I am trying to train a CNN in pytorch,but I meet some problems. The RuntimeError:
RuntimeError: CUDA out of memory. Tried to allocate 512.00 MiB (GPU 0; 2.00 GiB total capacity; 584.97 MiB already allocated; 13.81 MiB free; 590.00 MiB reserved in total by PyTorch)
This is my code:
import os
import numpy as np
import cv2
import torch as t
import torch.nn as nn
import torchvision.transforms as transforms
from torch.utils.data import DataLoader,Dataset
import time
import matplotlib.pyplot as plt
%matplotlib inline
root_path='C:/Users/60960/Desktop/recet-task/course_LeeML20/course_LeeML20-datasets/hw3/food-11'
training_path=root_path+'/training'
testing_path=root_path+'/testing'
validation_path=root_path+'/validation'
def readfile(path,has_label):
img_paths=sorted(os.listdir(path))
x=np.zeros((len(img_paths),128,128,3),dtype=np.uint8)
y=np.zeros((len(img_paths)),dtype=np.uint8)
for i,file in enumerate(img_paths):
img=cv2.imread(path+'/'+file)
x[i,:,:]=cv2.resize(img,(128,128))
if has_label:
y[i]=int(file.split('_')[0])
if has_label:
return x,y
else:
return x
def show_img(img_from_cv2):
b,g,r=cv2.split(img_from_cv2)
img=cv2.merge([r,g,b])
plt.imshow(img)
plt.show()
x_train,y_train=readfile(training_path,True)
x_val,y_val=readfile(validation_path,True)
x_test=readfile(testing_path,False)
train_transform=transforms.Compose([
transforms.ToPILImage(),
transforms.RandomHorizontalFlip(),
transforms.RandomRotation(15),
transforms.ToTensor()
])
test_transform=transforms.Compose([
transforms.ToPILImage(),
transforms.ToTensor()
])
class ImgDataset(Dataset):
def __init__(self,x,y=None,transform=None):
self.x=x
self.y=y
if y is not None:
self.y=t.LongTensor(y)
self.transform=transform
def __len__(self):
return len(self.x)
def __getitem__(self,idx):
X=self.x[idx]
if self.transform is not None:
X=self.transform(X)
if self.y is not None:
Y=self.y[idx]
return X,Y
return X
batch_size=128
train_set=ImgDataset(x_train,y_train,transform=train_transform)
val_set=ImgDataset(x_val,y_val,transform=test_transform)
train_loader=DataLoader(train_set,batch_size=batch_size,shuffle=True)
val_loader=DataLoader(val_set,batch_size=batch_size,shuffle=False)
class Classifier(nn.Module):
def __init__(self):
super(Classifier,self).__init__()
self.cnn=nn.Sequential(
nn.Conv2d(3,64,3,1,1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(2,2,0),
nn.Conv2d(64,128,3,1,1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.MaxPool2d(2,2,0),
nn.Conv2d(128,256,3,1,1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.MaxPool2d(2,2,0),
nn.Conv2d(256,512,3,1,1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2,2,0),
nn.Conv2d(512,512,3,1,1),
nn.BatchNorm2d(512),
nn.ReLU(),
nn.MaxPool2d(2,2,0)
)
self.fc=nn.Sequential(
nn.Linear(512*4*4,1024),
nn.ReLU(),
nn.Linear(1024,512),
nn.ReLU(),
nn.Linear(512,11)
)
def forward(self,x):
out=self.cnn(x)
out=out.view(out.size()[0],-1)
return self.fc(out)
model=Classifier().cuda()
loss_fn=nn.CrossEntropyLoss()
optim=t.optim.Adam(model.parameters(),lr=0.001)
epochs=30
for epoch in range(epochs):
epoch_start_time=time.time()
train_acc=0.0
train_loss=0.0
val_acc=0.0
val_loss=0.0
model.train()
for i,data in enumerate(train_loader):
optim.zero_grad()
train_pred=model(data[0].cuda())
batch_loss=loss_fn(train_pred,data[1].cuda())
batch_loss.backward()
optim.step()
train_acc+=np.sum(np.argmax(train_pred.cpu().data.numpy(),axis=1)==data[1].numpy())
train_loss+=batch_loss.item()
model.eval()
with t.no_grad():
for i,data in enumerate(val_loader):
val_pred=model(data[0].cuda())
batch_loss=loss_fn(val_pred,data[1].cuda())
val_acc+=np.sum(np.argmax(val_pred.cpu().data.numpy(),axis=1)==data[1].numpy())
val_loss+=batch_loss.item()
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f | Val Acc: %3.6f loss: %3.6f' % (epoch + 1, epochs, time.time()-epoch_start_time,train_acc/train_set.__len__(), train_loss/train_set.__len__(), val_acc/val_set.__len__(), val_loss/val_set.__len__()))
x_train_val=np.concatenate((x_train,x_val),axis=0)
y_train_val=np.concatenate((y_train,y_val),axis=0)
train_val_set=ImgDataset(x_train_val,x_train_val,train_transform)
train_val_loader=DataLoader(train_val_set,batch_size=batch_size,shuffle=True)
model_final=Classifier().cuda()
loss_fn=nn.CrossEntropy()
optim=t.optim.Adam(model_final.parameters(),lr=0.001)
epochs=30
for epoch in range(epochs):
epoch_start_time=time.time()
train_acc=0.0
train_loss=0.0
model_final.train()
for i,data in enumerate(train_val_loader):
optim.zero_grad()
train_pred=model_final(data[0].cuda())
batch_loss=loss_fn(train_pred,data[1].cuda())
batch_loss.backward()
optim.step()
train_acc+=np.sum(np.argmax(train_pred.cpu().data.numpy(),axis=1)==data[1].numpy())
train_loss+=batch_loss.item()
print('[%03d/%03d] %2.2f sec(s) Train Acc: %3.6f Loss: %3.6f' % (epoch + 1, epochs, time.time()-epoch_start_time,train_acc/train_val_set.__len__(), train_loss/train_val_set.__len__()))
test_set=ImgDataset(x_test,transform=test_transform)
test_loader=DataLoader(test_set,batch_size=batch_size,shuffle=False)
model_final.eval()
prediction=[]
with t.no_grad():
for i,data in enumerate(test_loader):
test_pred=model_final(data.cuda())
test_label=np.argmax(test_pred.cpu().data.numpy(),axis=1)
for y in test_label:
prediction.append(y)
with open('predict.csv','w') as f:
f.write('Id,Category\n')
for i,y in enumerate(prediction):
f.write('{},{}\n,'.format(i,y))
Pytorch version is 1.4.0, opencv2 version is 4.2.0.
The training dataset are pictures like these:training set
{kind=link}
The error happens at this line:
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-1-770be67177f4> in <module>
119 for i,data in enumerate(train_loader):
120 optim.zero_grad()
--> 121 train_pred=model(data[0].cuda())
122 batch_loss=loss_fn(train_pred,data[1].cuda())
123 batch_loss.backward()
I have already installed:
some information.
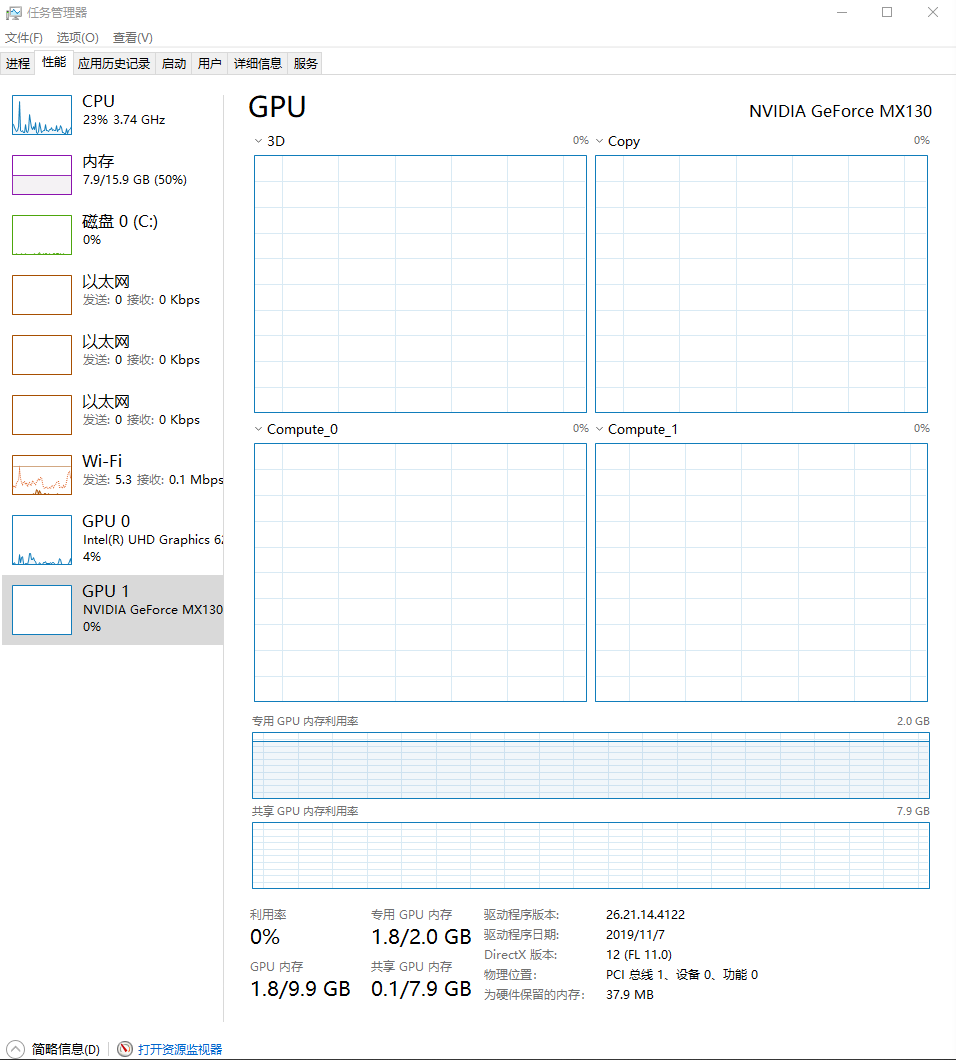
GPU utilization is low,close to zero:
GPU utilization.
Error message says:
{kind=link}
{kind=link}
RuntimeError: CUDA out of memory. Tried to allocate 512.00 MiB.
So I want to know how to allocate more memory.
What's more, I have tried to reduce the batch size to 1, but this doesn't work.
HELP!!!