I would like to know what copy-on-write is and what it is used for. The term is mentioned several times in the Sun JDK tutorials.
What is copy-on-write?
I was going to write up my own explanation but this Wikipedia article pretty much sums it up.
Here is the basic concept:
Copy-on-write (sometimes referred to as "COW") is an optimization strategy used in computer programming. The fundamental idea is that if multiple callers ask for resources which are initially indistinguishable, you can give them pointers to the same resource. This function can be maintained until a caller tries to modify its "copy" of the resource, at which point a true private copy is created to prevent the changes becoming visible to everyone else. All of this happens transparently to the callers. The primary advantage is that if a caller never makes any modifications, no private copy need ever be created.
Also here is an application of a common use of COW:
The COW concept is also used in maintenance of instant snapshot on database servers like Microsoft SQL Server 2005. Instant snapshots preserve a static view of a database by storing a pre-modification copy of data when underlaying data are updated. Instant snapshots are used for testing uses or moment-dependent reports and should not be used to replace backups.
anything a regular array is used for... however, in some situations, this type of strategy results in more optimized results. –
Azpurua
@hhafez: Linux uses it when it uses
clone() to implement fork() - the parent process's memory is COWed for the child. –
Delius @Dromond Some filesystems use CoW, e.g., BTRFS. –
Lewls
Is this how SandboxIE works? when a sandboxed program wants to overwrite something sandboxie intercepts the file system operation and copies the file to the sandbox folder and lets the program write to the sandboxed file instead of the original. Is that called Copy on write? –
Ivied
How does the merge happens eventually ? If there are N copies, which one is kept eventually to save on say disk? –
Theoretical
we don't know how to open wiki pages and read definitions(no pun intended!). –
Teenateenage
flawless answer! COW is used in docker as well. –
Increment
"Copy on write" means more or less what it sounds like: everyone has a single shared copy of the same data until it's written, and then a copy is made. Usually, copy-on-write is used to resolve concurrency sorts of problems. In ZFS, for example, data blocks on disk are allocated copy-on-write; as long as there are no changes, you keep the original blocks; a change changed only the affected blocks. This means the minimum number of new blocks are allocated.
These changes are also usually implemented to be transactional, ie, they have the ACID properties. This eliminates some concurrency issues, because then you're guaranteed that all updates are atomic.
If you do a change, how does the other get notified of your new copy? Wouldn't they see the wrong data. –
Palmate
@Palmate - No they wouldn't see the wrong data because when you make a change that's when a copy is actually made. For example you have a block of data called
A. Process 1, 2, 3, 4 each want to make a copy of it and start reading it, in a "Copy on write" system nothing is copied yet everything is still reading A. Now process 3 wants to make a change to it's copy of A, process 3 will now actually make a copy of A and create a new block of data called B. Process 1, 2, 4 are still reading block A process 3 is now reading B. –
Jamesjamesian @Jamesjamesian what will happen if changes are made in 'A'. All the processes will be reading the updated information or old? –
Glengarry
@Developer: Well whichever process is making a change to
A should be creating a new copy. If you are asking what happens if an entirely new process comes along and changes A then my explanation doesn't really go into enough detail for that. That would be implementation specific and require knowledge about how you want the rest of the implementation to work, such as file\data locking, etc. –
Jamesjamesian @Palmate your explanation is better than the accepted answer! –
Coonhound
How can you have a shared copy of the same data? How does that translate in programming terms, because I don't get it. You have a copy and someone else has a copy and someone has a copy. 3 Copies - ie. they cannot be shared. UNLESS you meant that you can have a shared pointer to the data - that's not a shared copy of the data. So the way I understand this is many have a shared pointer to the data and when that data is written a "copy" is made, basically no copy is made since it's a pointer, it's data the data is reflected at the same time. –
Zip
I shall not repeat the same answer on Copy-on-Write. I think Andrew's answer and Charlie's answer have already made it very clear. I will give you an example from OS world, just to mention how widely this concept is used.
We can use fork() or vfork() to create a new process. vfork follows the concept of copy-on-write. For example, the child process created by vfork will share the data and code segment with the parent process. This speeds up the forking time. It is expected to use vfork if you are performing exec followed by vfork. So vfork will create the child process which will share data and code segment with its parent but when we call exec, it will load up the image of a new executable in the address space of the child process.
"vfork follows the concept of copy-on-write". Please consider changing this line.
vfork does NOT use COW. In fact if the child writes something, it can result in undefined behavior and not copying of pages!! In fact, you can say the other way round is somewhat true. COW acts like vfork till something is modified in the shared space! –
Diacaustic Completely agree with Pavan. Remove the lines "vfork follows the concept of copy-on-write" . Now a days, COW is used in fork as an optimization, so that it acts like vfork and do not make a copy of parent's data for child process (if we calls only exec* in child) –
Kite
Just to provide another example, Mercurial uses copy-on-write to make cloning local repositories a really "cheap" operation.
The principle is the same as the other examples, except that you're talking about physical files instead of objects in memory. Initially, a clone is not a duplicate but a hard link to the original. As you change files in the clone, copies are written to represent the new version.
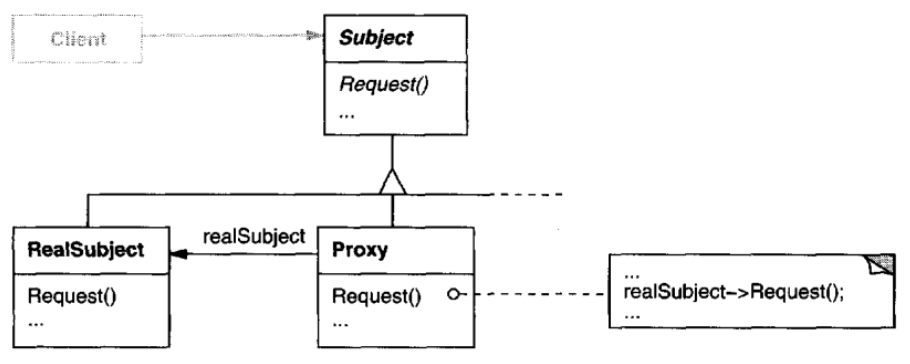
The book Design Patterns: Elements of Reusable Object-Oriented Software by Erich Gamma et al. clearly describes the copy-on-write optimization (section ‘Consequences’, chapter ‘Proxy’):
The Proxy pattern introduces a level of indirection when accessing an object. The additional indirection has many uses, depending on the kind of proxy:
- A remote proxy can hide the fact that an object resides in a different address space.
- A virtual proxy can perform optimizations such as creating an object on demand.
- Both protection proxies and smart references allow additional housekeeping tasks when an object is accessed.
There’s another optimization that the Proxy pattern can hide from the client. It’s called copy-on-write, and it’s related to creation on demand. Copying a large and complicated object can be an expensive operation. If the copy is never modified, then there’s no need to incur this cost. By using a proxy to postpone the copying process, we ensure that we pay the price of copying the object only if it’s modified.
To make copy-on-write work, the subject must be referenced counted. Copying the proxy will do nothing more than increment this reference count. Only when the client requests an operation that modifies the subject does the proxy actually copy it. In that case the proxy must also decrement the subject’s reference count. When the reference count goes to zero, the subject gets deleted.
Copy-on-write can reduce the cost of copying heavyweight subjects significantly.
Here after is a Python implementation of the copy-on-write optimization using the Proxy pattern. The intent of this design pattern is to provide a surrogate for another object to control access to it.
Class diagram of the Proxy pattern:
Object diagram of the Proxy pattern:

First we define the interface of the subject:
import abc
class Subject(abc.ABC):
@abc.abstractmethod
def clone(self):
raise NotImplementedError
@abc.abstractmethod
def read(self):
raise NotImplementedError
@abc.abstractmethod
def write(self, data):
raise NotImplementedError
Next we define the real subject implementing the subject interface:
import copy
class RealSubject(Subject):
def __init__(self, data):
self.data = data
def clone(self):
return copy.deepcopy(self)
def read(self):
return self.data
def write(self, data):
self.data = data
Finally we define the proxy implementing the subject interface and referencing the real subject:
class Proxy(Subject):
def __init__(self, subject):
self.subject = subject
try:
self.subject.counter += 1
except AttributeError:
self.subject.counter = 1
def clone(self):
return Proxy(self.subject) # attribute sharing (shallow copy)
def read(self):
return self.subject.read()
def write(self, data):
if self.subject.counter > 1:
self.subject.counter -= 1
self.subject = self.subject.clone() # attribute copying (deep copy)
self.subject.counter = 1
self.subject.write(data)
The client can then benefit from the copy-on-write optimization by using the proxy as a stand-in for the real subject:
if __name__ == '__main__':
x = Proxy(RealSubject('foo'))
x.write('bar')
y = x.clone() # the real subject is shared instead of being copied
print(x.read(), y.read()) # bar bar
assert x.subject is y.subject
x.write('baz') # the real subject is copied on write because it was shared
print(x.read(), y.read()) # baz bar
assert x.subject is not y.subject
I found this good article about zval in PHP, which mentioned COW too:
Copy On Write (abbreviated as ‘COW’) is a trick designed to save memory. It is used more generally in software engineering. It means that PHP will copy the memory (or allocate new memory region) when you write to a symbol, if this one was already pointing to a zval.
A good example is Git, which uses a strategy to store blobs. Why does it use hashes? Partly because these are easier to perform diffs on, but also because makes it simpler to optimise a COW strategy. When you make a new commit with few files changes the vast majority of objects and trees will not change. Therefore the commit, will through various pointers made of hashes reference a bunch of object that already exist, making the storage space required to store the entire history much smaller.
It is a memory protection concept. In this compiler creates extra copy to modify data in child and this updated data not reflect in parents data.
It's also used in Ruby 'Enterprise Edition' as a neat way of saving memory.
I don't think he meant "used for" in that sense. –
Mean
© 2022 - 2024 — McMap. All rights reserved.