Here I will explain a few things: what Copy-on-Write (CoW) is and how it consumes the memory, why setting 'vm.overcommit_memory = 1' won't help the memory usage and performance issue, and best practices of backing up Redis data.
Copy-on-Write and its memory usage
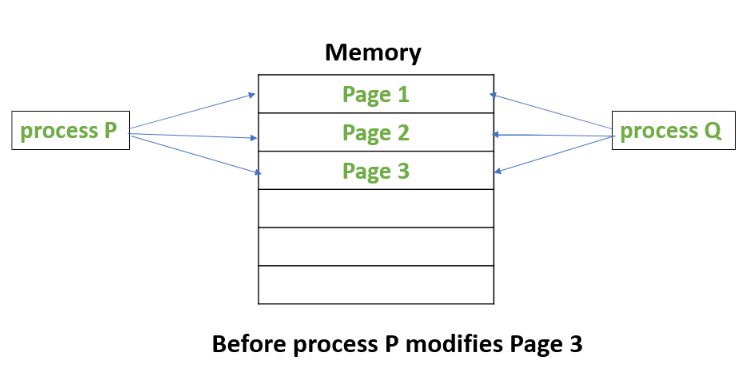
Redis' snapshot backup leverage the CoW semantics, which is provided by modern operating system to resolve the issue that when forking processes, the memory of the parent process is copied to the child process thus doubles the memory footprint. In CoW, the forked child process will share the original memory space of the parent process. It only copies the memory page when either process modifies that memory page. Here is an illustration of the memory space before data modification and after data modification:
![When the child process Q is forked, it shares the exact memory space as the parent process P]()
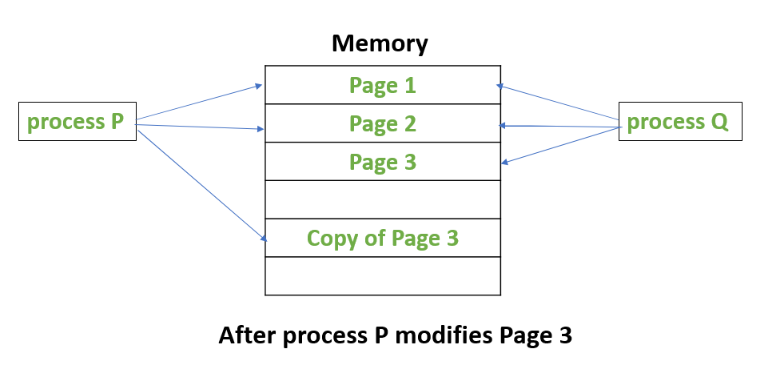
![When the parent process P modified memory page 3, it made a copy of it, instead of modifying the original page]() When the Redis' RDB backup is on-going, there will be data changes happening in the parent process, which is accepting new requests from clients and handling it in the memory. If the QPS is high, the parent process will copy tons of memory pages for the new changes during the child process' backup time. Thus the parent process will consume extra memory. In extreme cases, if all of the memory pages are modified, the memory footprint of the Redis instance will be doubled. Yeah, there is a possibility that the memory is doubled, and this fact will explain why Redis provides the "overcommit_memory=1" option, and what problem it can resolve, what it cannot (reducing the memory usage).
When the Redis' RDB backup is on-going, there will be data changes happening in the parent process, which is accepting new requests from clients and handling it in the memory. If the QPS is high, the parent process will copy tons of memory pages for the new changes during the child process' backup time. Thus the parent process will consume extra memory. In extreme cases, if all of the memory pages are modified, the memory footprint of the Redis instance will be doubled. Yeah, there is a possibility that the memory is doubled, and this fact will explain why Redis provides the "overcommit_memory=1" option, and what problem it can resolve, what it cannot (reducing the memory usage).
What "vm.overcommit_memory = 1" is, and what issues it resolves
During the RDB backup, you may see such log error:
10202:M 13 Sep 11:34:16.535 # Can't save in background: fork: Cannot allocate memory
It indicates there is not enough memory to fork the child process to do the backup. If the Redis process consumes 2GB memory now, when forking the child process, operating system will assume you have ANOTHER 2GB memory, so that in extreme cases of CoW, there is sufficient memory to copy all dirty memory pages. Even the extra memory is not used yet when forking the child process, it checks the idle memory to avoid later out-of-memory errors. In the Redis log, it provides the solution:
10202:M 13 Sep 11:33:09.943 # WARNING overcommit_memory is set to 0! Background
save may fail under low memory condition. To fix this issue add
'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the
command 'sysctl vm.overcommit_memory=1' for this to take effect.
So setting 'vm.overcommit_memory = 1' will allow you to fork the child process when the idle memory is low. If you know the dirty memory pages during the backup process won't be too many, there won't be any actual problems because the memory will be allocated successfully every time a new CoW operation happens.
And, 'vm.overcommit_memory = 1' only guarantees that you can fork the child process to backup the Redis data, but it cannot reduce the memory usage if there are writing operations happening all the time in the parent process.
Redis backup practice
There are three ways of persisting the Redis memory data: RDB(snapshotting), AOF, and the hybrid of the two. Any approach will impact the server response time to some extent no matter how you config the settings. To minimize the impact of the persisting process, we normally run the backup in slave instance instead on the master instance. However, there is a new risk if we do it on a slave. When there is network partitions happening, the slave may not be able to keep up-to-date, so backing up on a slave will risk losing some data. One resolution is to have multiple slaves, so the chance of having all of them out-of-sync with the master instance is lowered. Another prevention is setting up robust monitoring system, so we can detect network issues sooner and reduce the time span of the network partition.
vm.overcommit_memory = 1? – Indicia