I am working on a project for building a high precision word alignment between sentences and their translations in other languages, for measuring translation quality. I am aware of Giza++ and other word alignment tools that are used as part of the pipeline for Statistical Machine Translation, but this is not what I'm looking for. I'm looking for an algorithm that can map words from the source sentence into the corresponding words in the target sentence, transparently and accurately given these restrictions:
- the two languages do not have the same word order, and the order keeps changing
- some words in the source sentence do not have corresponding words in the target sentence, and vice versa
- sometimes a word in the source correspond to multiple words in the target, and vice versa, and there can be many-to-many mapping
- there can be sentences where the same word is used multiple times in the sentence, so the alignment needs to be done with the words and their indexes, not only words
Here is what I did:
- Start with a list of sentence pairs, say English-German, with each sentence tokenized to words
- Index all words in each sentence, and create an inverted index for each word (e.g. the word "world" occurred in sentences # 5, 16, 19, 26 ... etc), for both source and target words
- Now this inverted index can predict the correlation between any source word and any target word, as the intersection between the two words divided by their union. For example, if the tagret word "Welt" occurs in sentences 5, 16, 26,32, The correlation between (world, Welt) is the number of indexes in the intersection (3) divided by the number of indexes in the union (5), and hence the correlation is 0.6. Using the union gives lower correlation with high frequency words, such as "the", and the corresponding words in other languages
- Iterate over all sentence pairs again, and use the indexes for the source and target words for a given sentence pairs to create a correlation matrix
Here is an example of a correlation matrix between an English and a German sentence. We can see the challenges discussed above.
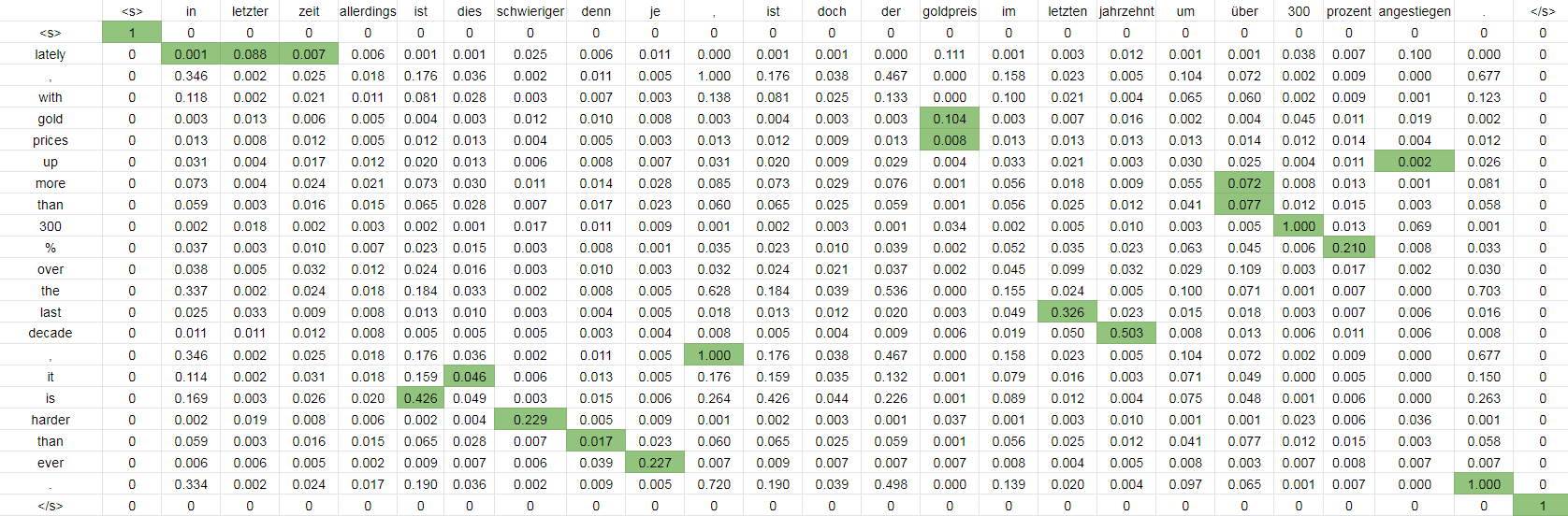
In the image, there is an example of the alignment between an English and German sentence, showing the correlations between words, and the green cells are the correct alignment points that should be identified by the word-alignment algorithm.
Here is some of what I tried:
- It is possible in some cases that the intended alignment is simply the word pair with the highest correlation in its respective column and row, but in many cases it's not.
- I have tried things like Dijkstra's algorithm to draw a path connecting the alignment points, but it doesn't seem to work this way, because it seems you can jump back and forth to earlier words in the sentence because of the word order, and there is no sensible way to skip words for which there is no alignment.
- I think the optimum solution will involve something like expanding rectangles which start from the most likely correspondences, and span many-to-many correspondences, and skip words with no alignment, but I'm not exactly sure what would be a good way to implement this
Here is the code I am using:
import random
src_words=["I","know","this"]
trg_words=["Ich","kenne","das"]
def match_indexes(word1,word2):
return random.random() #adjust this to get the actual correlation value
all_pairs_vals=[] #list for all the source (src) and taget (trg) indexes and the corresponding correlation values
for i in range(len(src_words)): #iterate over src indexes
src_word=src_words[i] #identify the correponding src word
for j in range(len(trg_words)): #iterate over trg indexes
trg_word=trg_words[j] #identify the correponding trg word
val=match_indexes(src_word,trg_word) #get the matching value from the inverted indexes of each word (or from the data provided in the speadsheet)
all_pairs_vals.append((i,j,val)) #add the sentence indexes for scr and trg, and the corresponding val
all_pairs_vals.sort(key=lambda x:-x[-1]) #sort the list in descending order, to get the pairs with the highest correlation first
selected_alignments=[]
used_i,used_j=[],[] #exclude the used rows and column indexes
for i0,j0,val0 in all_pairs_vals:
if i0 in used_i: continue #if the current column index i0 has been used before, exclude current pair-value
if j0 in used_j: continue #same if the current row was used before
selected_alignments.append((i0,j0)) #otherwise, add the current pair to the final alignment point selection
used_i.append(i0) #and include it in the used row and column indexes so that it will not be used again
used_j.append(j0)
for a in all_pairs_vals: #list all pairs and indicate which ones were selected
i0,j0,val0=a
if (i0,j0) in selected_alignments: print(a, "<<<<")
else: print(a)
It's problematic because it doesn't accomodate the many-to-many, or even the one to many alignments, and can err easily in the beginning by selecting a wrong pair with highest correlation, excluding its row and column from future selection. A good algorithm would factor in that a certain pair has the highest correlation in its respective row/column, but would also consider the proximity to other pairs with high correlations.
Here is some data to try if you like, it's in Google sheets: https://docs.google.com/spreadsheets/d/1-eO47RH6SLwtYxnYygow1mvbqwMWVqSoAhW64aZrubo/edit?usp=sharing
