How do I plot (in python) the distance graph for a given value of min-points in DBSCAN???
I am looking for the knee and corresponding epsilon value.
In the sklearn I do not see any method that return such distances.... Am I missing something?
How do I plot (in python) the distance graph for a given value of min-points in DBSCAN???
I am looking for the knee and corresponding epsilon value.
In the sklearn I do not see any method that return such distances.... Am I missing something?
You probably want to use the matrix operations provided by numpy to speed up your distance matrix calculation.
def k_distances2(x, k):
dim0 = x.shape[0]
dim1 = x.shape[1]
p=-2*x.dot(x.T)+np.sum(x**2, axis=1).T+ np.repeat(np.sum(x**2, axis=1),dim0,axis=0).reshape(dim0,dim0)
p = np.sqrt(p)
p.sort(axis=1)
p=p[:,:k]
pm= p.flatten()
pm= np.sort(pm)
return p, pm
m, m2= k_distances2(X, 2)
plt.plot(m2)
plt.ylabel("k-distances")
plt.grid(True)
plt.show()
First you can define a function to calculate the distance of each point to its k-th nearest neighbor:
def calculate_kn_distance(X,k):
kn_distance = []
for i in range(len(X)):
eucl_dist = []
for j in range(len(X)):
eucl_dist.append(
math.sqrt(
((X[i,0] - X[j,0]) ** 2) +
((X[i,1] - X[j,1]) ** 2)))
eucl_dist.sort()
kn_distance.append(eucl_dist[k])
return kn_distance
Then, once you have defined your function, you can choose a k value and plot the histogram to find a knee to define an appropriate epsilon value.
eps_dist = calculate_kn_distance(X[1],4)
plt.hist(eps_dist,bins=30)
plt.ylabel('n');
plt.xlabel('Epsilon distance');
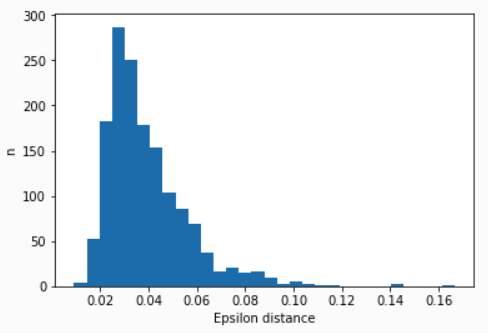
In the example above, a vast majority of points lie within 0.12 units from their 4th nearest neighbor. So, a heuristic approach, could be choosing 0.12 as epsilon parameter.
You probably want to use the matrix operations provided by numpy to speed up your distance matrix calculation.
def k_distances2(x, k):
dim0 = x.shape[0]
dim1 = x.shape[1]
p=-2*x.dot(x.T)+np.sum(x**2, axis=1).T+ np.repeat(np.sum(x**2, axis=1),dim0,axis=0).reshape(dim0,dim0)
p = np.sqrt(p)
p.sort(axis=1)
p=p[:,:k]
pm= p.flatten()
pm= np.sort(pm)
return p, pm
m, m2= k_distances2(X, 2)
plt.plot(m2)
plt.ylabel("k-distances")
plt.grid(True)
plt.show()
To get distances you could use this function:
import numpy as np
import pandas as pd
import math
def k_distances(X, n=None, dist_func=None):
"""Function to return array of k_distances.
X - DataFrame matrix with observations
n - number of neighbors that are included in returned distances (default number of attributes + 1)
dist_func - function to count distance between observations in X (default euclidean function)
"""
if type(X) is pd.DataFrame:
X = X.values
k=0
if n == None:
k=X.shape[1]+2
else:
k=n+1
if dist_func == None:
# euclidean distance square root of sum of squares of differences between attributes
dist_func = lambda x, y: math.sqrt(
np.sum(
np.power(x-y, np.repeat(2,x.size))
)
)
Distances = pd.DataFrame({
"i": [i//10 for i in range(0, len(X)*len(X))],
"j": [i%10 for i in range(0, len(X)*len(X))],
"d": [dist_func(x,y) for x in X for y in X]
})
return np.sort([g[1].iloc[k].d for g in iter(Distances.groupby(by="i"))])
X should be pandas.DataFrame or numpy.ndarray. n is number of neighbors that are in d-neighborhood. You should know this number. By default is number of attributes + 1.
To plot those distances you could use this code:
import matplotlib.pyplot as plt
d = k_distances(X,n,dist_func)
plt.plot(d)
plt.ylabel("k-distances")
plt.grid(True)
plt.show()
I'll try my best to do an extensive guide for future viewers
In a nutshell the steps are (using distance matrix)
Lets take a simple dataset with n = 7
x, y
1 1, 1
2 1.5, 1.5
3 1.25,1.25
4 1.5, 1
5 1, 1.5
6 1.75,1.75
7 3, 2
The sorted distance matrix
[[0, 0.353, 0.5, 0.5, 0.707, 1.061, 2.236]
[0, 0.353, 0.353, 0.5, 0.5, 0.707, 1.581]
[0, 0.353, 0.353, 0.353, 0.353, 0.707, 1.904]
[0, 0.353, 0.5, 0.5, 0.707, 0.791, 1.803]
[0, 0.353, 0.5, 0.5, 0.707, 0.791, 2.062]
[0, 0.353, 0.707, 0.791, 0.791, 1.061, 1.275]
[0, 1.273, 1.581, 1.803, 1.904, 2.062, 2.236]]
The sorted kth (k=4) Column (5th column)
[1.904,0.791,0.707,0.707,0.707,0.5,0.353]
Now plotting this will yield
plt.plot([0,1,2,3,4,5,6],[1.904,0.791,0.707,0.707,0.707,0.5,0.353])
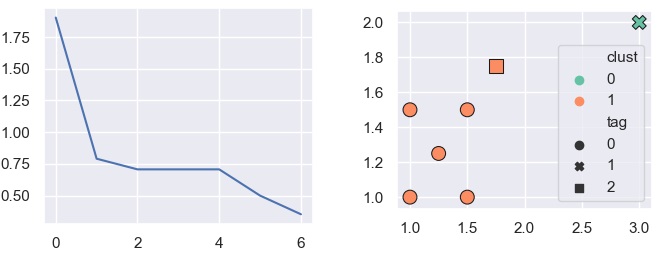
As you can see there is a strong bend at 0.79. So for k/minpts = 4, any point which have kth neighbour distance > 0.79 will be considered noise/non-core point.
Of course there's no guarantee that there will be a strong bend or even a bend at all in the graph it completely depends on the distribution of data
The original paper
© 2022 - 2024 — McMap. All rights reserved.