I believe you are talking about x86-64, my answer is based on that architecture.
When operating in 64-bit mode the CPU uses a revamped feature to translate virtual addresses into physical addresses known as PAE - Physical address extension.
Originally invented to break the 4GiB limit while still using 32-bit pointers, this feature involves the use of 4 level of tables.
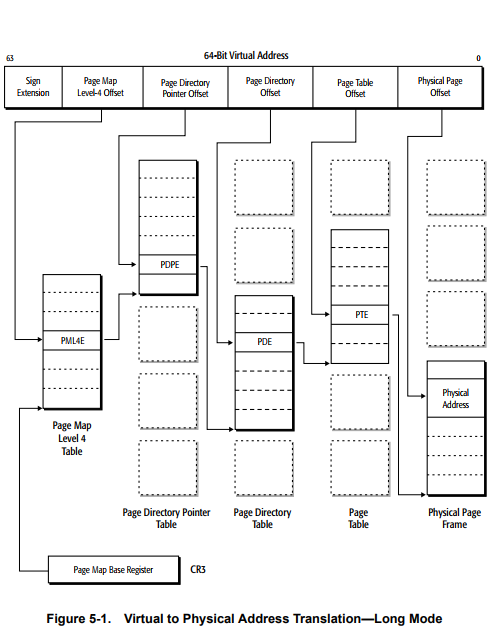
Each table gives a pointer to the next table, down to the rightmost one that gives the upper bits of physical address. To get an idea look at this picture from the AMD64 Architecture Programming Manual:
![4-Level paging, PAE, in long mode]()
The rationale behind all those tables is sparsity: the metadata for translating virtual addresses into physical addresses is huge - if we were to use 4KiB pages only we'd need 264 - 12 = 252 entries to cover the whole 64-bit address space.
Tables allow for a sparse approach, only the entries necessary are populated in memory.
This design is reflected in how the virtual address is divided (and thus, indirectly, in the number of levels), only runs of 9 bits are used to index the tables at each level.
Starting from bit 12 included, this gives: level 1 -> 12-20, level 2 -> 21-29, level 3 -> 30-38, level 4 -> 39-47.
This explains the current implementation limit of only 48 bits of virtual address space.
Note that at the instruction level, where logical addresses are used, we have full support for 64 bits addresses.
Full support is also available at the segmentation level, the part that translates logical addresses into linear addresses.
So the limitation comes from PAE.
My personal opinion is that AMD rushed to be the first to ship an x86 CPU with 64-bit support and reused PAE, patching it with a new level of indirection to translate up to 48 bits.
Note that both Intel and AMD allow a future implementation to use 64 bits for the virtual address (probably with more tables).
However, both companies set a hard limit of 52 bit for the physical address.
Why?
The answer can still be found in how paging work.
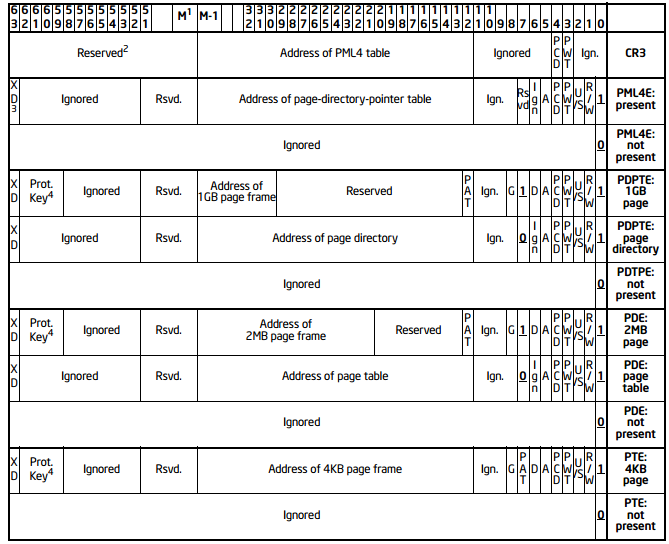
In 32-bit mode, each entry in each table is 32 bits wide; the low bits are used as flags (since the alignment requirements make them useless for the translation process) but the higher bits were all used for the translation, giving a 32/32 virtual/physical translation.
It's important to stress out that all the 32 bits were used, while some of the lower bits were not used as flags, Intel marked them as "Ignored" or "Available" meaning with that that the OS was free to use them.
When Intel introduced PAE, they needed 4 more bits (PAE was 36 bits back then) and the logical thing to do was to double the size of each entry since this creates a more efficient layout than a, say, 40-bit table entry.
This gave Intel a lot of spare space and they marked it as reserved (This can be better observed in older versions of the Intel SDM manuals, like this one).
With time, new attributes were needed in an entry, the most famous one being the XD/NX bit.
Protection keys are also a, relatively new, feature that takes space in an entry.
This shows that a full 64/64 bits virtual/physical translation is not possible anymore with the current ISA.
For a visual reference, here is the format of the 64-bit PAE table entries:
![Intel 64-bit PAE table entries]()
It shows that a 64-bit physical address is not possible (for huge pages there still is a way to fix this but given the layout of the bits that seems unlikely) but doesn't explain why AMD set the limit to 52 bits.
Well, it's hard to say.
Certainly, the size of the physical address space has some hardware cost associated with it: more pins (though with the integrated memory controller, this is mitigated as the DDR specs multiplex a lot of signals) and more space in the caches/TLBs.
In this question (similar but not enough make this a duplicate) an answer cities Wikipedia, that in turn allegedly cites AMD, claiming that AMD's engineers set the limit to 52 bits after due considerations of benefits and costs.
I share what Hans Passant wrote more than 6 years ago: the current paging mechanisms are not suitable for a full 64-bit physical addressing and that's probably the reason why both Intel and AMD never bothered keeping the high bits in each entry reserved.
Both companies know that as the technology will approach the 52-bit limit it will also be very different from its current form.
By that time they will have designed a better mechanism for memory in general, so they avoided over-engineering the existing one.
shl rax,16/sar rax,16before using to redo the sign extension. (Or better, have your program only allocate tagged pointers in the low half of the canonical range, so you can just useandor BMI2andnto make addresses canonical.) Or even better, allocate only in the low 4G of virtual address space, so you can use address-size (0x67) prefixes to ignore high garbage, or use 32-bit operand size when manipulating pointers to zero-extend them for free. – Febrifacientmmap(MAP_48BIT)flag equivalent to the currentmmap(MAP_32BIT)so programs that want to use the high 16 for their own purposes can keep doing so. Using only the high byte might be safer for longer, since extending virtual far beyond physical is less likely, even with memory-mapped non-volatile storage becoming a thing. (e.g. faster-than-flash on DIMMs.) – Febrifacient