For the sake of description, I provide a minimal reproduction of the following code:
#include <bits/stdc++.h>
#include <iostream>
#include <regex>
#include <string>
#include <string>
#include <Windows.h>
// GBK 转 UTF-8
std::string GBKToUTF8(const std::string& gbkStr) {
// 1. 先将 GBK 转换为宽字符(UTF-16)// Convert GBK to wide characters first (UTF-16)
int len = MultiByteToWideChar(CP_ACP, 0, gbkStr.c_str(), -1, nullptr, 0);
std::wstring wstr(len, 0);
MultiByteToWideChar(CP_ACP, 0, gbkStr.c_str(), -1, &wstr[0], len);
// 2. 将宽字符(UTF-16)转换为 UTF-8 // Convert wide characters (UTF-16) to UTF-8
len = WideCharToMultiByte(CP_UTF8, 0, wstr.c_str(), -1, nullptr, 0, nullptr, nullptr);
std::string utf8Str(len, 0);
WideCharToMultiByte(CP_UTF8, 0, wstr.c_str(), -1, &utf8Str[0], len, nullptr, nullptr);
return utf8Str;
}
int main() {
// 示例身份证号,长度为18 // Example ID number, length 18
std::string id_number = GBKToUTF8("610702199404261983");
// 检查字符串长度 // Check string length
std::cout << "Length before: " << id_number.length() << "\n"
<< id_number << std::endl;
// 正则表达式 // Regular expression
const std::regex id_number_pattern18("^([1-6][1-9]|50)\\d{4}(18|19|20)\\d{2}((0[1-9])|10|11|12)(([0-2][1-9])|10|20|30|31)\\d{3}[0-9Xx]$");
// 进行匹配 // Make a match
if (std::regex_match(id_number, id_number_pattern18)) {
std::cout << "Match successful!" << std::endl;
} else {
std::cout << "Match failed!" << std::endl;
}
return 0;
}
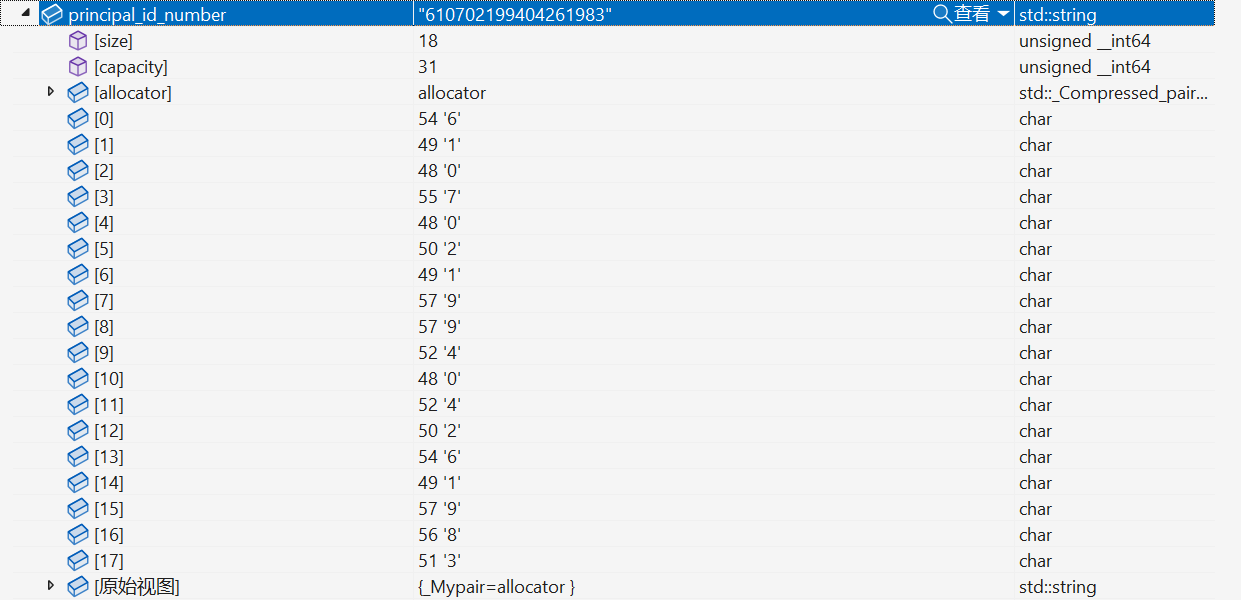
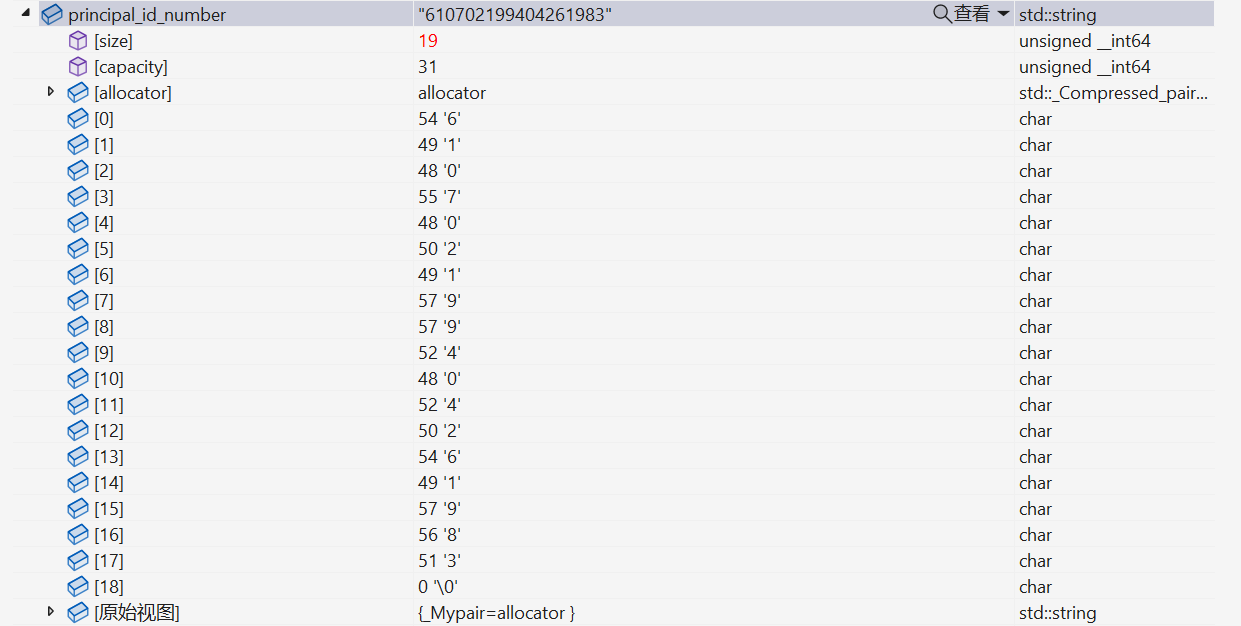
The problem now is that when the id_number string is transcoded into UTF-8, the length changes from 18 to 19. Also, the regex doesn't match the string correctly anymore (it can be matched properly if it is not transcoded).
I suspect that the string was transcoded and some invisible characters were added, but I don't know how to fix this.
Here are some screenshots of VS2022 (ISO C++17) debugging for reference (of course, the screenshots are not from the minimal reproduction code, but they should be well understood):
Before transcoding
After transcoding
I don't know how to do this at the moment, or I'd like to provide a solution and a description of how the problem arises.
std::string utf8Str(len - 1, 0);aslenseems to count final'\0'for C-string. – Thalwegstd::[w]stringand one in the controlled sequence. The solution is simple: Passsize()instead of-1as the length. That's also less costly. – Affrica#include <bits/stdc++.h>mixed in with includes of other Standard library headers suggests you may not know what#include <bits/stdc++.h>does. Here is a bit of reading on the subject along with reasons why you should avoid using that header. – Gerdescout << GBKToUTF8("").size()– Whitebait