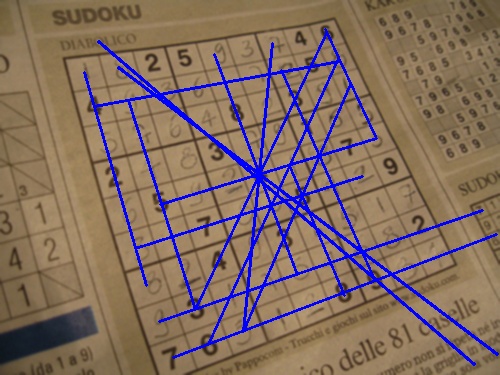
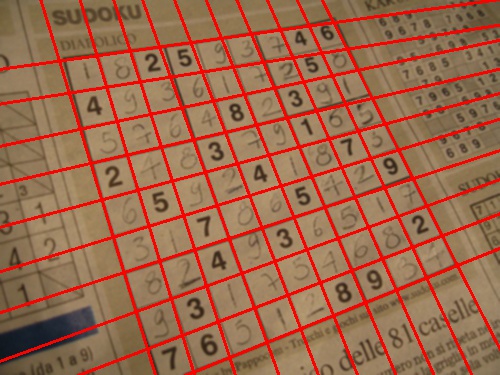
Hough transform is definitely the way to go. In fact grid detection is one of the most popular example when introducing this tehcnique (see here and here).
I suggest the following steps:
- downsample
- blur
- apply Canny (you should have a good guess what the min/max possible length of a grid line from the used perspective)
- dilate the edge image (canny finds both border of a separator in the grid as different edges, dilation will make these merge again)
- erode (now we have too thick borders, hough would find too many lines)
- apply HoughLines
- merge the similar lines
At the last step you have many possible ways to go and it strongly depends on what you want to do with the results afterwards. For example you could create a new edge image with the found images and apply erosion and hough again, you could use something Fourier-based, or you could just simply filter the lines by some arbitrary threshold values (just to mention a few). I implemented the last one (since conceptually that is the easiest one to do), here is what i did (although i am not at all sure whether this is the best approach or not):
- defined an arbitrary threshold for the rho and theta values
- checked how many times an edge is in these thresholds of another one
- starting from the most similar one I started dropping out lines that are similar to it (this way we will keep the line that is in some sense the 'middle' one among a similar group)
- the remaining lines are the final candidates
See code, have fun:
import cv2
import numpy as np
filter = False
file_path = ''
img = cv2.imread(file_path)
gray = cv2.cvtColor(img,cv2.COLOR_BGR2GRAY)
edges = cv2.Canny(gray,90,150,apertureSize = 3)
kernel = np.ones((3,3),np.uint8)
edges = cv2.dilate(edges,kernel,iterations = 1)
kernel = np.ones((5,5),np.uint8)
edges = cv2.erode(edges,kernel,iterations = 1)
cv2.imwrite('canny.jpg',edges)
lines = cv2.HoughLines(edges,1,np.pi/180,150)
if not lines.any():
print('No lines were found')
exit()
if filter:
rho_threshold = 15
theta_threshold = 0.1
# how many lines are similar to a given one
similar_lines = {i : [] for i in range(len(lines))}
for i in range(len(lines)):
for j in range(len(lines)):
if i == j:
continue
rho_i,theta_i = lines[i][0]
rho_j,theta_j = lines[j][0]
if abs(rho_i - rho_j) < rho_threshold and abs(theta_i - theta_j) < theta_threshold:
similar_lines[i].append(j)
# ordering the INDECES of the lines by how many are similar to them
indices = [i for i in range(len(lines))]
indices.sort(key=lambda x : len(similar_lines[x]))
# line flags is the base for the filtering
line_flags = len(lines)*[True]
for i in range(len(lines) - 1):
if not line_flags[indices[i]]: # if we already disregarded the ith element in the ordered list then we don't care (we will not delete anything based on it and we will never reconsider using this line again)
continue
for j in range(i + 1, len(lines)): # we are only considering those elements that had less similar line
if not line_flags[indices[j]]: # and only if we have not disregarded them already
continue
rho_i,theta_i = lines[indices[i]][0]
rho_j,theta_j = lines[indices[j]][0]
if abs(rho_i - rho_j) < rho_threshold and abs(theta_i - theta_j) < theta_threshold:
line_flags[indices[j]] = False # if it is similar and have not been disregarded yet then drop it now
print('number of Hough lines:', len(lines))
filtered_lines = []
if filter:
for i in range(len(lines)): # filtering
if line_flags[i]:
filtered_lines.append(lines[i])
print('Number of filtered lines:', len(filtered_lines))
else:
filtered_lines = lines
for line in filtered_lines:
rho,theta = line[0]
a = np.cos(theta)
b = np.sin(theta)
x0 = a*rho
y0 = b*rho
x1 = int(x0 + 1000*(-b))
y1 = int(y0 + 1000*(a))
x2 = int(x0 - 1000*(-b))
y2 = int(y0 - 1000*(a))
cv2.line(img,(x1,y1),(x2,y2),(0,0,255),2)
cv2.imwrite('hough.jpg',img)
![Result]()