I have measured the body heights of all my children. When I plot all heights along an axis of lengths, this is what the result looks like:

Every red (boys) or violet (girls) tick is one child. If two children have the same body height (in millimetres), the ticks get stacked. Currently there are seven children with the same body height. (The height and width of the ticks is meaningless. They have been scaled to be visible.)
As you can see, the different heights are not evenly distributed along the axis, but cluster around certain values.
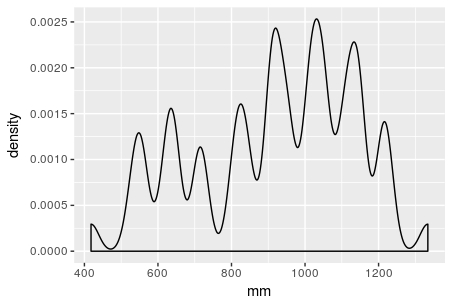
A histrogram and density plot of the data looks like this (with the two density estimates plotted following this answer):

As you can see, this is a multimodal distribution.
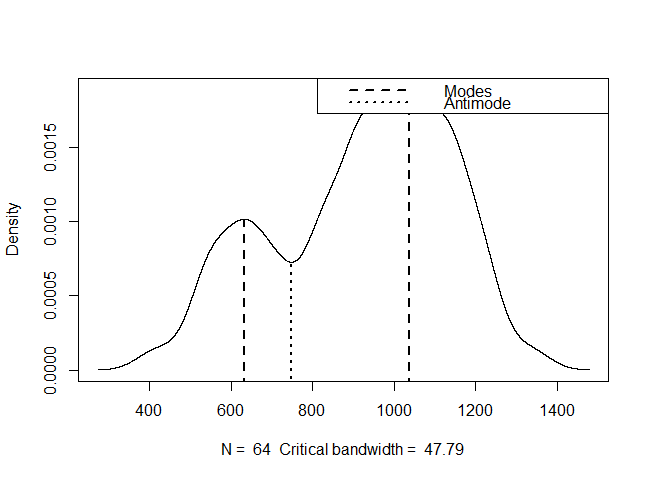
How do I calculate the modes (in R)?
Here is the raw data for you to play with:
mm <- c(418, 527, 540, 553, 554, 558, 613, 630, 634, 636, 645, 648, 708, 714, 715, 725, 806, 807, 822, 823, 836, 837, 855, 903, 908, 910, 911, 913, 915, 923, 935, 945, 955, 957, 958, 1003, 1006, 1015, 1021, 1021, 1022, 1034, 1043, 1048, 1051, 1054, 1058, 1100, 1102, 1103, 1117, 1125, 1134, 1138, 1145, 1146, 1150, 1152, 1210, 1211, 1213, 1223, 1226, 1334)

set.seed(6); hist(rnorm(64))), and a procedure to "find the modes" is ill-defined as there are many ways this could be done... – Hoptoad