Note: This suggested solution is not only from the perspective of fast-reads (as requested by OP), but also with an eye toward minimizing indexing overhead. Nested documents and their parents are written as a single block, so the addition of each additional "message" in the nested proposal would cause all previous message and conversation data in that conversation to be reindexed as well.
Here's my guess about Facebook's general approach to implementing Messages (if you were to do something similar using Elasticsearch)
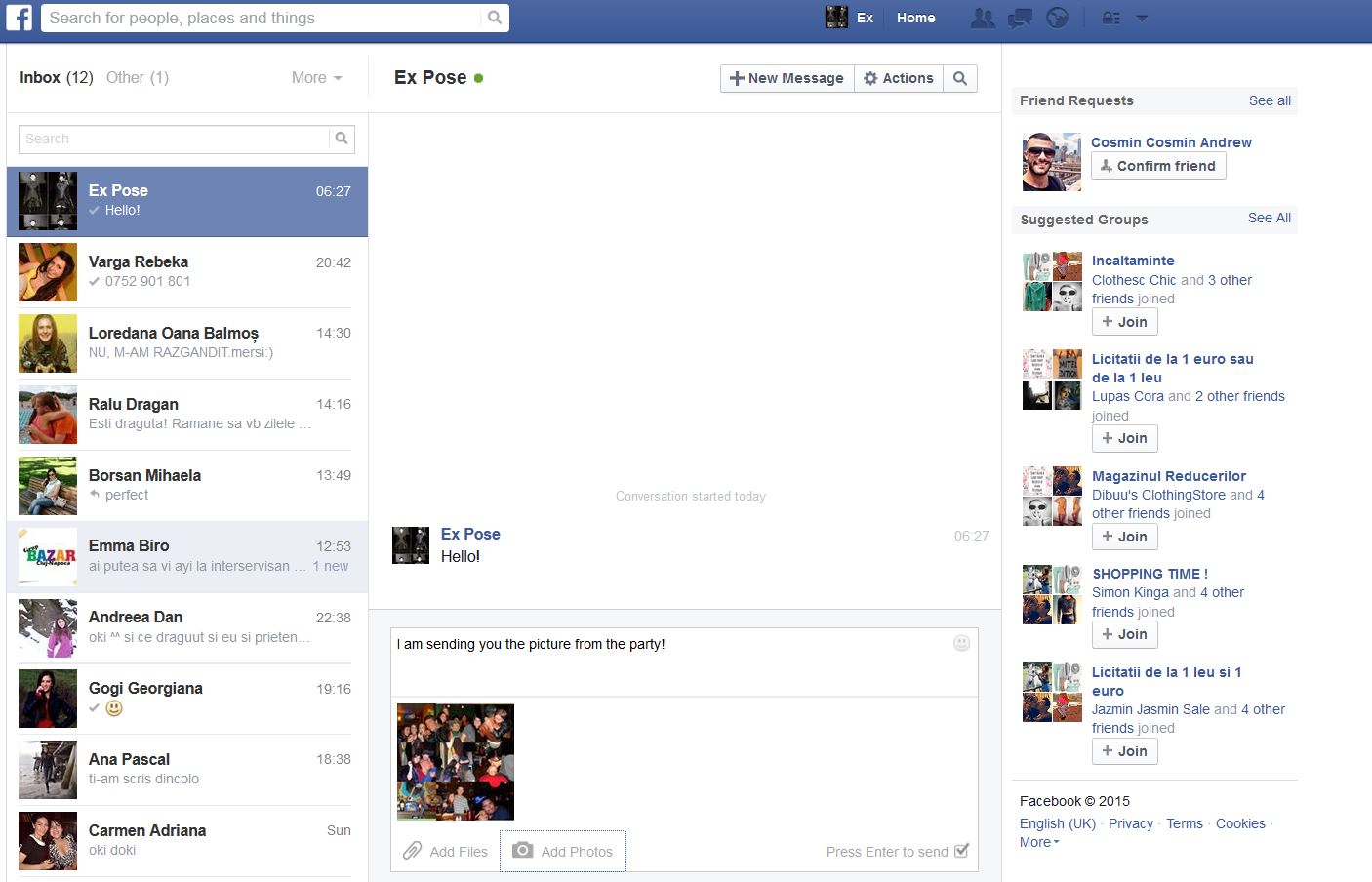
![enter image description here]()
Preview: (In Messages navbar dropdown, and on the left rail of the Messages page)
Shows a summary of the most recent conversations using:
- Composite headshots of the three most recent participants in the - Ordered list of most recent three conversation participants.
- Number of additional participants if > 3
- Timestamp of most recent message in the conversation
- Snippet of the latest message in the conversation
Message Pane: (Center column of the Messages page)
- Shows all the messages in a conversation
- The Message Pane also repurposed for Message Search results, showing all messages containing the searched term.
Search Box:
- Typeahead: (completes on conversations using matching participant names)
- Search: (searches on messages using matching text from message body)
The data structure driving the preview, would probably be in a conversation index (containing one document per conversation). These documents would be updated each time a message is added to a conversation. (Much like the parent record of your nested example doc).
This conversation data source is only used to draw the previews (fast filtering on conversation participants to ensure that you only see conversations you are a part of).
{
"ID" : 317,
"participant_ids": [123456789, 987654321],
"participant_names: ["John Doe", "Jane Doe"],
"last_message_snippet" : " Lorem ipsum dolor sit amet, consectetur adipiscing elit...",
"last_message_timestamp" : "timestamp of the last received message",
}
There would be no nesting here b/c only the up-to-date conversation summary is needed, not the message.
Performance would be fast, because no scoring need take place, just a filter on [current user] in participant_ids and a descending sort by last_message_timestamp.
You could replicate the typeahead functionality using the Elasticsearch Term Suggester on the participant_names field.
The lower-number of conversation documents (vs message documents) would help an index updated this frequently function well at scale.
To further scale this functionality, an Index Per Timeframe indexing strategy could be used (with the timeframe being determined by say, the typical half-life of a conversation, as an example).
When displaying the Messages within a particular conversation, you'd be querying a message index carrying your message document example, but with a reference to the conversation
{
"ID" : 4828274,
"conversation_id": 317,
"conversation_participant_ids": [123456789, 987654321],
"sender_id": 123456789,
"sender_name: "John Doe",
"message" : " Lorem ipsum dolor sit amet, consectetur adipiscing elit",
"message_timestamp" : <timestamp>,
}
Performance would be fast, because no scoring need take place, just a filter on conversation_id and a descending sort by message_timestamp.
When searching Messages across conversations, you'd only need to index the message field. (Following the Facebook implementation).
The the search query would be the search term filtered by [current user] in conversation_participant_ids with a descending sort by message_timestamp.
To minimize cross-talk in the search cluster when retrieving the messages for a conversation, you'd want to be sure to take advantage of Elasticsearch's routing parameter (on indexing requests) to explicitly co-locate all messages for a conversation on the same shard, using the conversation_id as the routing value when indexing new messages.
Note: Elasticsearch may turn out to be overkill for implementing a solution that could largely be built off of another document store or relational database with text-search functionality. By normalizing conversation and message in the above example, there is no longer any dependence on "nesting" in Elasticsearch.
Elasticsearch strengths for this implementation include efficient caching of filtered search results, fast autocomplete, and fast text search, but a weakness of Elasticsearch is the need for enough memory to comfortably accommodate all of the indexed data.
The performance characteristics of a Messaging application dictate that only the most recent messages are likely to be accessed or searched with any frequency, so at some point, if your application needs to scale, you should plan out a way to archive older, not-recently-accessed messages in "cold-storage" such that they require fewer application resources, but can still be "thawed" quickly enough to serve a keyword search without excessive latency.