The gaussian_kde function in scipy.stats has a function evaluate that can returns the value of the PDF of an input point. I'm trying to use gaussian_kde to estimate the inverse CDF. The motivation is for generating Monte Carlo realizations of some input data whose statistical distribution is numerically estimated using KDE. Is there a method bound to gaussian_kde that serves this purpose?
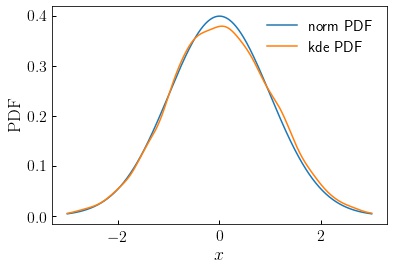
The example below shows how this should work for the case of a Gaussian distribution. First I show how to do the PDF calculation to set up the specific API I'm trying to achieve:
import numpy as np
from scipy.stats import norm, gaussian_kde
npts_kde = int(5e3)
n = np.random.normal(loc=0, scale=1, size=npts_kde)
kde = gaussian_kde(n)
npts_sample = int(1e3)
x = np.linspace(-3, 3, npts_sample)
kde_pdf = kde.evaluate(x)
norm_pdf = norm.pdf(x)
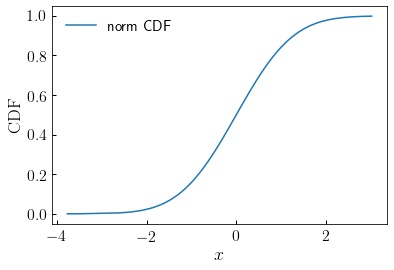
Is there an analogously simple way to compute the inverse CDF? The norm function has a very handy isf function that does exactly this:
cdf_value = np.sort(np.random.rand(npts_sample))
cdf_inv = norm.isf(1 - cdf_value)
Does such a function exist for kde_gaussian? Or is it straightforward to construct such a function from the already implemented methods?
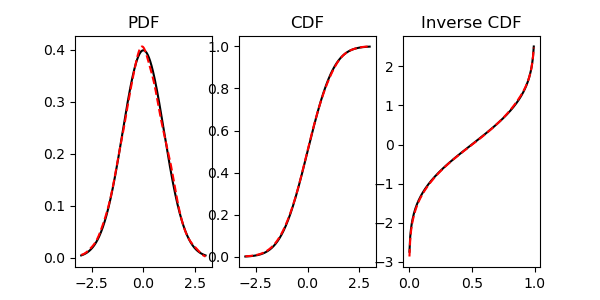
resamplemethod? – Tobaccoresamplemethod permitted me to pass in CDF values (the way that theisfmethod does), then my problem would be solved. Butresamplepresumes I want to use a random uniform to generate the sample via the inverse CDF, which I do not. – Charinilekdestuff, but theintegrate_box_1dmethod sounds like almost the cdf to me, Maybe you can even put-inffor a boundary? And the cdf you can invert using a root finder - not the fastest, obviously. – Tobaccointegrate_box_1d. So this will actually be quite fast. If you write this up as a suggested answer, that will very likely be the accepted answer. Otherwise I'll write it up after making the explanation explicit and clear. Either way, thanks for the tip! – Charinile