In order to clusterize a set of time series I'm looking for a smart distance metric. I've tried some well known metric but no one fits to my case.
ex: Let's assume that my cluster algorithm extracts this three centroids [s1, s2, s3]:
I want to put this new example [sx] in the most similar cluster:
The most similar centroids is the second one, so I need to find a distance function d that gives me d(sx, s2) < d(sx, s1) and d(sx, s2) < d(sx, s3)
edit
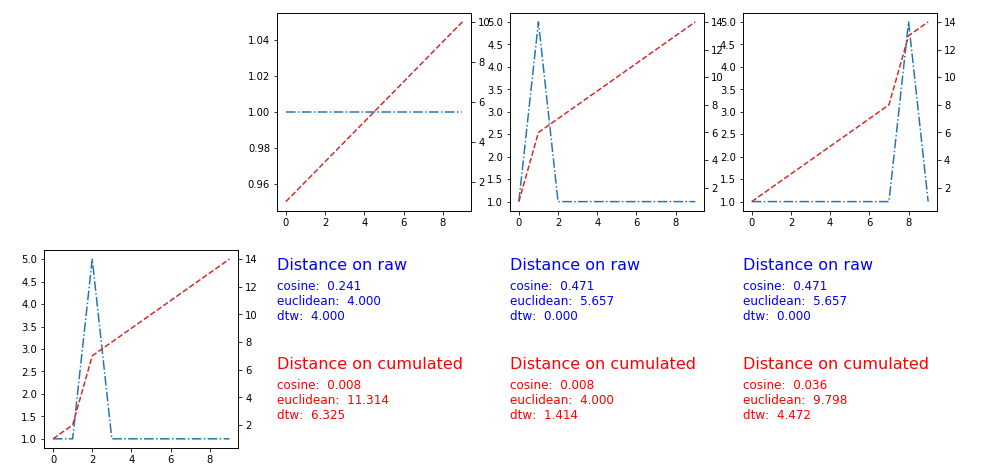
Here the results with metrics [cosine, euclidean, minkowski, dynamic type warping]
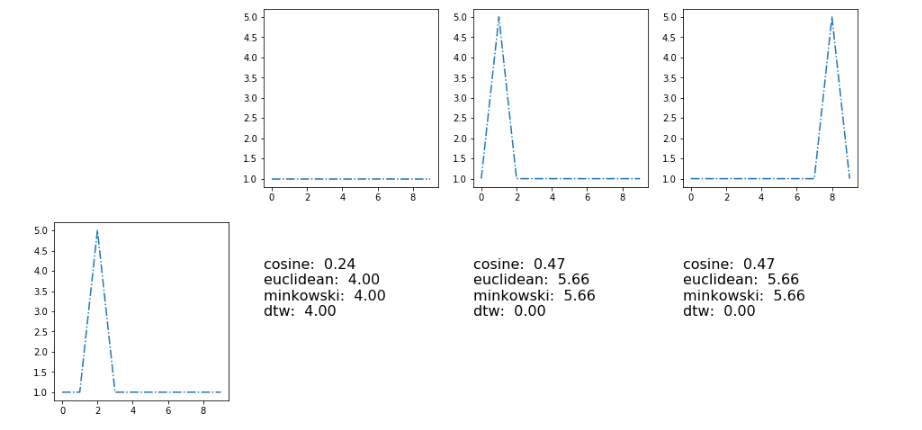 ]3
]3
edit 2
User Pietro P suggested to apply the distances on the cumulated version of the time series
The solution works, here the plots and the metrics: