I implemented a forecasting model using LSTM in Keras. The dataset is 15mints seperated and I am forecasting for 12 future steps.
The model performs good for the problem. But there is a small problem with the forecast made. It is showing a small shift effect. To get a more clear picture see the below attached figure.
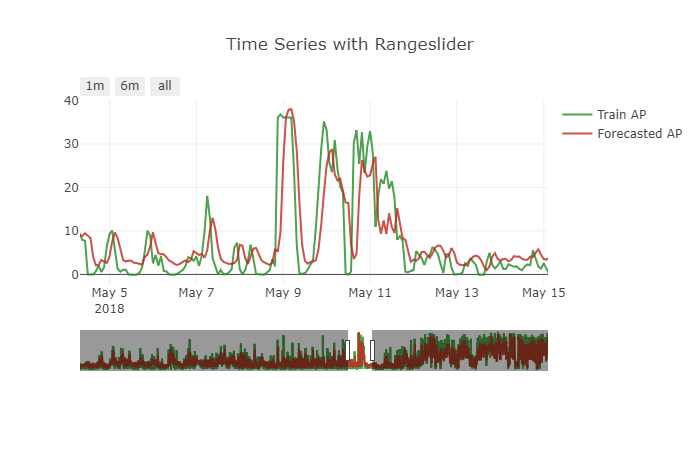
How to handle this problem.? How the data must be transformed to handle this kind of issue.?
The model I used is given below
init_lstm = RandomUniform(minval=-.05, maxval=.05)
init_dense_1 = RandomUniform(minval=-.03, maxval=.06)
model = Sequential()
model.add(LSTM(15, input_shape=(X.shape[1], X.shape[2]), kernel_initializer=init_lstm, recurrent_dropout=0.33))
model.add(Dense(1, kernel_initializer=init_dense_1, activation='linear'))
model.compile(loss='mae', optimizer=Adam(lr=1e-4))
history = model.fit(X, y, epochs=1000, batch_size=16, validation_data=(X_valid, y_valid), verbose=1, shuffle=False)
I made the forecasts like this
my_forecasts = model.predict(X_valid, batch_size=16)
Time series data is transformed to supervised to feed the LSTM using this function
# convert time series into supervised learning problem
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
super_data = series_to_supervised(data, 12, 1)
My timeseries is a multi-variate one. var2 is the one that I need to forecast. I dropped the future var1 like
del super_data['var1(t)']
Seperated train and valid like this
features = super_data[feat_names]
values = super_data[val_name]
ntest = 3444
train_feats, test_feats = features[0:-n_test], features[-n_test:]
train_vals, test_vals = values [0:-n_test], values [-n_test:]
X, y = train_feats.values, train_vals.values
X = X.reshape(X.shape[0], 1, X.shape[1])
X_valid, y_valid = test_feats .values, test_vals .values
X_valid = X_valid.reshape(X_valid.shape[0], 1, X_valid.shape[1])
I haven't made the data stationary for this forecast. I also tried taking difference and making the model as stationary as I can, but the issue remains the same.
I have also tried different scaling ranges for the min-max scaler, hoping it may help the model. But the forecasts are getting worsened.
Other Things I have tried
=> Tried other optimizers
=> Tried mse loss and custom log-mae loss functions
=> Tried varying batch_size
=> Tried adding more past timesteps
=> Tried training with sliding window and TimeSeriesSplit
I understand that the model is replicating the last known value to it, thereby minimizing the loss as good as it can
The validation and training loss remains low enough through out the training process. This makes me think whether I need to come up with a new loss function for this purpose.
Is that necessary.? If so what loss function should I go for.?
I have tried all the methods that I stumbled upon. I can't find any resource at all that points to this kind of issue. Is this the problem of data.? Is this because the problem is very hard to be learned by a LSTM .?