I have a similar open question here on Cross Validated (though not implementation focused, which I intend this question to be, so I think they are both valid).
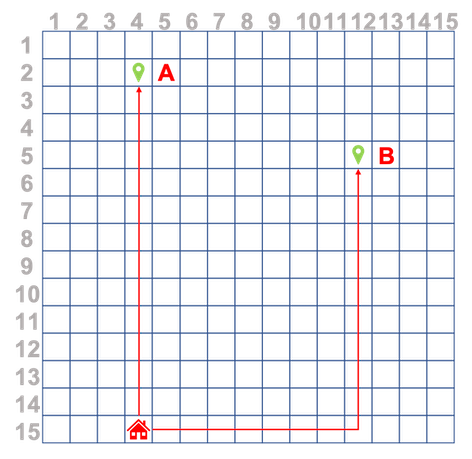
I'm working on a project that uses sensors to monitor a persons GPS location. The coordinates will then be converted to a simple-grid representation. What I want to try and do is after recording a users routes, train a neural network to predict the next coordinates, i.e. take the example below where a user repeats only two routes over time, Home->A and Home->B.
I want to train an RNN/LSTM with sequences of varying lengths e.g. (14,3), (13,3), (12,3), (11,3), (10,3), (9,3), (8,3), (7,3), (6,3), (5,3), (4,3), (3,3), (2,3), (1,3) and then also predict with sequences of varying lengths e.g. for this example route if I called
route = [(14,3), (13,3), (12,3), (11,3), (10,3)] //pseudocode
pred = model.predict(route)
pred should give me (9,3) (or ideally even a longer prediction e.g. ((9,3), (8,3), (7,3), (6,3), (5,3), (4,3), (3,3), (2,3), (1,3))
How do I feed such training sequences to the init and forward operations identified below?
self.rnn = nn.RNN(input_size, hidden_dim, n_layers, batch_first=True)
out, hidden = self.rnn(x, hidden)
Also, should the entire route be a tensor or each set of coordinates within the route a tensor?