float32, shape=[None, 7168])
y_ = tf.placeholder(tf.float32, shape=[None, 7168, 3])
#Many Convolutions and Relus omitted
final = tf.reshape(final, [-1, 7168])
keep_prob = tf.placeholder(tf.float32)
W_final = weight_variable([7168,7168,3])
b_final = bias_variable([7168,3])
final_conv = tf.tensordot(final, W_final, axes=[[1], [1]]) + b_final
cross_entropy = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=final_conv))
train_step = tf.train.AdamOptimizer(1e-5).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(final_conv, 2), tf.argmax(y_, 2))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
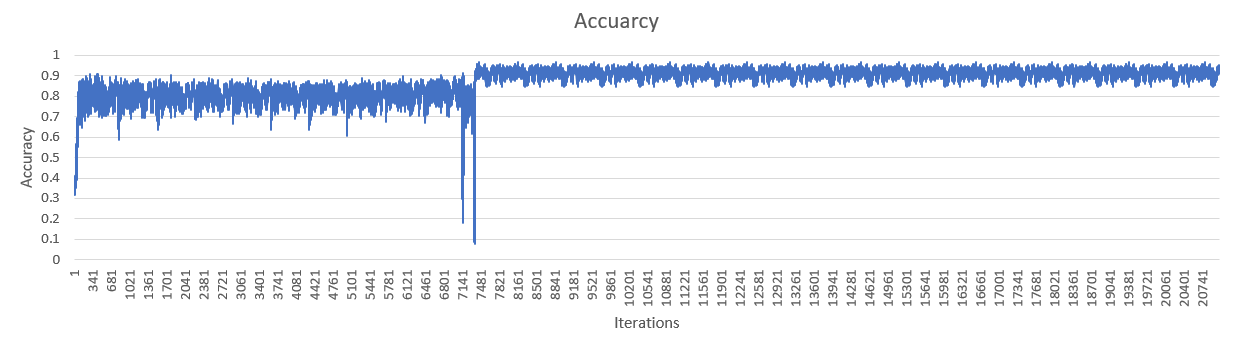
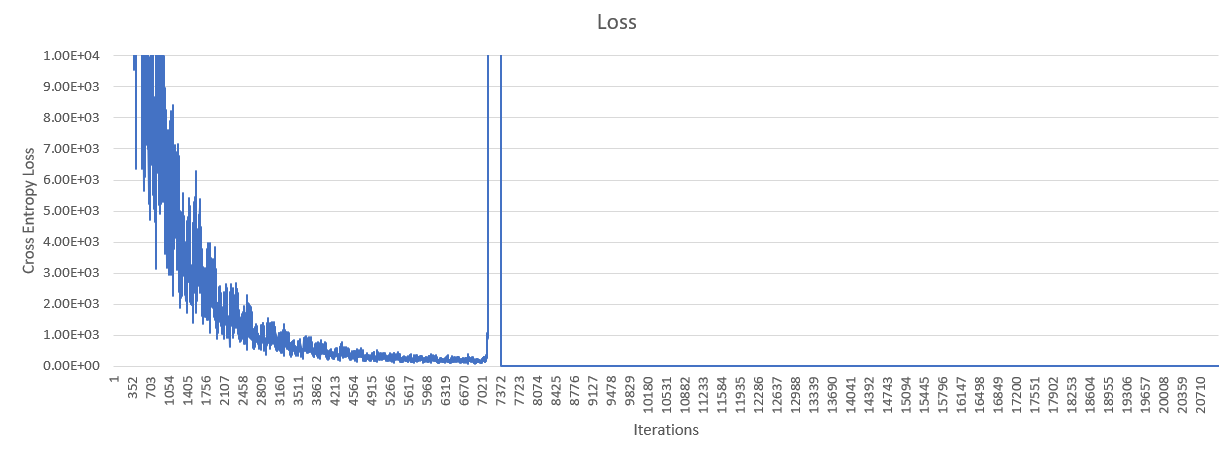
EDIT If anyone is interested, the solution was that I was basically feeding in incorrect data.