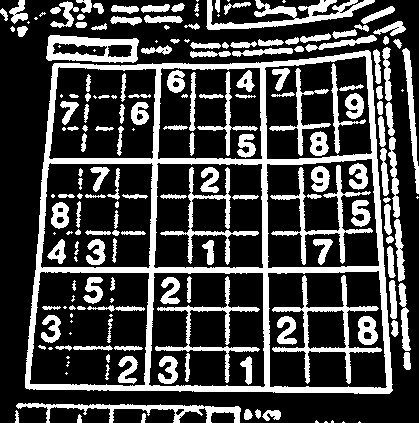
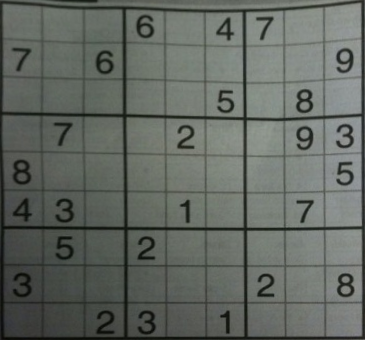
Here is my solution that will generalize to any image whether it is warped or not.
- Convert the image to grayscale
- Apply adaptive thresholding to convert the image to binary
(Adaptive thresholding works better than normal thresholding because the original image can have different lighting at different areas)
- Identify the Corners of the large square
- Perspective transform of the image to the final square image
Depending on the amount of skewness of the original image the corners identified may be out of order, do we need to arrange them in the correct order. the method used here is to identify the centroid of the large square and identify the order of the corners from there
Here is the code:
import cv2
import numpy as np
# Helper functions for getting square image
def euclidian_distance(point1, point2):
# Calcuates the euclidian distance between the point1 and point2
#used to calculate the length of the four sides of the square
distance = np.sqrt((point1[0] - point2[0]) ** 2 + (point1[1] - point2[1]) ** 2)
return distance
def order_corner_points(corners):
# The points obtained from contours may not be in order because of the skewness of the image, or
# because of the camera angle. This function returns a list of corners in the right order
sort_corners = [(corner[0][0], corner[0][1]) for corner in corners]
sort_corners = [list(ele) for ele in sort_corners]
x, y = [], []
for i in range(len(sort_corners[:])):
x.append(sort_corners[i][0])
y.append(sort_corners[i][1])
centroid = [sum(x) / len(x), sum(y) / len(y)]
for _, item in enumerate(sort_corners):
if item[0] < centroid[0]:
if item[1] < centroid[1]:
top_left = item
else:
bottom_left = item
elif item[0] > centroid[0]:
if item[1] < centroid[1]:
top_right = item
else:
bottom_right = item
ordered_corners = [top_left, top_right, bottom_right, bottom_left]
return np.array(ordered_corners, dtype="float32")
def image_preprocessing(image, corners):
# This function undertakes all the preprocessing of the image and return
ordered_corners = order_corner_points(corners)
print("ordered corners: ", ordered_corners)
top_left, top_right, bottom_right, bottom_left = ordered_corners
# Determine the widths and heights ( Top and bottom ) of the image and find the max of them for transform
width1 = euclidian_distance(bottom_right, bottom_left)
width2 = euclidian_distance(top_right, top_left)
height1 = euclidian_distance(top_right, bottom_right)
height2 = euclidian_distance(top_left, bottom_right)
width = max(int(width1), int(width2))
height = max(int(height1), int(height2))
# To find the matrix for warp perspective function we need dimensions and matrix parameters
dimensions = np.array([[0, 0], [width, 0], [width, width],
[0, width]], dtype="float32")
matrix = cv2.getPerspectiveTransform(ordered_corners, dimensions)
# Return the transformed image
transformed_image = cv2.warpPerspective(image, matrix, (width, width))
#Now, chances are, you may want to return your image into a specific size. If not, you may ignore the following line
transformed_image = cv2.resize(transformed_image, (252, 252), interpolation=cv2.INTER_AREA)
return transformed_image
# main function
def get_square_box_from_image(image):
# This function returns the top-down view of the puzzle in grayscale.
#
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
blur = cv2.medianBlur(gray, 3)
adaptive_threshold = cv2.adaptiveThreshold(blur, 255, cv2.ADAPTIVE_THRESH_MEAN_C, cv2.THRESH_BINARY_INV, 11, 3)
corners = cv2.findContours(adaptive_threshold, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
corners = corners[0] if len(corners) == 2 else corners[1]
corners = sorted(corners, key=cv2.contourArea, reverse=True)
for corner in corners:
length = cv2.arcLength(corner, True)
approx = cv2.approxPolyDP(corner, 0.015 * length, True)
print(approx)
puzzle_image = image_preprocessing(image, approx)
break
return puzzle_image
# Call the get_square_box_from_image method on any sudoku image to get the top view of the puzzle
original = cv2.imread("large_puzzle.jpg")
sudoku = get_square_box_from_image(original)
Here are the results from the given image and a custom example
![Given image of the puzzle and transformed image]()
![custom example and the transformed image]()