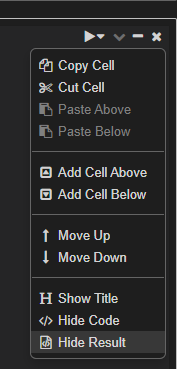
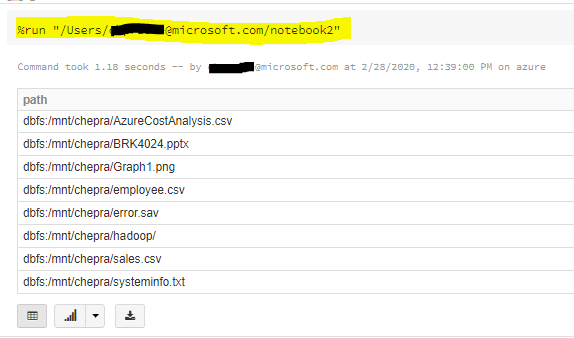
I am using multiple notebooks in PySpark and import variables across these notebooks using %run path. Every time I run the command, all variables that I displayed in the original notebook are being displayed again in the current notebook (the notebook in which I %run). But I do not want them to be displayed in the current notebook. I only want to be able to work with the imported variables. How do I suppress the output being display every time? Note, I am not sure if it matters, but I am working in DataBricks. Thank you!
Command example:
%run /Users/myemail/Nodebook