If using a third-party package would be okay then you could use iteration_utilities.unique_everseen:
>>> from iteration_utilities import unique_everseen
>>> l = [{'a': 123}, {'b': 123}, {'a': 123}]
>>> list(unique_everseen(l))
[{'a': 123}, {'b': 123}]
It preserves the order of the original list and ut can also handle unhashable items like dictionaries by falling back on a slower algorithm (O(n*m) where n are the elements in the original list and m the unique elements in the original list instead of O(n)). In case both keys and values are hashable you can use the key argument of that function to create hashable items for the "uniqueness-test" (so that it works in O(n)).
In the case of a dictionary (which compares independent of order) you need to map it to another data-structure that compares like that, for example frozenset:
>>> list(unique_everseen(l, key=lambda item: frozenset(item.items())))
[{'a': 123}, {'b': 123}]
Note that you shouldn't use a simple tuple approach (without sorting) because equal dictionaries don't necessarily have the same order (even in Python 3.7 where insertion order - not absolute order - is guaranteed):
>>> d1 = {1: 1, 9: 9}
>>> d2 = {9: 9, 1: 1}
>>> d1 == d2
True
>>> tuple(d1.items()) == tuple(d2.items())
False
And even sorting the tuple might not work if the keys aren't sortable:
>>> d3 = {1: 1, 'a': 'a'}
>>> tuple(sorted(d3.items()))
TypeError: '<' not supported between instances of 'str' and 'int'
Benchmark
I thought it might be useful to see how the performance of these approaches compares, so I did a small benchmark. The benchmark graphs are time vs. list-size based on a list containing no duplicates (that was chosen arbitrarily, the runtime doesn't change significantly if I add some or lots of duplicates). It's a log-log plot so the complete range is covered.
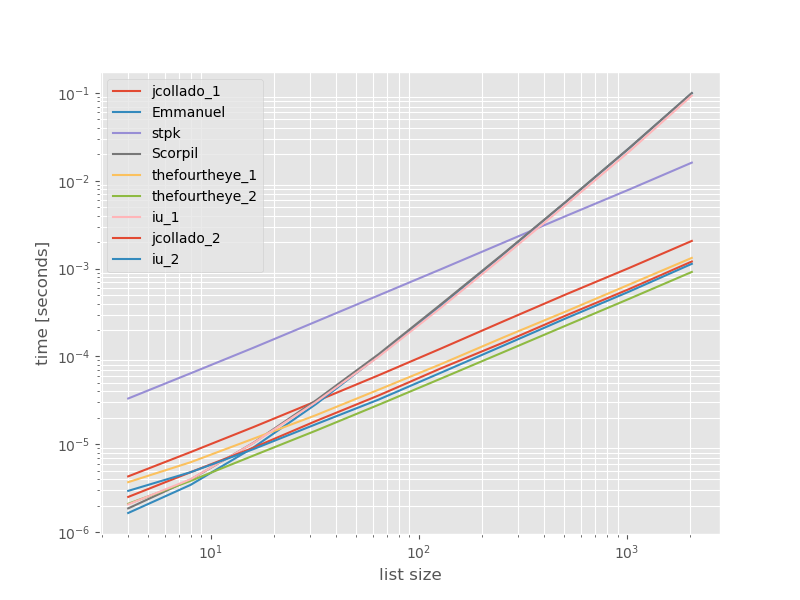
The absolute times:
![enter image description here]()
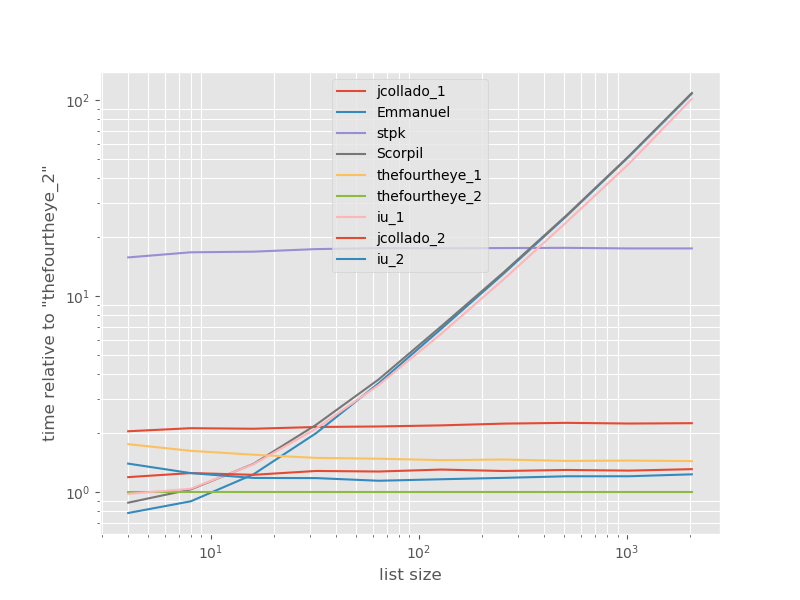
The timings relative to the fastest approach:
![enter image description here]()
The second approach from thefourtheye is fastest here. The unique_everseen approach with the key function is on the second place, however it's the fastest approach that preserves order. The other approaches from jcollado and thefourtheye are almost as fast. The approach using unique_everseen without key and the solutions from Emmanuel and Scorpil are very slow for longer lists and behave much worse O(n*n) instead of O(n). stpks approach with json isn't O(n*n) but it's much slower than the similar O(n) approaches.
The code to reproduce the benchmarks:
from simple_benchmark import benchmark
import json
from collections import OrderedDict
from iteration_utilities import unique_everseen
def jcollado_1(l):
return [dict(t) for t in {tuple(d.items()) for d in l}]
def jcollado_2(l):
seen = set()
new_l = []
for d in l:
t = tuple(d.items())
if t not in seen:
seen.add(t)
new_l.append(d)
return new_l
def Emmanuel(d):
return [i for n, i in enumerate(d) if i not in d[n + 1:]]
def Scorpil(a):
b = []
for i in range(0, len(a)):
if a[i] not in a[i+1:]:
b.append(a[i])
def stpk(X):
set_of_jsons = {json.dumps(d, sort_keys=True) for d in X}
return [json.loads(t) for t in set_of_jsons]
def thefourtheye_1(data):
return OrderedDict((frozenset(item.items()),item) for item in data).values()
def thefourtheye_2(data):
return {frozenset(item.items()):item for item in data}.values()
def iu_1(l):
return list(unique_everseen(l))
def iu_2(l):
return list(unique_everseen(l, key=lambda inner_dict: frozenset(inner_dict.items())))
funcs = (jcollado_1, Emmanuel, stpk, Scorpil, thefourtheye_1, thefourtheye_2, iu_1, jcollado_2, iu_2)
arguments = {2**i: [{'a': j} for j in range(2**i)] for i in range(2, 12)}
b = benchmark(funcs, arguments, 'list size')
%matplotlib widget
import matplotlib as mpl
import matplotlib.pyplot as plt
plt.style.use('ggplot')
mpl.rcParams['figure.figsize'] = '8, 6'
b.plot(relative_to=thefourtheye_2)
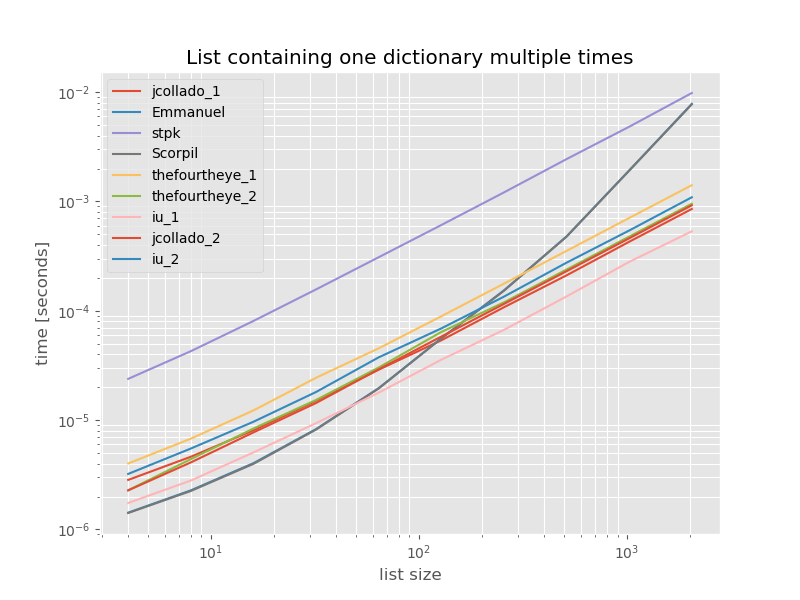
For completeness here is the timing for a list containing only duplicates:
# this is the only change for the benchmark
arguments = {2**i: [{'a': 1} for j in range(2**i)] for i in range(2, 12)}
![enter image description here]()
The timings don't change significantly except for unique_everseen without key function, which in this case is the fastest solution. However that's just the best case (so not representative) for that function with unhashable values because it's runtime depends on the amount of unique values in the list: O(n*m) which in this case is just 1 and thus it runs in O(n).
Disclaimer: I'm the author of iteration_utilities.
set()– Hallo