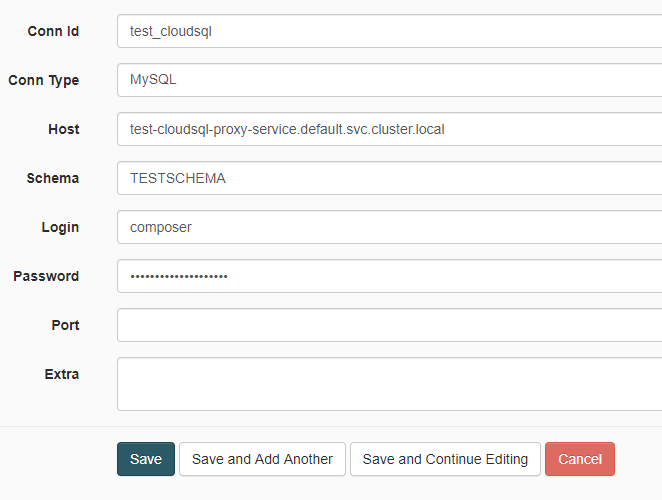
What ways do we have available to connect to a Google Cloud SQL (MySQL) instance from the newly introduced Google Cloud Composer? The intention is to get data from a Cloud SQL instance into BigQuery (perhaps with an intermediary step through Cloud Storage).
Can the Cloud SQL proxy be exposed in some way on pods part the Kubernetes cluster hosting Composer?
If not can the Cloud SQL Proxy be brought in by using the Kubernetes Service Broker? -> https://cloud.google.com/kubernetes-engine/docs/concepts/add-on/service-broker
Should Airflow be used to schedule and call GCP API commands like 1) export mysql table to cloud storage 2) read mysql export into bigquery?
Perhaps there are other methods that I am missing to get this done
{kind=link}